Installing Apache Spark on Mac OS


Copy the url from Home page on mac os terminal to install Home brew
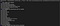
Run below command to update home brew
Check Java Version

Run below command to install Java8

For Latest Java use
Check Java Version


Use scala -version to get the scala version

Install Apache Spark

To start spark shell execute below command

Run below command to check the execution which will return the string “Hello World”

Run pyspark to start pyspark shell

Add Spark path to bash profile
Run below command and then add the path to the profile
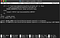
And execute below command to start all services
How to install Apache Spark on Mac OS X Yosemite
Hello data scientists,
This is a quick installation guide to install the Apache Spark on your local machine. I found the documentation on the website little confusing.
1. Download the Apache Spark tar file from the http://spark.apache.org/downloads.html. [Choose any version you would like from the dropdown menu. I recommend anything 1.3.1 or above]
2. Unzip the file into your home directory.
3. Open your terminal and go to the spark directory by doing cd spark-1.3.1 [Assuming you are in your home directory]
5. It takes at least 10 minutes to complete the whole build.
6. After the build’s completed. It should look something like the following:

8. You should see something like this:

As you can see here, it says the Job has been finished which means you have successfully made it running 🙂
Note: I am assuming you have Java installed properly on your machine. This is very important.
Installing Apache Spark 2.3.0 on macOS High Sierra

A pache Spark 2.3.0 has been released on 28 February 2018. This tutorial guides you through its essential installation steps on macOS High Sierra.
Step 1: List of Downloads
As clearly mentioned in Spark’s documentation, in order to run Apache Spark 2.3.0 you need “Java 8+, Python 2.7+/3.4+ and R 3.1+. For the Scala API, Spark 2.3.0 uses Scala 2.11”. The download links below are for JDK 8u162, Scala 2.11.12, Sbt 0.13.17, and Python 3.6.4.

Step 2: Installation Preparations
2.1 The HOME folder of this tutorial
- Home folder of this tutorial is /Users/luckspark . This home directory can also be referred to as $HOME or
. Therefore, /Users/luckspark/server and $HOME/server and
/server are the same.
2.2 The installation folder of this tutorial
In this tutorial, Sbt, Scala, and Spark, will be installed at /Users/luckspark/server (i.e., $HOME/server or
/server ). You can create the server directory under your HOME using the following commands
- Note for beginners, the command cd changes the directory (from wherever it is) to HOME directory. The commands above, thus, change the directory back to HOME, then create a new directory named “server”.
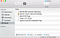
2.3 Copy all downloaded files to $HOME/server folder
- For simplicity, copy all downloaded files from step 1 to the $HOME/server folder. Your server folder shall look like this.
Step 3: Extract the downloaded files
- Extract the .tgz files (sbt*.tgz, spark*.tgz, and scala*.tgz) by double click each file, which will launch the Archive Utility program and extract the files automatically.
Step 4: Install JDK
- Double click the jdk-8u162-macosx-x64.dmg to launch JDK installation process.
- Double click the JDK 8 Update 162.pkg icon to install. The installation wizard screen will pop up.
Step 5: Install Python 3
- Double click the python-3.6.4-macosx10.6.pkg file to start Python 3 installation. Follow the wizard screens with default options.
Step 6: Setup shell environment by editing the
6.1 Summary of directory paths
Here are the directory paths of the programs that we have installed so far:
- JDK: /Library/Java/JavaVirtualMachines/jdk1.8.0_162.jdk
- Python: /Library/Frameworks/Python.framework/Versions/3.6
- Sbt: /Users/luckspark/server/sbt
- Scala: /Users/luckspark/server/scala-2.11.12
- Spark: /Users/luckspark/server/spark-2.3.0-bin-hadoop2.7
These paths will be used in step 6.2. Make sure to replace the /Users/luckspark/server with your HOME path. You do not need to modify the paths of JDK and Python.
PySpark on macOS: installation and use

Spark is a very popular framework for data processing. It has slowly taken over the use of Hadoop for data analytics. In memory processing can yield up to 100x speed compared to Hadoop and MapReduce. One of the main advantages of Spark is that no more need to write map reduce jobs. Moreover, the spark engine is compatible with a large number of data sources (txt, json, xml, sql and nosql data stores). Spark is with Hadoop, SQL, Python and R one of the most sought after skills for data scientists.
A spark application is made of:
- several execution processes which perform the data processing task.
- a driver process: which is responsible for managing the resources allocated to the executors and distribute the data processing work load among the execution processes.
Users interact with the driver trough their code. Spark is initially written in Scala but also has APIs in other languages: R, Java and more importantly Python. Spark is meant to be run on a cluster of machines but can also be run locally as driver and executors are merely processes. This can be useful to prototype applications locally before sending them to the cloud. Google Cloud DataProc is (among other solutions) a very convenient tool to launch Spark jobs on the cloud.
Setting up Spark on MacOS does not have to be a pain. I have seen many posts on the topic, but I have not really been satisfied and often found myself not understand the reason behind some steps. So I decided to write my own post on the topic:
A very convenient way to install dependencies is with homebrew (in my opinion the best package manager for MacOS).
To install homebrew, you only need to copy this in your terminal:
First we need to install Java as Spark is written in Scala, which is a Java Virtual Machine language. You can install the last version of Java with the command:
You can always get information on the package using:
You should get something that looks like this:

As Spark is written in Scala, we need to install it. If you get info on Spark using:
You should get a result similar to this:

You notice that Java is a dependency. We install Scala with the command:
Finally, Spark can be installed on the system
After installing the packages, it is good to check your system with
if you have: “Your system is ready to brew.” you can go to the next step. If you have any message you can follow the instructions given by the console.
2. Installing pySpark
I assume that you already have python 3 installed on your computer. If not installed already, you can do so with homebrew
Then you need to install the python Spark API pySpark:
3. Setting up environment
Almost done! Now you need to define several environment variables and declare paths so that the Spark driver is accessible through pySpark.
First of all we need to declare which java version to use. I have two versions on my system. You can do so by opening the .bashrc file with nano:
The java version can be declared with the following environment variable:
and the java runtime environment is declared as follows:
Now two variables must be declared for Spark:
The first defines where your Spark libraries are installed and the second make visible your binaries to your shell (in particular the pypspark executable that we use later). Finally, PySpark must be configured:
You can find your python3 distribution using the command:
which is used to define the variable PYSPARK_PYTHON. In order to be able to start a notebook with the command pyspark we define the two last variables: PYSPARK_DRIVER_PYTHON and PYSPARK_DRIVER_PYTHON_OPS.
You are all setup. The command
will startup a new jupyter notebook session. The Spark UI can be consulted at the address: