Dcm4chee install windows 7
dcm4chee is a Java-based application for the management of digital clinical objects. As such, it should be run under the best hardware available for production systems. The minimal system configuration is as follows:
100 MB hard disk space (in addition to archive disk space for object storage and caching)
400 MHz CPU or better
dcm4chee requires a database to store transient and permanent information from the clinical workflow and objects. The authors of dcm4chee realize that database expertise varies from site to site, and has included support for several different databases for deployment with the archive. The list of supported databases is:
Additional Software Notes
dcm4chee is a Java-based application. It requires the installation of the JDK version 1.4.2 or higher. JDK version 5 is recommended for the best performance and stability.
For image compression/decompression, dcm4chee 2.8.x utilizes Sun’s Java Advanced Imaging (JAI) Image I/O Tools 1.0_01. The binary distribution packages of dcm4chee 2.8.x already includes the necessary JARs and native libraries for Windows and Linux i586. For Solaris support, you need to download the software package from Sun at http://java.sun.com/products/java-media/jai/downloads/download-iio-1_0_01.html and replace the Linux version of libclib_jiio.so in DCM4CHEE_DIST/bin/ with the file of the same name from the Solaris JAI Image IO distribution.
dcm4chee depends heavily on the JBoss ( http://www.jboss.org) application server for its infrastructure. It is not necessary to download JBoss (as dcm4chee is pre-packaged within JBoss), but viewing the online (or downloaded) JBoss documentation will assist a great deal in learning the dcm4chee directory structure, and how the product operates under the covers. JBoss services such as XMBeans, JBossMQ (JMS), and EJB (Session and Entity beans) are utilized by dcm4chee.
1.2. Installation Steps
Installing dcm4chee is fairly easy:
Download the binary distribution of dcm4chee for the database of your choice from the Files page of the dcm4che project page on SourceForge ( http://sourceforge.net/projects/dcm4che/). If you do not see a distribution for your database, you will have to build dcm4chee from the source code. See Appendix A, Building from Source Code for instructions on doing so.
Once downloaded, extract the distribution package into your desired destination directory. Avoid using a directory path that contains spaces though, as that may cause problems when running the application from the command line.
Install the database software of your choice (keeping in mind the supported database systems) if you have not already done so. Keep in mind that the database software that you install (or have installed) must match the version of dcm4chee that you downloaded. For example, if you want to use PostgreSQL with dcm4chee then you should download the dcm4chee-standalone-psql-2.8.2.zip file from SourceForge.
If using a database other than MySQL or PostgreSQL you will need to copy an apropriate JDBC Driver for the database to DCM4CHEE_DIST/server/default/lib/. This is not necessary for MySQL or PostgreSQL because the binary distribution of dcm4chee already contains the correct JDBC drivers for these database systems.
Verify that your database installation has TCP/IP socket access available.
For example, with PostgreSQL you can check the pg_hba.conf file for your database:
With Oracle, you can verify that the TNS Listener is enabled:
Initiate the archive database instance (named pacsdb) using the create DDL script located in DCM4CHEE_DIST/sql/create.xxx.
For example, with PostgreSQL on a Unix-based system:
To initialize a MySQL database on a Unix-based system:
Note : If you wish to take advantage of specific features of your RDBMS such as tablespaces, partitioning, etc. you will need to implement them on your own. This can sometimes be done with the tools that come with the database, or by modifying the DDL script before running it. If you make changes to the DDL script that you think might be useful to the wider audience, please submit them to the dcm4che-users listserv.
Adjust the dcm4chee database connection pool settings in DCM4CHEE_DIST/server/default/deploy/xxxx-ds.xml to suit your environment. This includes the user name and password that the application should use when obtaining connections. In addition, JBoss allows for the configuration of other aspects of the connection pool. Although the default settings are fine for basic deployment scenarios, the following may be added to the XML file in order to tune the connection pool:
Set the JAVA_HOME environment variable to your JDK installation directory.
Adjust the Java heap settings for the application
Keep in mind the available RAM and memory requirements of other processes running on the hardware. For example, iif only 512 MB RAM is available on the machine, you should decrease the default value from -Xmx512m (on Windows to) -Xmx300.
Optional: Upon installation, all DICOM services are pre-configured with DCM4CHEE as the Application Entity Title (AE Title, or AET). Although it is possible to modify this default configuration at a later date through the Web-based administrative console, it is more efficient to replace DCM4CHEE with YOUR_AET in DCM4CHEE_DIST/server/default/conf/xmdesc/*.xml using utilities provided by your platform.
