Установка Hadoop на Windows
Администрирование › Установка Hadoop на Windows
- В этой теме 0 ответов, 1 участник, последнее обновление 11 месяцев, 2 недели назад сделано Васильев Владимир Сергеевич.
Задача
Установить Hadoop на Windows
Решение
Для установки Hadoop у Вас должен быть установлен JDK не ниже версии 1.7 и настроена переменная окружения JAVA_HOME, указывающая на корневую директорию JDK.
1. Установка дистрибутива
Двоичный дистрибутив Hadoop можно скачать с официального сайта проекта по ссылке. Качаем версию 2.7.3 в виде архива hadoop-2.7.3.tar.gz.
Распаковываем полученный двоичный дистрибутив в выбранный для инсталяции каталог, например, C:\hadoop
Устанавливаем переменную окружения HADOOP_HOME, указывающую на папку распакованного дистрибутива (C\:hadoop\hadoop-2.7.3\)
Добавляем к переменной окружения Path путь к папке bin распакованного дистрибутива (C\:hadoop\hadoop-2.7.3\bin)
Устанавливаем переменную окружения HADOOP_CONF_DIR, указывающую на папку конфигурационных файлов распакованного дистрибутива (C\:hadoop\hadoop-2.7.3\etc\hadoop)
2. Конфигурация Hadoop
Редактируем файл C\:hadoop\hadoop-2.7.3\etc\hadoop\core-site.xml и указываем адрес файловой системы, используемой по-умолчанию
Редактируем файл настроек распределенной файловой системы C\:hadoop\hadoop-2.7.3\etc\hadoop\hdfs-site.xml . Добавляем в него коэффициент репликации (в случае локальной установки коэффицинт ставим 1). А так же указываем настройки директорий хранилища данных, обратите внимание на указание пути к директориям в формате принятом в Linux.
Редактируем файл исполнителя задач C\:hadoop\hadoop-2.7.3\etc\hadoop\mapred-site.xm и указываем, что задачи будут управляться менеджером YARN
Редактируем файл планировщика ресурсов YARN
C\:hadoop\hadoop-2.7.3\etc\hadoop\yarn-site.xm
3. Запуск Hadoop
Для запуска Hadoop под Windows необходимо заменить файлы утилит Hadoop предназначенные для Linux на файлы собранные для Windows (начиная, с версии 2.2 Hadoop позволяет делать такую сборку). Для этого качаем собранный пакет утилит WinUtils версии 2.7.1 c GitHub (например тут). Заменяем содержимое директории bin в установленном нами Hadoop на содержимое директории bin из WinUtils
Перед первым запуском Hadoop необходимо отформатировать распреленную файловую систему. Для этого выполняем команду файловой системы hdfs
ИТ База знаний
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Популярное и похожее
Redis – что это и для чего?
Разбираемся с Jenkins. Что это?
Установка IIS сервера на Windows 10
ELK (ElasticSearch, LogStash, Kibana) – сценарии использования
Chef — управление сетью. Плюсы и минусы
7 лучших хостингов MongoDB для приложений
14 инструментов оркестрации контейнеров для DevOps
Yealink SIP-T19P E2

Еженедельный дайджест
Установка Hadoop – надуваем слоника
Для чайников и кофейников
В одной из статей мы рассказывали Вам, что такое Hadoop и с чем его едят. В этой статье мы подробно разберем, как развернуть кластер Hadoop с помощью сборки Cloudera.

Почему Cloudera?
Почему мы выбрали именно этот дистрибутив? Дело в том, что на текущий момент он является самым популярным и широко распространенным набором инструментов для работы с большими объемами данных. Кроме того, данный дистрибутив имеет в составе такое решение как Cloudera Manager этот инструмент позволяет без лишних телодвижений развернуть новый кластер, а также осуществлять управление и наблюдение за его состоянием.
