ИТ База знаний
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Популярное и похожее
Redis – что это и для чего?
Разбираемся с Jenkins. Что это?
Установка IIS сервера на Windows 10
Топ 7 Python расширений для IntelliJ IDEA
Puppet — краткий обзор
База данных Hadoop — увеличь свой хобот
7 лучших облачных open – source платформ для IT — компаний
Addpac ADD-AP200E

Еженедельный дайджест
Установка Hadoop – надуваем слоника
Для чайников и кофейников
В одной из статей мы рассказывали Вам, что такое Hadoop и с чем его едят. В этой статье мы подробно разберем, как развернуть кластер Hadoop с помощью сборки Cloudera.

Почему Cloudera?
Почему мы выбрали именно этот дистрибутив? Дело в том, что на текущий момент он является самым популярным и широко распространенным набором инструментов для работы с большими объемами данных. Кроме того, данный дистрибутив имеет в составе такое решение как Cloudera Manager этот инструмент позволяет без лишних телодвижений развернуть новый кластер, а также осуществлять управление и наблюдение за его состоянием.
Стоит отметить, что распространение элементов данной сборки осуществляется в виде так называемых парселов пакетов информации в бинарной кодировке. Преимуществами такого решения являются упрощенная загрузка, взаимная согласованность компонентов, возможность единовременной активации всех необходимых установленных элементов, текущие (не кардинальные) обновления без прерывания рабочего процесса, а также простота восстановления после возникновения неполадок.
Также важно представлять, для каких целей Вы будете использовать кластеры Hadoop. Это связано с тем, что для выполнения различных задач Вам потребуются разные варианты по аппаратной мощности. Как правило, конфигурации, используемые для хранения данных, имеют повышенную мощность, а значит, и более высокую стоимость.
Требования к железу
Проработав вопросы с железом, нужно подготовить для развертки кластера программную часть. Для установки и работы потребуется любая система на основе Ubuntu, а также популярными вариантами являются различные версии CentOS, RHEL и Debian. Эти сборки находятся в открытом доступе на сайте разработчика, поэтому с подготовкой сложностей возникнуть не должно.
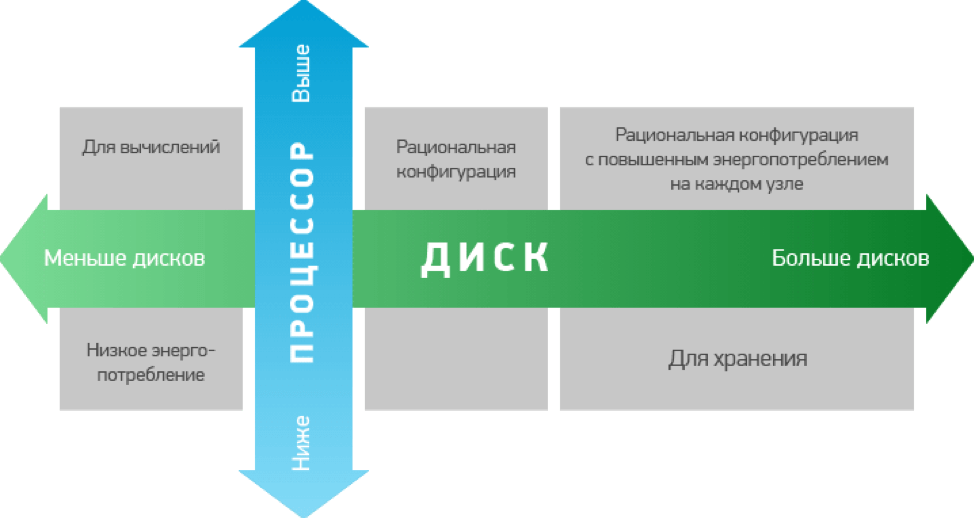
При установке на серверах будущего кластера при разбивке дисков стоит выделять около 70Гб под программную часть, около 1Гб для внутреннего участка памяти для выгрузки данных из кэша, остальную емкость можно оставить непосредственно для хранения данных.
Установка
Подготовив почву для установки, можно приступать непосредственно к процессу. Проверив соединение с серверами, их доступность и синхронизацию, а так же имеют одинаковые пароли root, а так же убедившись, что все сервера имеют доступ к сайту разработчика для обновления программной части, можно устанавливать непосредственно Cloudera Manager. Далее наше участие в процессе установки будет минимальным программа сама установит все необходимые компоненты. По ее завершению, можно запускать стандартную базу данных, и собственно саму программу.
Далее приступим к, собственно, развертыванию кластера. Это удобнее делать через веб-интерфейс. В строку браузера вводим адрес сервера, затем войдем в систему по умолчанию логин и пароль admin и admin разумеется, первым делом меняем пароли.
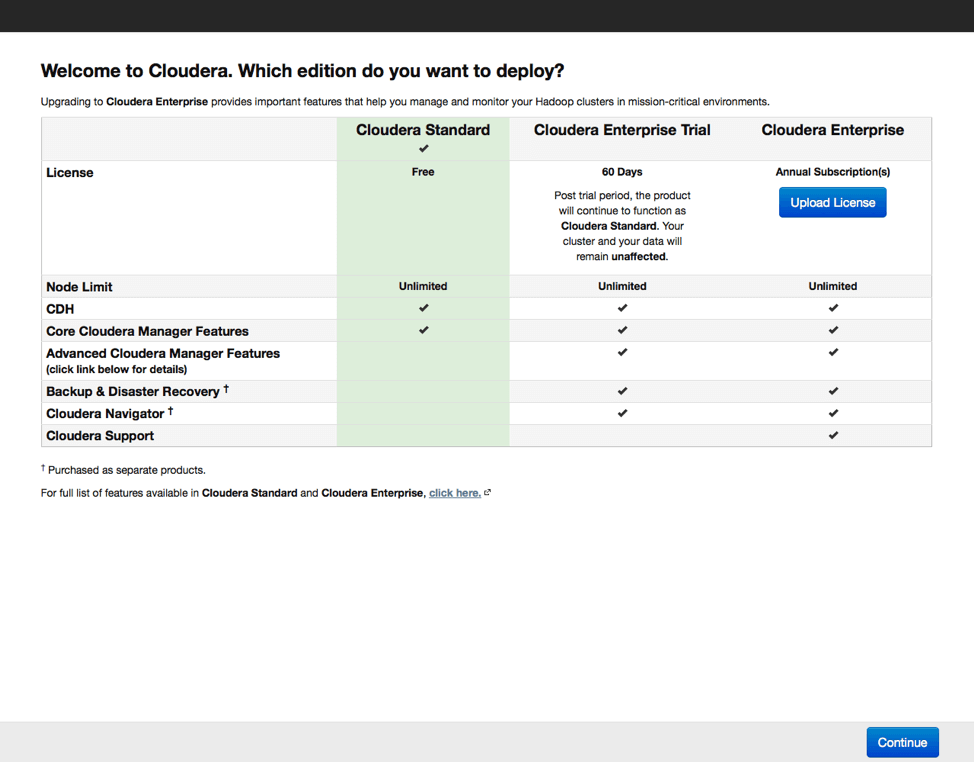
Далее выбираем версию дистрибутива. Есть бесплатный вариант с ограниченным функционалом, 60-дневная пробная версия и платная лицензия, предоставляющая наиболее полный набор функций, включая поддержку от производителя. При выборе базовой бесплатной версии можно будет в будущем активировать любую из оставшихся. Это актуально в случае, если программа Вам понравится, и вы приобретете базовые навыки работы с кластером.
В процессе установки Cloudera Manager устанавливает соединение с серверами, входящими в кластер. По умолчанию используется root и одинаковое имя пользователя, поэтому важно чтобы пароли root на всех серверах были одинаковы.