For example, on GNU Linux:
> find DCM4CHEE_DIST/server/default/conf/xmdesc -exec \ sed -i s/DCM4CHEE_DIST/YOUR_AET/g ‘<>‘ ‘;’
You’re all done and ready to verify the installation.
After verifying that the application is installed and running correctly, you may want to install it as a Windows service or Unix daemon.
Stop the application (type ctrl-c in the console window).
Windows: install dcm4chee as a Windows service executing DCM4CHEE_DIST/bin/install_service.bat.
Redhat Linux: copy the init script DCM4CHEE_DIST/bin/dcm4chee_init_redhat.sh to /etc/init.d/ and adjust it according to the dcm4chee installation location, the JDK installation location, and which user the dcm4chee should run under.
1.3. Verify the Installation
Navigate to the DCM4CHEE_DIST/bin directory, and execute the run.bat or run.sh script, as appropriate for your operating system. Your output should look like the following and contain no error or exception messages:
Connect to the Web-based User Interface (default URL is http://localhost:8080/dcm4chee-web/) of the archive using any Web Browser (most tested are Mozilla Firefox and Microsoft Internet Explorer v6.x). You should get the User Login Screen. Login in using the default Administrator account admin, with password admin.
Connect to the JBoss JMX Console (default URL is http://localhost:8080/jmx-console/) and login in using the default Administrator account admin, with password admin.
Follow the link service=FileSystemMgt to the File System Management service configuration page under the dcm4chee.archive heading.
Invoke the operation addOnlineFileSystem(), with a directory path argument specifying where the archive shall store received objects/images.
Note: If no Storage File System is configured, the archive will auto-configure DCM4CHEE_DIST/server/default/archive as the Storage File System when the the first object/image is received.
Optional: In the default configuration, received images are stored ‘as is’ — meaning that no compression is performed. Lossless (or other types of) compression of received uncompressed images can be activated by the CompressionRules attribute in the Storage SCP Service ( service=StoreScp) configuration page. For example, set it to JLSL, to compress all types of images received from any Storage SCU with JPEG-LS Lossless codec.
Optional: The directory used for caching generated JPEG representations of archived images requested by Web Access to DICOM Persistent Objects (WADO) can be specified by the CacheRoot attribute in the the WADO Service ( service=WADOService) configuration page. Default: DCM4CHEE_DIST/server/default/wadocache.
The directory used for caching generated PDF representations of archived Structured Report Documents requested by IHE Retrieve Information for Display (RID) Services can be specified with the CacheRoot attribute in the RID Service ( service=RIDService) configuration page. Default: DCM4CHEE_DIST/server/default/ihe_rid_cache.
Send some objects/images to the archive’s Storage SCP, using the send utility of the dcm4che14 package, the dcm4che2 package, or another Storage SCU of your choice.
Refresh the Web Interface ( http://localhost:8080/dcm4chee-web/), which should now show the the list of received studies.
Expand a study row to show contained series. Expand one of these series to show contained instances. In the case of images, you can follow the image icon on the right to invoke an HTTP WADO request for a JPEG presentation of this image which will be displayed in a separate browser window.
To test object retrieval, you will need an external Storage SCP acting as the Destination using the DICOM Receiver utility of the dcm4che14 package, the dcm4che2 package, or another Storage SCP of your choice.
Before initiating the retrieve, you will need to configure an additional Application Entity (AE) Title identifying your Move Destination using the «AE Management» function of the Web User Interface. For example:
Switch back to the Study List (the Folder view) and mark studies to retrieve using the check box on the right. Select «DCMRCV» as the send destination in the combo box above and click on the send button left from it.
Alternatively, you could initiate a C-MOVE with the utility of your choice with DCMRCV as the destination AE Title.
If everything worked, you are ready to start using dcm4chee. If not, post your questions to the dcm4che-users listserv.
Dcm4chee install windows 7
The fastest way to setup your own DCM4CHEE PACS using PostgreSQL on Windows.
This script(dcm4chee-2.18.0-psql.iss) combines all the software needed to get dcm4chee up and running on Windows 7+. It automates the instructions below:
Includes Windows firewall configuration, automated database backup schedule(twice a day), auditing and browser viewers (weasis 2.0 and ioviyam) -DCM4CHEE version 2.18.0-postgresql -JDK 7.60+ -Postgresql 9.3.4
1- Make sure you delete existing dcm4chee installation.
