Мониторинг сетевого стека linux
 Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели OSI!
Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели OSI!
С одной стороны большинство проблем с сетью возникают как раз на физическом и канальном уровнях, но с другой стороны приложения, работающие с сетью оперируют на уровне TCP сессий и не видят, что происходит на более низких уровнях.
Я расскажу, как достаточно простые метрики TCP/IP стека могут помочь разобраться с различными проблемами в распределенных системах.
Netlink
Почти все знают утилиту netstat в linux, она может показать все текущие TCP соединения и дополнительную информацию по ним. Но при большом количестве соединений netstat может работать достаточно долго и существенно нагрузить систему.
Есть более дешевый способ получить информацию о соединениях — утилита ss из проекта iproute2.
Ускорение достигается за счет использования протола netlink для запросов информации о соединениях у ядра. Наш агент использует netlink напрямую.
Считаем соединения
Disclaimer: для иллюстрации работы с метриками в разных срезах я буду показывать наш интерфейс (dsl) работы с метриками, но это можно сделать и на opensource хранилищах.
В первую очередь мы разделяем все соединения на входящие (inbound) и исходящие (outbound) по отношению к серверу.
Каждое TCP соединения в определенный момент времени находится в одном из состояний, разбивку по которым мы тоже сохраняем (это иногда может оказаться полезным):
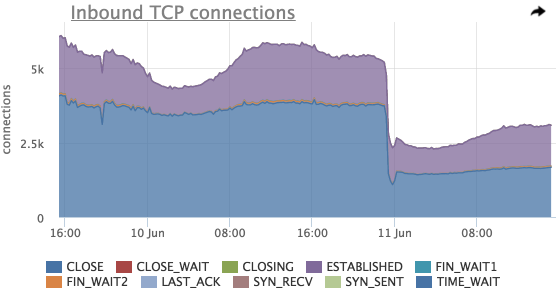
По этому графику можно оценить общее количество входящих соединений, распределение соединений по состояниям.
Здесь так же видно резкое падение общего количества соединений незадолго до 11 Jun, попробуем посмотреть на соединения в разрезе listen портов:

На этом графике видно, что самое значительное падение было на порту 8014, посмотрим только 8014 (у нас в интерфейсе можно просто нажать на нужном элементе легенды):

Попробуем посмотреть, изменилось ли количество входящий соединений по всем серверам?
Выбираем серверы по маске “srv10*”:
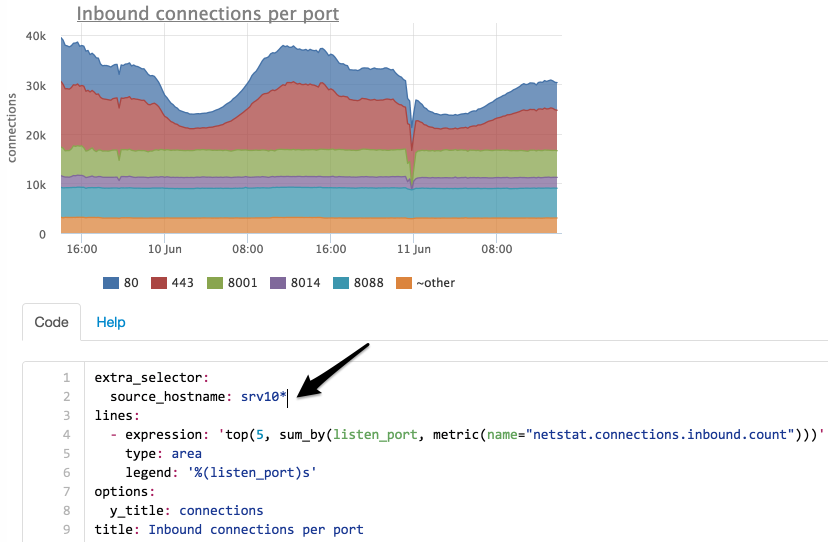
Теперь мы видим, что количество соединений на порт 8014 не изменилось, попробуем найти на какой сервер они мигрировали:

Мы ограничили выборку только портом 8014 и сделали группировку не по порту, а по серверам.
Теперь понятно, что соединения с сервера srv101 перешли на srv102.
Разбивка по IP
Часто бывает необходимо посмотреть, сколько было соединений с различных IP адресов. Наш агент снимает количество TCP соединений не только с разбивкой по listen портам и состояниям, но и по удаленному IP, если данный IP находится в том же сегменте сети (для всех остальный адресов метрики суммируются и вместо IP мы показываем “
Рассмотрим тот же период времени, что и в предыдущих случаях:
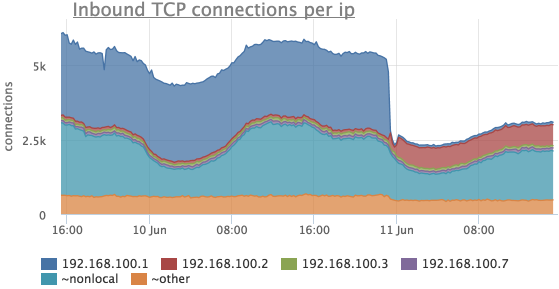
Здесь видно, что соединений с 192.168.100.1 стало сильно меньше и в это же время появились соединения с 192.168.100.2.
Детализация рулит
На самом деле мы работали с одной метрикой, просто она была сильно детализирована, индентификатор каждого экземпляра выглядит примерно так:
Например, у одно из клиентов на нагруженном сервере-фронтенде снимается
700 экземпляров этой метрики
TCP backlog
По метрикам TCP соединений можно не только диагностировать работу сети, но и определять проблемы в работе сервисов.
Например, если какой-то сервис, обслуживающий клиентов по сети, не справляется с нагрузкой и перестает обрабатывать новые соединения, они ставятся в очередь (backlog).
На самом деле очереди две:
- SYN queue — очередь неустановленных соединений (получен пакет SYN, SYN-ACK еще не отправлен), размер ограничен согласно sysctl net.ipv4.tcp_max_syn_backlog;
- Accept queue — очередь соединений, для которых получен пакет ACK (в рамках «тройного рукопожатия»), но не был выполнен accept приложением (очередь ограничивается приложением)
При достижении лимита accept queue ACK пакет удаленного хоста просто отбрасывается или отправляется RST (в зависимости от значения переменной sysctl net.ipv4.tcp_abort_on_overflow).
Наш агент снимает текущее и максимальное значение accept queue для всех listen сокетов на сервере.
Для этих метрик есть график и преднастроенный триггер, который уведомит, если backlog любого сервиса использован более чем на 90%:

Счетчики и ошибки протоколов
Однажды сайт одного из наших клиентов подвергся DDOS атаке, в мониторинге было видно только увеличение трафика на сетевом интерфейсе, но мы не показывали абсолютно никаких метрик по содержанию этого трафика.
В данный момент однозначного ответа на этот вопрос окметр дать по-прежнему не может, так как сниффинг мы только начали осваивать, но мы немного продвинулись в этом вопросе.
Попробуем что-то понять про эти выбросы входящего трафика:
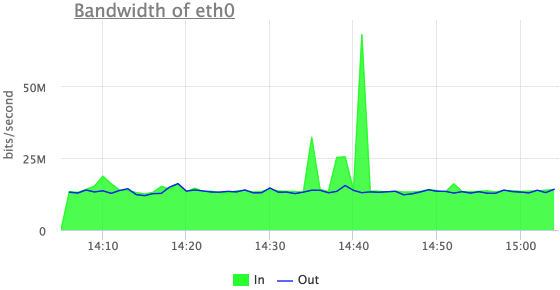

Теперь мы видим, что это входящий UDP трафик, но здесь не видно первых из трех выбросов.
Дело в том, что счетчики пакетов по протоколам в linux увеличиваются только в случае успешной обработки пакета.
Попробуем посмотреть на ошибки:
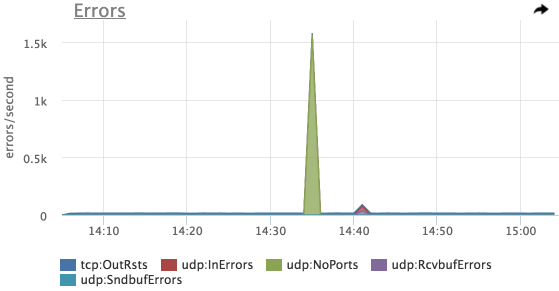
А вот и наш первый пик — ошибки UDP:NoPorts (количество датаграмм, пришедших на UPD порты, которые никто не слушает)
Данный пример мы эмулировали с помощью iperf, и в первый заход не включили на сервер-приемщик пакетов на нужном порту.
TCP ретрансмиты
Отдельно мы показываем количество TCP ретрансмитов (повторных отправок TCP сегментов).
Само по себе наличие ретрансмитов не означает, что в вашей сети есть потери пакетов.
Повторная передача сегмента осуществляется, если передающий узел не получил от принимающего подтверждение (ACK) в течении определенного времени (RTO).
Данный таймаут расчитывается динамически на основе замеров времени передачи данных между конкретными хостами (RTT) для того, чтобы обеспечивать гарантированную передачу данных при сохранении минимальных задержек.
На практике количество ретрансмитов обычно коррелирует с нагрузкой на серверы и важно смотреть не на абсолютное значение, а на различные аномалии:

На данном графике мы видим 2 выброса ретрансмитов, в это же время процессы postgres утилизировали CPU данного сервера:

Cчетчики протоколов мы получаем из /proc/net/snmp.
Conntrack
Еще одна распространенная проблема — переполнение таблицы ip_conntrack в linux (используется iptables), в этом случае linux начинает просто отбрасывать пакеты.
Это видно по сообщению в dmesg:
Агент автоматически снимает текущий размер данной таблицы и лимит с серверов, использующих ip_conntrack.
В окметре так же есть автоматический триггер, который уведомит, если таблица ip_conntrack заполнена более чем на 90%:
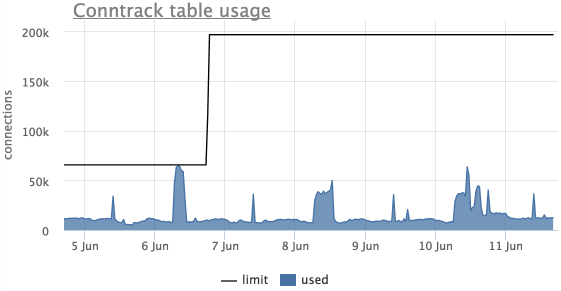
На данном графике видно, что таблица переполнялась, лимит подняли и больше он не достигался.
Вместо заключения
Примеры наших стандартных графиков можно посмотреть в нашем демо-проекте.
Там же можно постмотреть графики Netstat.
Анатомия сетевого стека в Linux
От сокетов до драйверов устройств

Введение в протоколы
В то время как формальное введение в работу в сети отсылает нас к модели взаимодействия открытых систем (OSI — Open Systems Interconnection), это введение в основной сетевой стек в Linux использует четырехуровневую модель, известную как модель Интернет (Internet model) (смотрите рисунок 1).
Рисунок 1. Интернет-модель сетевого стека

Внизу стека располагается канальный уровень. Канальный уровень относится к драйверам устройств, обеспечивающим доступ к физическому уровню, который может состоять из многочисленных сред, таких как последовательные каналы или устройства Ethernet. Над канальным находится сетевой уровень, который отвечает за направление пакетов по назначению. Следующий уровень под названием транспортный отвечает за одноранговые (peer-to-peer) коммуникации (например, в пределах хоста). Сетевой уровень управляет связью между хостами, а транспортный — взаимодействием между конечными точками внутри этих хостов. Наконец, существует прикладной уровень, который обычно является семантическим и понимает перемещенные данные. К примеру, протокол передачи гипертекста (HTTP — Hypertext Transfer Protocol) перемещает запросы и ответы для содержимого Web между сервером и клиентом.
В сущности, уровни сетевого стека проходят под более узнаваемыми названиями. На канальном уровне вы найдете Ethernet, наиболее распространенную высокоскоростную среду. К более старым протоколам канального уровня относятся такие последовательные протоколы, как Internet-протокол для последовательной линии (SLIP — Serial Line Internet Protocol), Compressed SLIP (CSLIP) и Point-to-Point Protocol (PPP). Наиболее распространенным протоколом сетевого уровня является Internet Protocol (IP), но существуют и другие, которые удовлетворяют другим нуждам, такие как Протокол управляющих сообщений Internet (ICMP — Internet Control Message Protocol) и Протокол разрешения адресов (ARP — Address Resolution Protocol). На транспортном уровне это Протокол управления передачей (TCP — Transmission Control Protocol) и Протокол пользовательских датаграмм (UDP — User Datagram Protocol). Наконец, прикладной уровень включает в себя множество привычных нам протоколов, в том числе HTTP, стандартный Web-протокол, и SMTP (Simple Mail Transfer Protocol), протокол передачи электронной почты.
Архитектура базовой сети
Теперь перейдем к архитектуре сетевого стека Linux и посмотрим, как он реализует модель Internet. На рисунке 2 представлен высокоуровневый вид сетевого стека Linux. Наверху располагается уровень пользовательского пространства или прикладной уровень, который определяет пользователей сетевого стека. Внизу находятся физические устройства, которые обеспечивают возможность соединения с сетями (последовательные или высокоскоростные сети, как Ethernet). В центре, или в пространстве ядра, — сетевая подсистема, которая находится в центре внимания данной статьи. Через внутреннюю часть сетевого стека проходят буферы сокетов ( sk_buffs ), которые перемещают данные пакета между источниками и получателями. Кратко будет показана структура sk_buff .
Рисунок 2. Высокоуровневая архитектура сетевого стека Linux

Во-первых, вам предлагается краткий обзор основных элементов сетевой подсистемы Linux с подробностями в следующих разделах. Наверху (смотрите рисунок 2) находится система под названием интерфейс системного вызова. Она просто дает способ приложениям из пользовательского пространства получать доступ к сетевой подсистеме ядра. Следующим идет протоколо-независимый (protocol agnostic) уровень, который предоставляет общий способ работы с нижестоящими протоколами транспортного уровня. Дальше следуют фактические протоколы, к которым в системе Linux относятся встроенные протоколы TCP, UDP и, конечно же, IP. Следующий — еще один независимый уровень, который обеспечивает общий интерфейс к отдельным доступным драйверам устройств и от них, сопровождаемый в конце самими этими драйверами.
Интерфейс системного вызова
Интерфейс системного вызова может быть описан в двух ракурсах. Когда сетевой вызов производится пользователем, он мультиплексируется через системный вызов в ядро. Это заканчивается как вызов sys_socketcall в ./net/socket.c, который потом демультиплексирует вызов намеченной цели. Другой ракурс интерфейса системного вызова — использование нормальных файловых операций для сетевого ввода/вывода (I/O). Например, обычные операции чтения и записи могут быть выполнены на сетевом сокете (который представляется файловым дескриптором как нормальный файл). Поэтому пока существуют операции, специфичные для работы в сети (создание сокета вызовом socket , связывание его с дескриптором вызовом connect и так далее), есть также и некоторое количество стандартных файловых операций, которые применяются к сетевым объектам, как к обычным файлам. Наконец, интерфейс системного вызова предоставляет средства для передачи управления между приложением в пользовательском пространстве и ядром.
Протоколо-независимый интерфейс (Protocol agnostic interface)
Уровень сокетов является протоколо-независимым (protocol agnostic) интерфейсом, который предоставляет набор стандартных функций для поддержки ряда различных протоколов. Этот уровень не только поддерживает обычные TCP- и UDP-протоколы, но также и IP, raw Ethernet и другие транспортные протоколы, такие как Протокол управления передачей потоков данных (SCTP — Stream Control Transmission Protocol).
Взаимодействие через сетевой стек происходит посредством сокета. Структура сокета в Linux — struct sock , определенная в linux/include/net/sock.h. Эта большая структура содержит все необходимые состояния отдельного сокета, включая определенный протокол, используемый сокетом, и операции, которые можно над ним совершать.
Сетевая подсистема знает о доступных протоколах из специальной структуры, которая определяет ее возможности. Каждый протокол содержит структуру под названием proto (она находится в linux/include/net/sock.h). Эта структура определяет отдельные операции сокета, которые могут выполняться из уровня сокетов на транспортный уровень (например, как создать сокет, как установить соединение с сокетом, как закрыть сокет и т.д.).
Сетевые протоколы
Раздел сетевых протоколов определяет отдельные доступные сетевые протоколы (такие как TCP, UDP и так далее). Они инициализируются в начале дня в функции inet_init в linux/net/ipv4/af_inet.c (так как TCP и UDP относятся к семейству протоколов inet ). Функция inet_init регистрирует каждый из встроенных протоколов, использующих функцию proto_register . Эта функция определена в linux/net/core/sock.c, и кроме добавления протокола в список действующих, если требуется, может выделять один или более slab-кэшей.
Можно увидеть, как отдельные протоколы идентифицируют сами себя посредством структуры proto в файлах tcp_ipv4.c, udp.c и raw.c, в linux/net/ipv4/. Каждая из этих структур протоколов отображается в виде типа и протокола в inetsw_array , который приписывает встроенные протоколы их операциям. Структура inetsw_array и его связи показаны на рисунке 3. Каждый из протоколов в этом массиве инициализируется в начале дня в inetsw вызовом inet_register_protosw из inet_init . Функция inet_init также инициализирует различные модули inet , такие как ARP, ICMP, IP-модули и TCP и UDP-модули.
Рисунок 3. Структура массива Internet-протокола