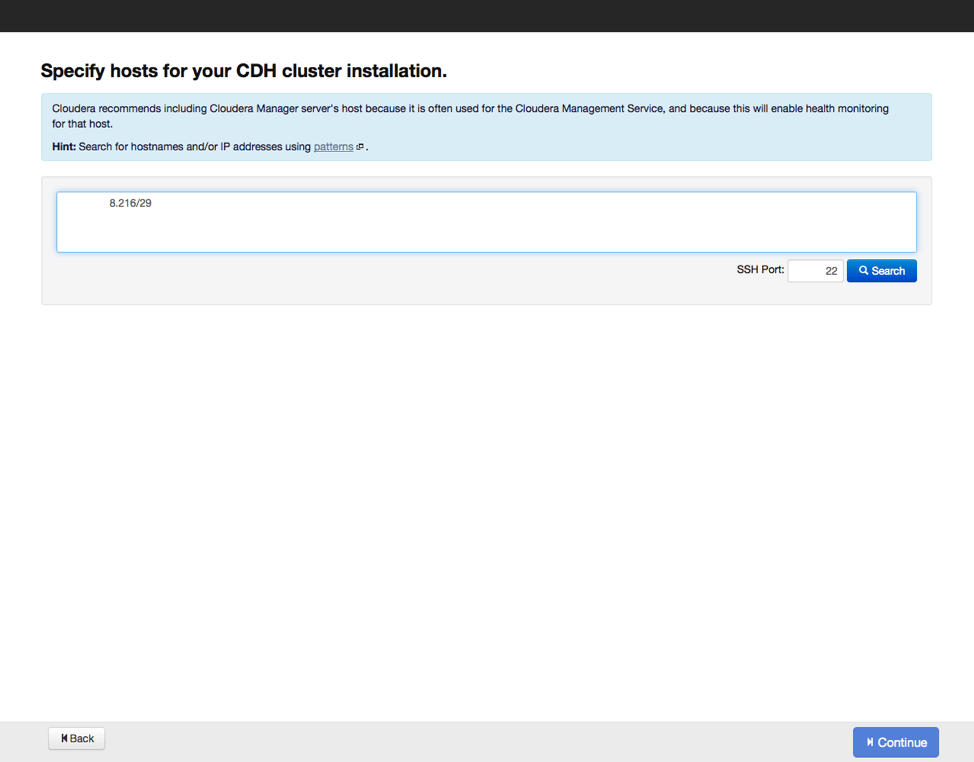
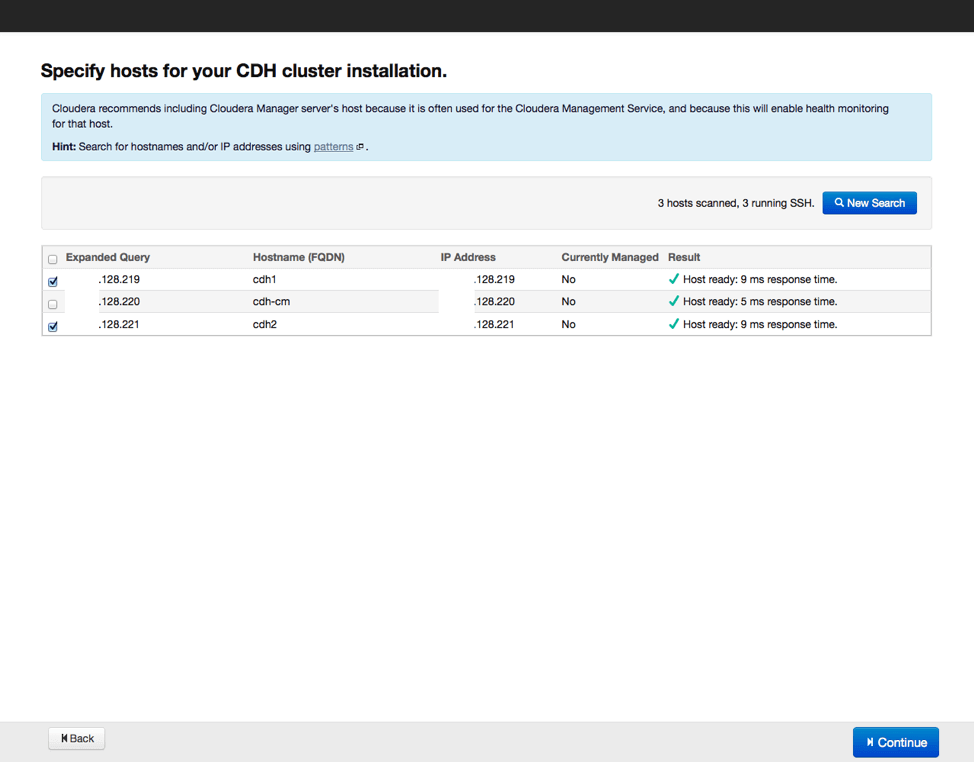
Следующим шагом станет указание хостов, куда будут устанавливаться рабочие элементы Hadoop, а также проверим, все ли сделано верно, и нет ли потерь. Затем выберем репозиторий, из которого будут скачиваться данные для установки, а также выберем вариант с использованием парселов, как и рекомендуется. Можно еще выбрать установку дополнительных инструментов актуальных версий поисковика SOLR и базы данных на основе Impala. Вводим параметры доступа по SSH и запускаем процесс установки.
По окончании установки получаем отчет о всех установленных элементах и их актуальных версиях, после его изучения переходим к следующему этапу выбору вариантов установки дополнительных компонентов Hadoop. Начинающим специалистам рекомендуется выбирать полную установку со временем конфигурацию программных инструментов можно будет менять, удаляя неиспользуемые компоненты и добавляя необходимые. Также программа установки предложит выбрать, какие элементы будут установлены на серверах. Если все сделано правильно вариант «по умолчанию» будет наилучшим выбором.