2- Uninstall the existing postgresql database $ delete the folder under Program Files
1- Make sure your windows OS is installed on C drive. If not, please refer to compiling the project and edit the script file & generate the setup file according to your needs.
2- Download the release version DCM4CHEE-2.18.0-postgresql_x86_x64.exe & run the dcm4chee-postgresql.exe file $ Accept the risk and click yes.
3- Choose the Java development kit directory to be c:\dcm4chee\jdk(or whatever is set when compiling) otherwise it will not work.
4- Choose the postgresql directory to be c:\dcm4chee\db (or whatever is set when compiling)
5- Choose the postgresql data directory to be c:\dcm4chee\db\data(this is selected automatically once the postgre directory is selected in the previous step#4.
6- Set the password to be «1» without quotes (Only this password will work otherwise you will need to modify c:\dcm4chee\dcm4chee.2.18.0\server\default\deploy\pacs-postgres.xml file) IMPORTANT. The password is the crucial part of the installation process. Please remember the password as you will need it in the next step.
7 — Once prompted, enter the password «1» (This will be asked a few times(4) to create the databases(dcm4chee database and the auditing database) as well as the structure of the databases). IMPORTANT. When you type the password «1», it will look like nothing is happening (not typing the password(the cursor will not be moving as you type «1»)). Please make sure the prompted window is active by clicking on it first and press «1» only & press ENTER. It will prompt 4 times!
8- Uncheck the stackbuilder and finish the postgresql installation.
9- Finish the dcm4chee installation & restart your computer. Run the DMC4HCEE icon on your desktop & Click on archive then login as admin/admin
10- Go to start and type services and enter. Check to make sure DCM4HCEE sercice is up and running. If not right click and start the services
11- If you cannot see the services at all, navigate to c\dcm4chee\dcm4chee-2.18.0\bin\ & run install_service.bat as administrator then repeat the step #10.
Compiling the project with inno
2- Create a folder called dcm4chee-files under C drive.
3- Unzip the dcm4chee-files folder from git into dcm4chee-files folder
4- Download the following and place them into dcm4chee-files folder. You will need them in order to compile & run and install DCM4CHEE successfully:
Exes.zip(Extract & place the content of this file into dcm4chee-files folder. ) @ https://www.dropbox.com/s/57jqqmj9nh6cdev/exes.zip?dl=0
- DCM4CHEE2.18.0psql.exe(this includes jboss application integration, postgresql configuration and proper sql driver, weasis, oviyam and ioviyam)
- DBbackups.exe(backup task script for databases)
- dcm4chee-arr-3.0.12-psql.exe(auditing application)
- environment.exe(sets java environment variables)
- Google chrome standalone(needed for web viewers) @ http://www.google.com/chrome/eula.html?system=true&standalone=1
- Postgresql 9.3.4 @ http://www.enterprisedb.com/products-services-training/pgdownload#windows
- Java JDK 7 @ http://download.oracle.com/otn-pub/java/jdk/7u71-b14/jdk-7u71-windows-i586.exe
5- Open & compile the project dcm4chee-2.18.0-psql.iss (it may take up to 1 minute depending on how fast your environment is).
6- The binary file will be in dcm4chee-files\bin folder once done.
PACS-сервер своими руками
Преамбула
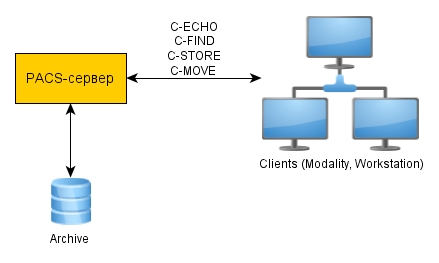
Очевидно, что для взаимодействия разнокачественного медицинского оборудования необходим единый протокол. И как раз таким протоколом выступает DICOM (Digital Imaging and Communications in Medicine), который за последние 20 лет был серьёзно усовершенствован, что позволило легко интегрировать медицинское оборудование в общую информационную систему. Практически все производители медицинского оборудования следуют этому протоколу. Следовательно поддержка протокола DICOM было естественным требованием к PACS-серверу. Было решено реализовать многопоточный высоконагруженный PACS, способный работать в кластере. Сервер разрабатывался на языке С++ и применялась самая адекватная на сегодняшний день библиотека для работы с протоколом DICOM, написанная на С++ — DCMTK. Именно благодаря этой библиотеке стало возможным быстро реализовывать высоконагруженные PACS-системы.