Стоит отметить, что распространение элементов данной сборки осуществляется в виде так называемых парселов пакетов информации в бинарной кодировке. Преимуществами такого решения являются упрощенная загрузка, взаимная согласованность компонентов, возможность единовременной активации всех необходимых установленных элементов, текущие (не кардинальные) обновления без прерывания рабочего процесса, а также простота восстановления после возникновения неполадок.
Также важно представлять, для каких целей Вы будете использовать кластеры Hadoop. Это связано с тем, что для выполнения различных задач Вам потребуются разные варианты по аппаратной мощности. Как правило, конфигурации, используемые для хранения данных, имеют повышенную мощность, а значит, и более высокую стоимость.
Требования к железу
Проработав вопросы с железом, нужно подготовить для развертки кластера программную часть. Для установки и работы потребуется любая система на основе Ubuntu, а также популярными вариантами являются различные версии CentOS, RHEL и Debian. Эти сборки находятся в открытом доступе на сайте разработчика, поэтому с подготовкой сложностей возникнуть не должно.
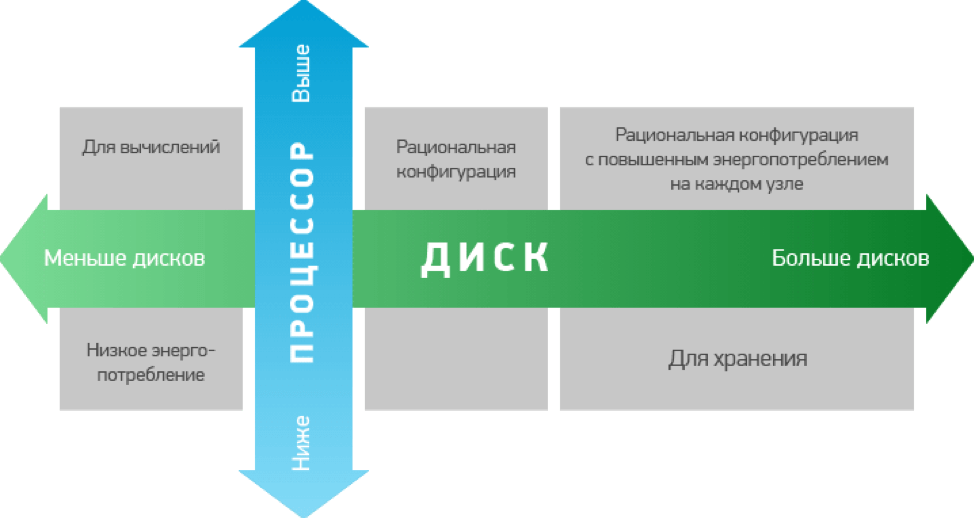
При установке на серверах будущего кластера при разбивке дисков стоит выделять около 70Гб под программную часть, около 1Гб для внутреннего участка памяти для выгрузки данных из кэша, остальную емкость можно оставить непосредственно для хранения данных.
Установка
Подготовив почву для установки, можно приступать непосредственно к процессу. Проверив соединение с серверами, их доступность и синхронизацию, а так же имеют одинаковые пароли root, а так же убедившись, что все сервера имеют доступ к сайту разработчика для обновления программной части, можно устанавливать непосредственно Cloudera Manager. Далее наше участие в процессе установки будет минимальным программа сама установит все необходимые компоненты. По ее завершению, можно запускать стандартную базу данных, и собственно саму программу.
Далее приступим к, собственно, развертыванию кластера. Это удобнее делать через веб-интерфейс. В строку браузера вводим адрес сервера, затем войдем в систему по умолчанию логин и пароль admin и admin разумеется, первым делом меняем пароли.