Далее нас ждет этап настройки базы данных. Настраиваем базу по умолчанию, либо выбираем альтернативный вариант, а также обязательно проверяем, как она работает. После этого настраиваем отдельные элементы в составе нашего кластера и запускаем процесс настройки по выбранным параметрам. По завершению настройки можно переходить к экрану мониторинга кластера, куда выводятся все данные по входящим в кластер серверам.
Было полезно?
Почему?
😪 Мы тщательно прорабатываем каждый фидбек и отвечаем по итогам анализа. Напишите, пожалуйста, как мы сможем улучшить эту статью.
😍 Полезные IT – статьи от экспертов раз в неделю у вас в почте. Укажите свою дату рождения и мы не забудем поздравить вас.
Установка Hadoop на Windows
Администрирование › Установка Hadoop на Windows
- В этой теме 0 ответов, 1 участник, последнее обновление 11 месяцев, 1 неделя назад сделано Васильев Владимир Сергеевич.
Задача
Установить Hadoop на Windows
Решение
Для установки Hadoop у Вас должен быть установлен JDK не ниже версии 1.7 и настроена переменная окружения JAVA_HOME, указывающая на корневую директорию JDK.
1. Установка дистрибутива
Двоичный дистрибутив Hadoop можно скачать с официального сайта проекта по ссылке. Качаем версию 2.7.3 в виде архива hadoop-2.7.3.tar.gz.