Проектируем БД
БД в PACS-системе позволяет хранить информацию о сохранённых изображениях и производить по ним поиск. Изображения также нужно уметь передавать по сети, а вместе с ним метаинформацию о изображении (кто на снимке, в какой клинике произведены, кто проводил исследование и прочее). Для этих целей протоколом DICOM предусмотрена специальная 4х уровневая модель данных, о которой можно вкратце узнать здесь. Полный список всевозможных атрибутов файла можно узнать на официальном сайте протокола[1]. В изображениях, полученных из разных аппаратов, список этих атрибутов будет отличаться, что является совершенно нормальным. Однако часть атрибутов остаётся обязательной для поддержания универсального поиска по изображениям. Их немного — всего штук десять, среди них Patient Name, Patient ID, Patient Birthday, Modality Type (КТ, МРТ, УЗИ и др), Study Date (дата исследования) и др. Помимо обязательных параметров существуют необязательные, их довольно много и поддерживать их в БД как показывает практика — является лишним.
Наличие большого количества необязательных параметров в метаинформации изображений — один из недостатков протокола DICOM. Некоторые аппараты выставляют одни параметры, некоторые — другие. Следовательно поддерживать их в БД для поиска — бессмысленно. В итоге проработав несколько вариантов, остановились на таком варианте БД:
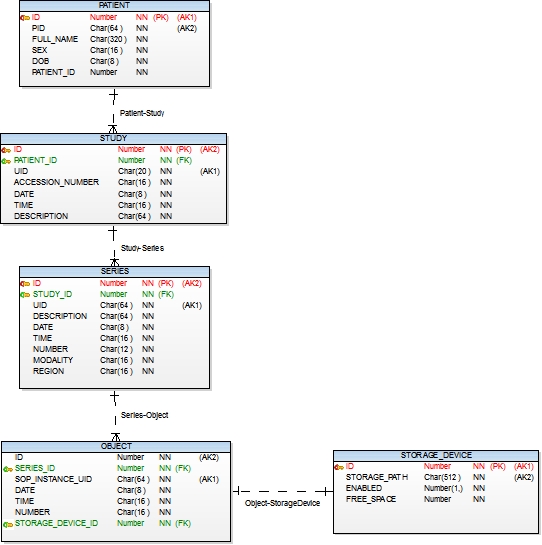
Как видно схема БД соответствует многоуровневой структуре DICOM файлов. У одного пациента может быть много стадий (читай исследований). Исследование представляет собой множество серий, определяемых протоколом исследования. Серия хранит множество изображений.
Основные функции PACS-системы
Рассмотрим вкратце основные функции (сервисы) стандартной PACS-системы, почти все из которых я уже упомянул. Поскольку любое взаимодействие рабочих станций с PACS-системой является клиент-серверным, то и все операции также реализованы в двух вариантах — клиентском и серверном. В DCMTK присутствуют реализации обоих вариантов. PACS реализует серверную часть.
Префикс ‘C-‘ у операций означает Composite, что подразумевает, что операция — целостная и самодостаточная и выполняется без привязки к другим операциям. Существуют ещё операции с префиксом ‘N-‘(N-CREATE, N-SET, N-GET и др.), которые выполняются в рамках какой-то более общей операции (выставляют статусы, информируют о начале исследования и др.). Эти операции не относятся к теме данной статьи.
C-ECHO – команда, позволяющая узнать доступность клиента в сети. Аналогична команде ping в винде. В реализации команда очень проста — нужно всего лишь отправить ответ со статусом STATUS_Success:
где assoc – соединение, установленное клиентом, request — входящий запрос.
С-STORE — команда, позволяющая сохранять изображения на PACS-сервере в формате DCM.
Вот кусок кода, который это делает:
Колбэк storeSCPCallback срабатывает на каждый пакет, а не на каждый файл. О завершении скачивания файла свидетельствует условие progress->state == DIMSE_StoreEnd , тогда мы можем сохранить файл. Единственной сложностью при реализации этой команды является выбор структуры каталогов при сохранении файла. Чтобы не хранить в таблице OBJECTS путь к файлу, мы вычисляем его из остальных данных. Мы остановились на такой структуре каталогов: ПУТЬ_К_ХРАНИЛИЩУ/STUDY.DATE(YEAR)/STUDY.DATE(MONTH)/STUDY.DATE(DAY)/STUDY.TIME(HOUR)/PATIENT.PID(первая буква)/ PATIENT.PID/STUDY.UID/<изображения>. Такая иерархическая структура позволяет минимизировать количество вложенных папок, что позволяет работать с данной структурой каталогов без временных лагов.