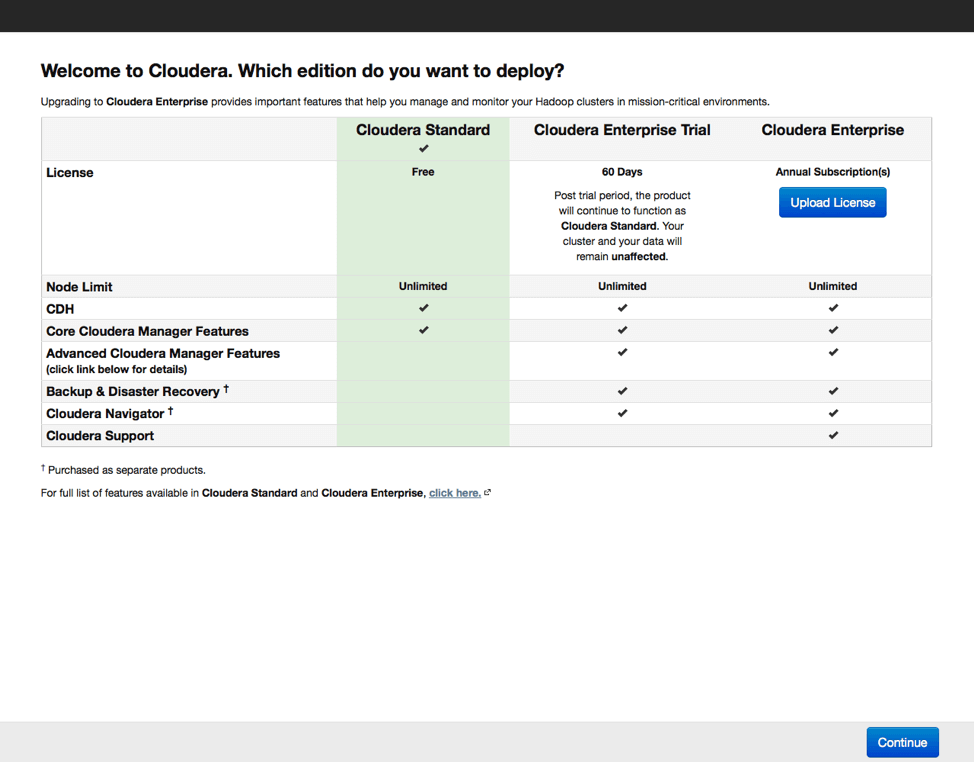
Далее выбираем версию дистрибутива. Есть бесплатный вариант с ограниченным функционалом, 60-дневная пробная версия и платная лицензия, предоставляющая наиболее полный набор функций, включая поддержку от производителя. При выборе базовой бесплатной версии можно будет в будущем активировать любую из оставшихся. Это актуально в случае, если программа Вам понравится, и вы приобретете базовые навыки работы с кластером.
В процессе установки Cloudera Manager устанавливает соединение с серверами, входящими в кластер. По умолчанию используется root и одинаковое имя пользователя, поэтому важно чтобы пароли root на всех серверах были одинаковы.