Распаковываем полученный двоичный дистрибутив в выбранный для инсталяции каталог, например, C:\hadoop
Устанавливаем переменную окружения HADOOP_HOME, указывающую на папку распакованного дистрибутива (C\:hadoop\hadoop-2.7.3\)
Добавляем к переменной окружения Path путь к папке bin распакованного дистрибутива (C\:hadoop\hadoop-2.7.3\bin)
Устанавливаем переменную окружения HADOOP_CONF_DIR, указывающую на папку конфигурационных файлов распакованного дистрибутива (C\:hadoop\hadoop-2.7.3\etc\hadoop)
2. Конфигурация Hadoop
Редактируем файл C\:hadoop\hadoop-2.7.3\etc\hadoop\core-site.xml и указываем адрес файловой системы, используемой по-умолчанию
Редактируем файл настроек распределенной файловой системы C\:hadoop\hadoop-2.7.3\etc\hadoop\hdfs-site.xml . Добавляем в него коэффициент репликации (в случае локальной установки коэффицинт ставим 1). А так же указываем настройки директорий хранилища данных, обратите внимание на указание пути к директориям в формате принятом в Linux.
Редактируем файл исполнителя задач C\:hadoop\hadoop-2.7.3\etc\hadoop\mapred-site.xm и указываем, что задачи будут управляться менеджером YARN
Редактируем файл планировщика ресурсов YARN
C\:hadoop\hadoop-2.7.3\etc\hadoop\yarn-site.xm
3. Запуск Hadoop
Для запуска Hadoop под Windows необходимо заменить файлы утилит Hadoop предназначенные для Linux на файлы собранные для Windows (начиная, с версии 2.2 Hadoop позволяет делать такую сборку). Для этого качаем собранный пакет утилит WinUtils версии 2.7.1 c GitHub (например тут). Заменяем содержимое директории bin в установленном нами Hadoop на содержимое директории bin из WinUtils
Перед первым запуском Hadoop необходимо отформатировать распреленную файловую систему. Для этого выполняем команду файловой системы hdfs
SPBDEV Blog
Что такое Hadoop?
Hadoop — это проект Apache с открытым исходным кодом, написанный на Java и предназначенный для предоставления пользователям двух вещей: распределенной файловой системы (HDFS) и метода распределенных вычислений. Он основан на опубликованной в Google системе Google File System и MapReduce, в которой обсуждается, как создать инфраструктуру, способную выполнять интенсивные вычисления на тоннах компьютеров. Что-то, что возможно вы знаете, могло бы помочь создать гигантский индекс поиска. Прочтите описание проекта Hadoop и wiki для получения дополнительной информации и бэкграунда Hadoop.
В чем проблема в его запуске на Windows?
Основная цель Hadoop — обеспечить хранение и вычисление на множестве однородных типовых машин; обычно довольно внушительный компьютер под управлением Linux. С этой целью команда Hadoop логически сосредоточилась на платформах Linux в своей разработке и документации. Их Quickstart даже включает в себя предостережение, что «Win32 поддерживается как платформа разработки. Распределенная операция не была хорошо протестирована на Win32, поэтому это не производственная платформа. «Если вы хотите использовать Windows для запуска Hadoop в псевдораспределенном или распределенном режиме (более подробно об этих режимах чуть позже), вы остались в значительном меньшинстве. Теперь большинство людей, вероятно, не будут запускать Hadoop на производстве на машинах Windows, но возможность развертывания на самой широко используемой платформе в мире по-прежнему, вероятно, является хорошей идеей для того, чтобы позволить использовать Hadoop многим разработчикам, использующих Windows ежедневно.
Будьте бдительны
Я один из немногих, кто затратил время для установки фактической распределенной установки Hadoop в Windows. Я использовал его для некоторых успешных тестов разработки. Я не использовал это в производстве. Кроме того, хотя я могу обойтись в среде Linux / Unix, я не эксперт, поэтому некоторые из приведенных ниже советов могут быть неправильным способом настройки. Я также не специалист по безопасности. Если у кого-нибудь из вас есть исправления или советы для меня, пожалуйста, дайте мне знать в комментарии, и я исправлю это.
В этом руководстве используется Hadoop v0.17 и предполагается, что у вас нет предыдущей установки Hadoop. Я также сделал свою основную работу с Hadoop в Windows XP. Где я в курсе различий между XP и Vista, я пытался отметить их. Прокомментируйте, если что-то, что я написал, не подходит для Vista.