Также хочется сказать, что таблица OBJECT заполняется очень интенсивно. Одно исследование на МРТ-томографе длится в среднем 20 минут, за это время томограф производит 100-300 изображений, КТ-томограф 500-700 иображений. Итого изображений за день может достигать 1440/20 * 500 = 36000 изображений за сутки. В нашем диагностическом центре перерывов в работе томографов практически нет ни днём, ни ночью. Поэтому таблица OBJECT должна хранить минимально возможное количество данных.
С-MOVE — команда, позволяющая передать изображения из PACS на рабочую или диагностическую станцию. Команда передаётся вызывающей станцией (source) на PACS и в ней указывается, на какую станцию (destination) необходимо загрузить изображения. В частном случае, если source=destination, то происходит просто скачивание файлов.
Команда C-MOVE является более универсальной по сравнению с командой С-GET, позволяющей только скачивать изображения. С-MOVE умеет скачивать изображения не только на свою, но и на любую другую. В команде указывается AETitle станции, на которую требуется загрузить изображения. AETitle – это имя клиента, обычно большими буквами (например, CLIENT_SCU). Оно устанавливается при запуске dicom-listener’а (сервера).
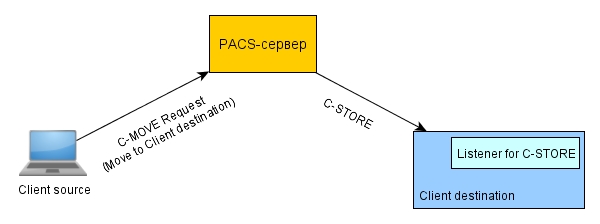
То есть клиент, инициализирующий команду С-MOVE на PACS-сервер, должен у себя запустить мини-PACS, позволяющий принимать только команду С-STORE. А PACS-сервер в свою очередь должен при команде С-MOVE установить новое соединение с клиентом, поднять изображения из хранилища и выполнить для каждого из низ клиентскую версию команды С-STORE обратно на клиент. Кстати, только команда С-MOVE позволяет передавать как сжатые изображения (JPEG), так и несжатые за счёт установления нового соединения.
Команда С-GET, однако, умеет загружать изображения без установления нового соединения и, следовательно, без необходимости поднимать сервер на клиентской стороне. В этом случае PACS также выполняет клиентскую версию команды С-STORE, только через соединение установленное командой С-GET.
C-FIND — команда, позволяющая производить поиск по изображениям на разных уровнях. То есть фактически существует четыре вида команды С-FIND: C-FIND на уровне PATIENT, на уровне STUDY, на уровне SERIES и на уровне IMAGE.
То есть в коллбэке нужно заполнить объекты response — параметры ответа и responseDataSet — информация о пациенте/стадии/серии/изображении, которую нужно было найти. Об отправке их обратно на клиент позаботится функция DIMSE_findProvider() из DCMTK.
Команда С-FIND опасна тем, что клиент может указать слишком общий критерий поиска и клиенту придётся отдавать большой объём информации. Например, можно запросить все стадии за последний год. Если попытаться сначала загрузить все данные на сервер, то сервер скорее всего повиснет. Поэтому делать большие запросы нельзя, нужно подгружать данные по мере срабатывания коллбэков. Для этого нужно реализовать запрос к БД в виде итератора и по мере срабатывания коллбэков вызывать next() и таким образом брать следующий объект. К тому же отменить поиск можно только по приходу коллбэка, поэтому если поиск на PACS’е повиснет на некоторое время на выборке из БД, а клиент будет вызывать отмену запроса, то никакой реакции на клиенте не произойдёт. Это актуально для поиска на уровне пациентов и стадий. Для поиска на уровне серий это неактуально, поскольку стадий, содержащих более 15 серий, мы на практике не встречали. Аналогично для поиска на уровне изображений — серий с более чем 1000 изображений мы на практике не встречали.
Обобщим
Итак, мы рассмотрели основные функции PACS-системы и её роль в общей структуре диагностического центра. Также освещены практические моменты и различные аспекты реализации медицинских промышленных PACS-систем. Однако этим функционалом PACS-системы как правило не ограничиваются. Существует также сервис WADO(Web Access to DICOM Objects) и сервис управления рабочими задачами (Modality worklist), также входящих в функции PACS-систем. Надеюсь, для кого-то статья окажется полезной и сэкономит кучу времени.