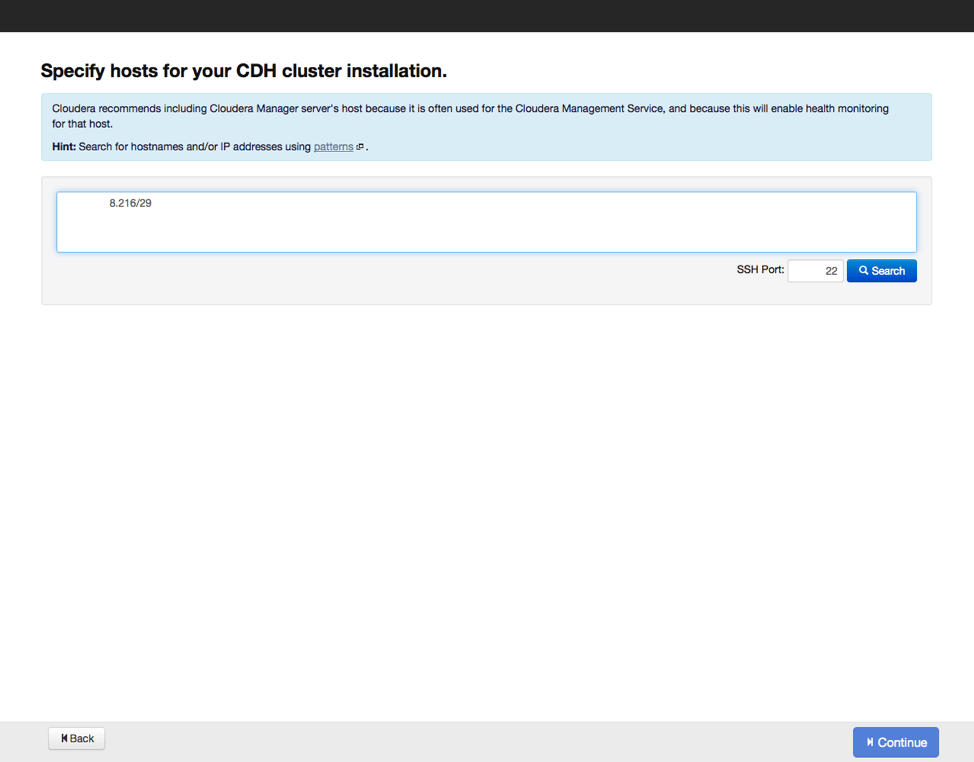
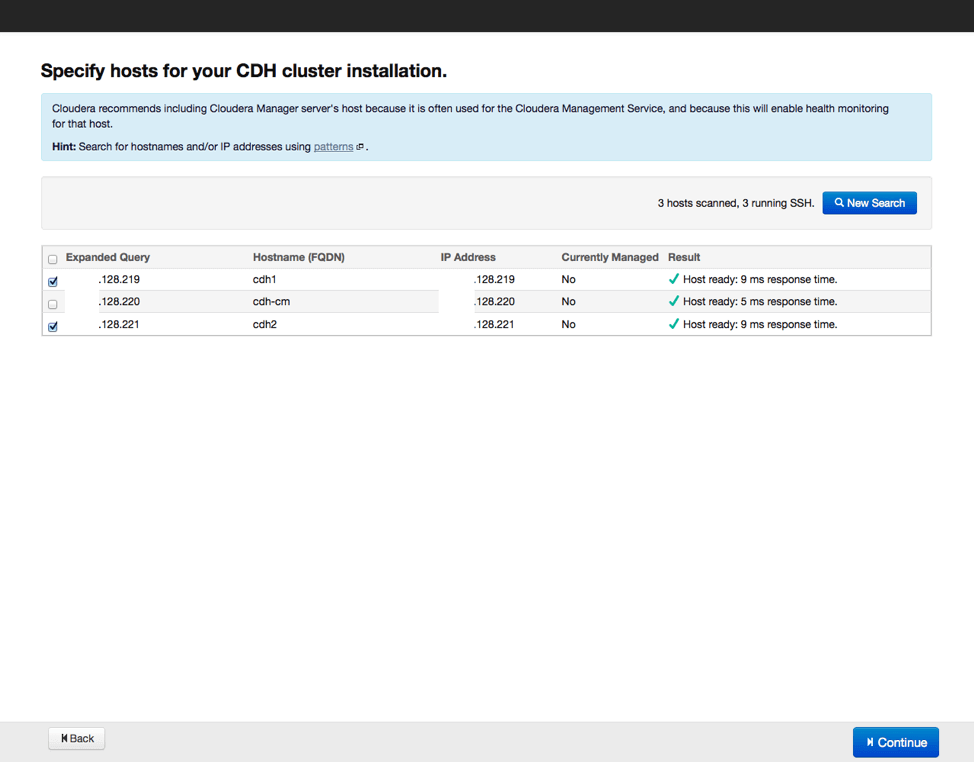
Следующим шагом станет указание хостов, куда будут устанавливаться рабочие элементы Hadoop, а также проверим, все ли сделано верно, и нет ли потерь. Затем выберем репозиторий, из которого будут скачиваться данные для установки, а также выберем вариант с использованием парселов, как и рекомендуется. Можно еще выбрать установку дополнительных инструментов актуальных версий поисковика SOLR и базы данных на основе Impala. Вводим параметры доступа по SSH и запускаем процесс установки.