Корреляция сокета и протокола
Вспомните, что когда сокет создается, он определяет тип и протокол, например, my_sock = socket( AF_INET, SOCK_STREAM, 0 ) . AF_INET указывает семейство Internet-адресов с потоковым сокетом, определенным как SOCK_STREAM (как показано здесь, в inetsw_array ).
Обратите внимание на рисунке 3, что структура proto определяет транспортные методы сокета, в то время как структура proto_ops — общие. Дополнительные протоколы можно добавить в переключатель протоколов inetsw с помощью вызова inet_register_protosw . Например, SCTP добавляет себя вызовом sctp_init в linux/net/sctp/protocol.c. Более подробную информацию об SCTP можно найти в разделе Ресурсы.
Перемещение данных для сокетов происходит при помощи основной структуры под названием буфер сокета ( sk_buff ). В sk_buff содержатся данные пакета и данные о состоянии, которые охватывают несколько уровней стека протокола. Каждый отправленный или полученный пакет представлен в sk_buff . Структура sk_buff определяется в linux/include/linux/skbuff.h и показана на рисунке 4.
Рисунок 4. Буфер сокета и его связи с другими структурами

Как можно заметить, несколько структур sk_buff для данного соединения могут быть связаны вместе. Каждая из них идентифицирует структуру устройства ( net_device ), которому пакет посылается или от которого получен. Так как каждый пакет представлен в sk_buff , заголовки пакетов удобно определены набором указателей ( th , iph и mac для Управления доступом к среде (заголовок Media Access Control или MAC). Поскольку структуры sk_buff являются центральными в организации данных сокета, для управления ими был создан ряд функций поддержки. Существуют функции для создания, разрушения, клонирования и управления очередностью sk_buff .
Буферы сокетов разработаны таким образом, чтобы связываться друг с другом для данного сокета и включать большой объем информации, в том числе ссылки на заголовки протоколов, временные метки (когда пакет был отправлен или получен) и соответствующее устройство.
Устройство-независимый интерфейс (Device agnostic interface)
Под уровнем протоколов располагается другой независимый уровень интерфейса, который связывает протоколы с различными драйверами физических устройств с разными возможностями. Этот уровень предоставляет стандартный набор функций, которые используются низко-уровневыми сетевыми устройствами, чтобы иметь возможность взаимодействовать с высоко-уровневым стеком протокола.
Прежде всего, драйверы устройств могут регистрировать и разрегистрировать себя в ядре вызовом register_netdevice или unregister_netdevice . Вызывающая команда сначала заполняет структуру net_device , а затем передает ее для регистрации. Ядро вызывает свою функцию init (если она определена), выполняет несколько проверок исправности, создает запись sysfs и потом добавляет новое устройство в список устройств (связанный список устройств, активных в ядре). Структуру net_device можно найти в linux/include/linux/netdevice.h. Некоторые функции находятся в linux/net/core/dev.c.
Для отправления sk_buff из уровня протокола устройству используется функция dev_queue_xmit . Она ставит в очередь sk_buff для возможной пересылки соответствующим драйвером устройства (устройством, определенным при помощи net_device или указателя sk_buff->dev в sk_buff ). Структура dev содержит метод под названием hard_start_xmit , который хранит функцию драйвера для инициализации передачи sk_buff .
Получение пакета выполняется традиционно при помощи netif_rx . Когда драйвер устройства более низкого уровня получает пакет (содержащийся внутри выделенного sk_buff ), sk_buff идет выше, на сетевой уровень, с помощью вызова netif_rx . Эта функция затем ставит sk_buff в очередь на более высокий уровень протоколов для дальнейшей обработки при помощи netif_rx_schedule . Функции dev_queue_xmit и netif_rx находятся в linux/net/core/dev.c.
Наконец, для взаимодействия с устройство-независимым уровнем ( dev ) в ядро был введен новый интерфейс прикладных программ (NAPI). Его используют некоторые драйверы, но подавляющее большинство все еще пользуется более старым интерфейсом получения кадров (по грубой оценке шесть из семи). NAPI может давать лучшую производительность при больших нагрузках, избегая при этом прерываний при каждом входящем кадре.
Драйверы устройств
Внизу сетевого стека находятся драйверы устройств, которые управляют физическими сетевыми устройствами. Примерами устройств этого уровня могут служить драйвер SLIP над последовательным интерфейсом или драйвер Ethernet над устройством Ethernet.
Во время инициализации драйвер устройства выделяет место для структуры net_device , а затем инициализирует ее необходимыми подпрограммами. Одна из них, с названием dev->hard_start_xmit , определяет, как верхний уровень должен поставить в очередь sk_buff для передачи. Ей передается sk_buff . Работа этой функции зависит от оборудования, но обычно пакет, описываемый в sk_buff , перемещается в так называемое «аппаратное кольцо» (hardware ring) или «очередь» (queue). Поступление кадра, как описано на устройство-независимом уровне, использует интерфейс netif_rx или netif_receive_skb для NAPI-совместимого сетевого драйвера. Драйвер NAPI накладывает ограничения на возможности базового оборудования. Подробности смотрите в разделе Ресурсы.
После того как драйвер устройства настроил свои интерфейсы в структуре dev , вызов register_netdevice делает ее доступной для использования. В linux/drivers/net можно найти драйверы, характерные для сетевых устройств.
Идем дальше
Исходный код Linux — прекрасный способ узнать о конструкции драйверов для множества типов устройств, включая драйверы сетевых устройств. Вы обнаружите различия в конструкции и использовании доступных API ядра, но каждый будет полезен либо инструкциями, либо как отправная точка для нового драйвера. Остальной код в сетевом стеке стандартен и используется, пока не потребуется новый протокол. Но даже тогда реализации TCP (для потокового протокола) или UDP (для протокола на основе передачи сообщений) служат полезными моделями для начала новой разработки.
Ресурсы для скачивания
Похожие темы
- «Anatomy of the Linux networking stack»— оригинал этой статьи на developerWorks (EN).
- Краткое введение в TCP/IP, UDP и ICMP посмотрите в статье «Введение в Internet-протоколы» («Introduction to the Internet Protocols») на www.linuxjunkies.org (EN).
- «Передача команд ядру при помощи системных вызовов Linux» («Kernel command using Linux system calls») (developerWorks, март 2007) охватывает тему интерфейса системного вызова Linux, что является важным слоем ядра Linux с поддержкой пространства пользователя от GNU C Library (glibc), которая активизирует вызовы функций между пользовательским пространством и ядром (EN).
- Статья «Получите доступ к ядру, используя файловую систему /proc» («Access the Linux kernel using the /proc filesystem») (developerWorks, март 2006) обращена к файловой системе /proc, виртуальной файловой системе, которая предоставляет новый способ взаимодействия приложений пользовательского пространства с ядром. В статье демонстрируется /proc, а также загружаемые модули ядра (EN).
- Linux, как и BSD, — великая операционная система, если вас интересуют сетевые протоколы. Статья «Лучше работать в сети с SCTP» («Better networking with SCTP») (developerWorks, февраль 2006) посвящена одному из самых интересных сетевых протоколов, SCTP, который работает, как TCP, но добавляет несколько полезных свойств, таких как обмен сообщениями, многоточечные подключения и многопоточность (EN).
- Статья «Анатомия распределителя памяти slab в Linux» («Anatomy of the Linux slab allocator») (developerWorks, май 2007) посвящена одному из самых интересных аспектов управления памятью в Linux — механизму slab allocator. Он происходит из SunOS, но хорошо ужился внутри ядра Linux (EN).
- У NAPI-драйвера есть преимущества перед драйверами, использующими более старые средства обработки пакетов, начиная с лучшего управления прерываниями и до дросселирования пакетов. Более подробно об Интерфейсе и конструкции NAPI можно прочитать на сайте OSDL.
- Посмотрите книгу Тима Программирование Приложений под GNU/Linux (GNU/Linux Application Programming) (EN) на предмет более подробной информации о программировании в пользовательском пространстве в Linux (EN).
- Из книги Тима Использование BSD-сокетов в различных языках программирования (BSD Sockets Programming from a Multi-Language Perspective) можно узнать о программировании сокетов с использованием BSD Sockets API (EN).
- В разделе Linux developerWorks можно найти больше ресурсов для разработчиков Linux, включая пособия по Linux, а также любимые статьи и учебники наших читателей по Linux за последний месяц.
- Свою следующую разработку в Linux создавайте с пробным ПО IBM, доступным для скачивания прямо с developerWorks. (EN)
Комментарии
Войдите или зарегистрируйтесь для того чтобы оставлять комментарии или подписаться на них.