По окончании установки получаем отчет о всех установленных элементах и их актуальных версиях, после его изучения переходим к следующему этапу выбору вариантов установки дополнительных компонентов Hadoop. Начинающим специалистам рекомендуется выбирать полную установку со временем конфигурацию программных инструментов можно будет менять, удаляя неиспользуемые компоненты и добавляя необходимые. Также программа установки предложит выбрать, какие элементы будут установлены на серверах. Если все сделано правильно вариант «по умолчанию» будет наилучшим выбором.
Далее нас ждет этап настройки базы данных. Настраиваем базу по умолчанию, либо выбираем альтернативный вариант, а также обязательно проверяем, как она работает. После этого настраиваем отдельные элементы в составе нашего кластера и запускаем процесс настройки по выбранным параметрам. По завершению настройки можно переходить к экрану мониторинга кластера, куда выводятся все данные по входящим в кластер серверам.
Было полезно?
Почему?
😪 Мы тщательно прорабатываем каждый фидбек и отвечаем по итогам анализа. Напишите, пожалуйста, как мы сможем улучшить эту статью.
😍 Полезные IT – статьи от экспертов раз в неделю у вас в почте. Укажите свою дату рождения и мы не забудем поздравить вас.
How to Install and Run Hadoop on Windows for Beginners
Introduction
Hadoop is a software framework from Apache Software Foundation that is used to store and process Big Data. It has two main components; Hadoop Distributed File System (HDFS), its storage system and MapReduce, is its data processing framework. Hadoop has the capability to manage large datasets by distributing the dataset into smaller chunks across multiple machines and performing parallel computation on it .
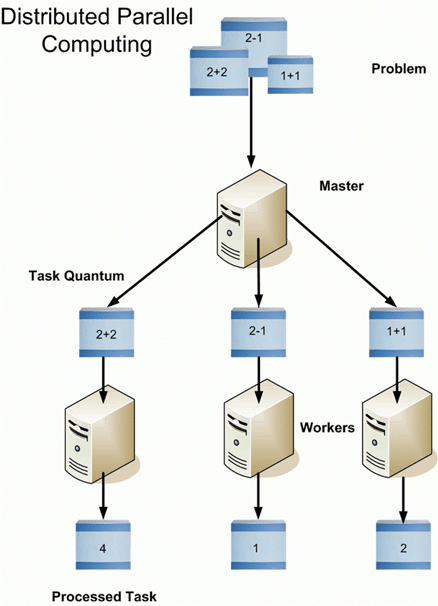
Overview of HDFS
Hadoop is an essential component of the Big Data industry as it provides the most reliable storage layer, HDFS, which can scale massively. Companies like Yahoo and Facebook use HDFS to store their data.
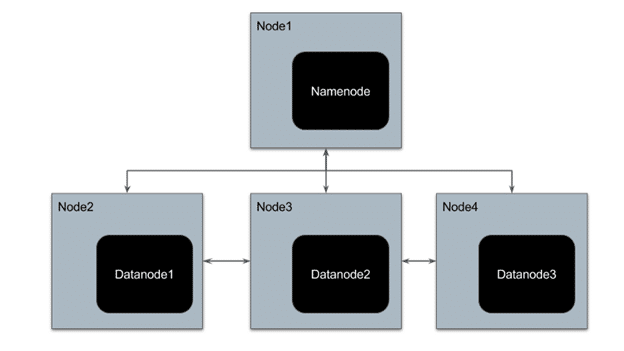
HDFS has a master-slave architecture where the master node is called NameNode and slave node is called DataNode. The NameNode and its DataNodes form a cluster. NameNode acts like an instructor to DataNode while the DataNodes store the actual data.
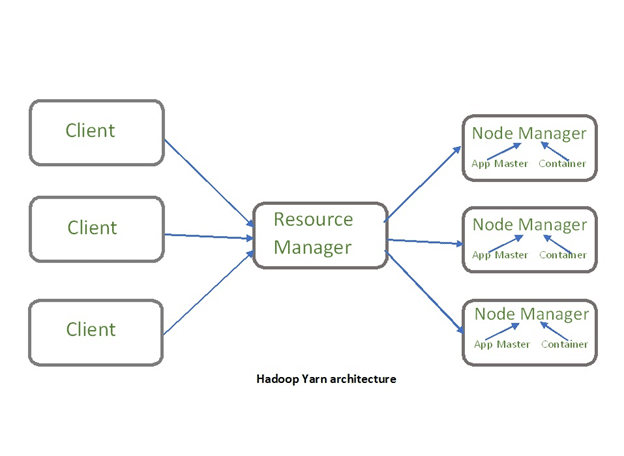
There is another component of Hadoop known as YARN. The idea of Yarn is to manage the resources and schedule/monitor jobs in Hadoop. Yarn has two main components, Resource Manager and Node Manager. The resource manager has the authority to allocate resources to various applications running in a cluster. The node manager is responsible for monitoring their resource usage (CPU, memory, disk) and reporting the same to the resource manager.
To understand the Hadoop architecture in detail, refer this blog –
Advantages of Hadoop
1. Economical – Hadoop is an open source Apache product, so it is free software. It has hardware cost associated with it. It is cost effective as it uses commodity hardware that are cheap machines to store its datasets and not any specialized machine.
2. Scalable – Hadoop distributes large data sets across multiple machines of a cluster. New machines can be easily added to the nodes of a cluster and can scale to thousands of nodes storing thousands of terabytes of data.
3. Fault Tolerance – Hadoop, by default, stores 3 replicas of data across the nodes of a cluster. So if any node goes down, data can be retrieved from other nodes.
4. Fast – Since Hadoop processes distributed data parallelly, it can process large data sets much faster than the traditional systems. It is highly suitable for batch processing of data.
5. Flexibility – Hadoop can store structured, semi-structured as well as unstructured data. It can accept data in the form of textfile, images, CSV files, XML files, emails, etc
6. Data Locality – Traditionally, to process the data, the data was fetched from the location it is stored, to the location where the application is submitted; however, in Hadoop, the processing application goes to the location of data to perform computation. This reduces the delay in processing of data.
7. Compatibility – Most of the emerging big data tools can be easily integrated with Hadoop like Spark. They use Hadoop as a storage platform and work as its processing system.
Hadoop Deployment Methods
1. Standalone Mode – It is the default mode of configuration of Hadoop. It doesn’t use hdfs instead, it uses a local file system for both input and output. It is useful for debugging and testing.
2. Pseudo-Distributed Mode – It is also called a single node cluster where both NameNode and DataNode resides in the same machine. All the daemons run on the same machine in this mode. It produces a fully functioning cluster on a single machine.
3. Fully Distributed Mode – Hadoop runs on multiple nodes wherein there are separate nodes for master and slave daemons. The data is distributed among a cluster of machines providing a production environment.
Hadoop Installation on Windows 10
As a beginner, you might feel reluctant in performing cloud computing which requires subscriptions. While you can install a virtual machine as well in your system, it requires allocation of a large amount of RAM for it to function smoothly else it would hang constantly.
You can install Hadoop in your system as well which would be a feasible way to learn Hadoop.
We will be installing single node pseudo-distributed hadoop cluster on windows 10.
Prerequisite: To install Hadoop, you should have Java version 1.8 in your system.
Check your java version through this command on command prompt