Итог: ваш опыт может отличаться, но это руководство должно помочь вам запустить Hadoop на Windows.
Небольшая заметка о распределенном Hadoop
Hadoop работает в одном из трех режимов:
- Автономный: все функции Hadoop работают в одном Java-процессе. Предполагает работу «из коробки» и тривиально используется на любой платформе, включая Windows.
- Псевдораспределенный: функциональность Hadoop работает на локальной машине, но различные компоненты будут работать как отдельные процессы. Это гораздо больше похоже на «настоящий» Hadoop и требует некоторой конфигурации, а также SSH. Однако он не разрешает распределенное хранение или обработку на нескольких компьютерах.
- Полностью распределенный: функциональность Hadoop распределяется по «кластеру» машин. Каждая машина участвует в несколько разных (и иногда перекрывающихся) ролях. Это позволяет нескольким машинам вносить в кластер мощности и ресурсы обработки.
Hadoop Quickstart может начать работу в автономном режиме и псевдораспределенном (в некоторой степени). Взгляните на него, если вы не готовы к полностью распределенному режиму. В этом руководстве основное внимание уделяется полностью распределенному режиму Hadoop. В конце концов, это самое интересное — где вы на самом деле делаете реальные распределенные вычисления.
Предпосылки
Я предполагаю, что если вы заинтересованы в запуске Hadoop, то вы знакомы с Java-программированием, и Java установлен на всех компьютерах, на которых вы хотите запустить Hadoop. Документы Hadoop рекомендуют Java 6 и требуют, по крайней мере, Java 5. Какой бы вариант вы ни выбрали, вам нужно убедиться, что на каждой машине установлена одна и та же основная версия Java (5 или 6). Кроме того, любой код, который вы пишете для работы с помощью MapReduce от Hadoop, должен быть скомпилирован с выбранной вами версией. Если у вас нет установленной Java, откройте ее и установите ее. Предположим, вы используете Java 6 в остальной части этого руководства.
Cygwin
Как я сказал во введении, Hadoop предполагает, что Linux (или ОС Unix) используется для запуска Hadoop. Это предположение довольно сильно устарело. Различные части Hadoop выполняются с использованием сценариев оболочки, которые будут работать только в оболочке Linux. Он также использует безопасную оболочку без пароля (SSH) для обмена данными между компьютерами в кластере Hadoop. Лучший способ сделать это в Windows — сделать Windows более похожим на Linux. Вы можете сделать это с помощью Cygwin, который предоставляет «Linux-подобную среду для Windows», которая позволяет использовать утилиты командной строки в стиле Linux, а также запускать действительно полезное программное обеспечение, ориентированное на Linux, такое как OpenSSH. Загрузите последнюю версию Cygwin. Пока не устанавливайте его. Ниже будет описано, как вам нужно установить.
Hadoop
Загрузите ядро Hadoop. Я пишу это руководство для версии 0.17, и я предполагаю, что вы используете ее.
Более одного ПК с ОС Windows в локальной сети
Вероятно, не стоит говорить, что, следуя этому руководству, вам нужно иметь более одного ПК. Я собираюсь предположить, что у вас есть два компьютера, и что они оба в вашей локальной сети. Назначьте одного главным (Master), а другой — подчиненным (Slave). Эти машины вместе станут вашим «кластером». Главный компьютер будет нести ответственность за обеспечение работы подчиненного компьютера (например, сохранение данных или выполнение заданий MapReduce). Главный компьютер также может выполнять свою часть этой работы. Если у вас более двух компьютеров, вы всегда можете настроить Slave2, Slave3 и так далее. Некоторые из приведенных ниже шагов должны быть выполнены на всех ваших кластерных машинах, а некоторые — только на Master или Slaves. Я отмечу, какие применяются для каждого шага.
Шаг 1. Настройте файл хостов (все машины)
Этот шаг не является абсолютно необходимым, но это облегчит вашу жизнь в будущем, если ваши компьютеры изменят IP-адреса. Это также поможет вам держать вещи прямо в голове при редактировании файлов конфигурации. Откройте файл хостов Windows, расположенный в каталоге c:\windows\system32\drivers\etc\hosts (файл с именем hosts без расширения) в текстовом редакторе и добавьте следующие строки (заменив NNN на IP-адреса и Master, и Slave):
master NNN.NNN.NNN.NNN
slave NNN.NNN.NNN.NNN
Шаг 2: Установите Cygwin и настройте OpenSSH sshd (все машины)
Cygwin имеет немного странный процесс установки, поскольку он позволяет выбирать библиотеки полезных программ и утилит Linux-y, которые вы хотите установить. В этом случае мы действительно устанавливаем Cygwin для запуска сценариев оболочки и OpenSSH. OpenSSH — это реализация сервера защищенной оболочки (SSH) (sshd) и клиента (ssh). Если вы не знакомы с SSH, вы можете думать об этом как о безопасной версии telnet. С помощью команды ssh вы можете войти на другой компьютер, на котором запущен sshd, и работать с ним из командной строки. Вместо того, чтобы изобретать колесо, я расскажу вам пошаговые инструкции о том, как установить Cygwin в Windows и запустить SSH-сервер OpenSSH. Вы можете остановиться после инструкции 6. Как и в связанных инструкциях, я предположу, что вы установили Cygwin в c:\cygwin, хотя вы можете установить его в другом месте.
Если вы используете брандмауэр на своем компьютере, вам нужно убедиться, что порт 22 открыт для входящих соединений SSH. Как всегда с брандмауэрами, откройте минимальный доступ к своей машине. Если вы используете брандмауэр Windows, убедитесь, что открытый порт привязан к вашей локальной сети. У Microsoft есть документация о том, как сделать все это с брандмауэром Windows (прокрутите вниз до раздела «Настройка исключений для портов»).
Шаг 3: Настройка SSH (все машины)
Hadoop использует SSH, чтобы позволить главному компьютеру (-ам) в кластере запускать и останавливать процессы на подчиненных компьютерах. Одна из приятных особенностей SSH заключается в поддержке нескольких режимов безопасной аутентификации: вы можете использовать пароли или использовать общедоступные / закрытые ключи для подключения без паролей («без пароля»). Hadoop требует, чтобы вы установили SSH для выполнения последнего. Я не буду подробно разбираться в том, как все это работает, но достаточно сказать, что нужно сделать следующее:
- Создайте пару открытого ключа для вашего пользователя на каждой машине кластера.
- Обменяйтесь открытым ключом каждого пользователя машины с каждым другим пользователем машины в кластере.
Создание пар закрытых / закрытых ключей
Чтобы создать пару ключей, откройте Cygwin и выполните следующие команды ($> — это командная строка):
$> ssh-keygen -t dsa -P » -f
Теперь вы можете использовать SSH на своем локальном компьютере, используя следующую команду:
При запросе пароля введите его. На вашем терминале Cygwin вы увидите что-то вроде следующего .
Last login: Sun Jun 8 19:47:14 2008 from localhost
Чтобы выйти из сеанса SSH и вернуться на обычный терминал, используйте:
Обязательно сделайте это на всех компьютерах вашего кластера.
Обмен открытыми ключами
Теперь, когда у вас есть открытые и закрытые пары ключей на каждой машине в вашем кластере, вам нужно поделиться своими открытыми ключами, чтобы разрешить вход без пароля с одной машины на другую. После того, как машина имеет открытый ключ, она может безопасно аутентифицировать запрос с удаленного компьютера, который зашифрован с использованием закрытого ключа, который соответствует этому открытому ключу.
На главном компьютере следующая команда в cygwin (где « » — это имя пользователя, которое вы используете для входа в Windows на подчиненном компьютере):
Введите пароль при появлении запроса. Это скопирует ваш файл открытого ключа, который будет использоваться на главном устройстве.
В подчиненном устройстве введите следующую команду в cygwin:
Это добавит ваш открытый ключ к набору разрешенных ключей, которые подчиненное устройство принимает для целей аутентификации.
Вернемся к главному компьютеру, проверьте это, выполнив следующую команду в cygwin:
Если все хорошо, вы должны войти в подчиненный компьютер без необходимости пароля.
Повторите этот процесс в обратном порядке, скопировав открытый ключ подчиненного на главный. Кроме того, обязательно обменивайтесь открытыми ключами между мастером и любыми другими ведомыми устройствами, которые могут находиться в вашем кластере.
Настройте SSH для использования имен пользователей по умолчанию (необязательно)
Если все ваши кластерные машины используют одно и то же имя пользователя, вы можете спокойно пропустить этот шаг. Если нет, читайте дальше.
В большинстве руководств Hadoop предлагается настроить пользователя для Hadoop. Если вы хотите это сделать, вы, безусловно, сможете. Зачем настраивать конкретного пользователя для Hadoop? Ну, в дополнение к тому, чтобы быть более защищенным от прав доступа к файлам и безопасности, когда Hadoop использует SSH для выдачи команд с одной машины на другую, он автоматически попытается войти в систему на удаленном компьютере с использованием того же пользователя, что и текущий компьютер. Если у вас разные пользователи на разных машинах, регистрация SSH, выполняемая Hadoop, не удастся. Однако большинство из нас в Windows обычно используют наши компьютеры с одним пользователем и, вероятно, предпочли бы не устанавливать нового пользователя на каждой машине только для Hadoop.
Способ позволить Hadoop работать с несколькими пользователями — это настроить SSH для автоматического выбора соответствующего пользователя, когда Hadoop выдает команду SSH. (Вам также нужно будет отредактировать файл конфигурации hadoop-env.sh, но это будет описано далее в этом руководстве.) Вы можете сделать это, отредактировав файл с именем «config» (без расширения), расположенный в том же «.ssh», где вы сохранили свои общедоступные и закрытые ключи для аутентификации. Cygwin хранит этот каталог в разделе “c:\cygwin\home\ \.ssh”.
На главном файле создайте файл config и добавьте следующие строки (заменив « » на имя пользователя, которое вы используете на подчиненной машине:
Если у вас больше подчиненных в кластере, добавьте также строки для хоста и пользователя.
На каждом подчиненном устройстве создайте файл с именем config и добавьте следующие строки (заменив “ ” на имя пользователя, которое вы используете на главной машине:
Теперь проверьте это. На хозяине перейдите в cygwin и выполните следующую команду:
Вы должны автоматически войти в подчиненную машину без имени пользователя и пароля. Не забудьте выйти из сеанса ssh.
Для получения дополнительной информации о формате этого конфигурационного файла и о том, что он делает, запустите man ssh_config в cygwin.
Шаг 4: Извлечение Hadoop (Все машины)
Если вы не загрузили Hadoop 0.17, сделайте это сейчас. Файл будет иметь расширение «.tar.gz», которое не может быть понято Windows. Вам понадобится что-то вроде WinRAR, чтобы извлечь его. (Если кто-то знает что-то проще, чем WinRAR для извлечения tar-gzip-файлов в Windows, оставьте комментарий.)
Когда у вас есть утилита для извлечения, извлеките ее непосредственно в c:\cygwin\usr\local. (Предполагая, что вы установили Cygwin в c: \ cygwin, как описано выше).
Выбранная папка будет называться hadoop-0.17.0. Переименуйте ее в hadoop. Все дальнейшие шаги предполагают, что вы находитесь в этом каталоге hadoop и будете использовать соответствующие пути для файлов конфигурации и сценариев оболочки.
Шаг 5: Настройка hadoop-env.sh (Для всех машин)
Файл conf/hadoop-env.sh — это сценарий оболочки, который устанавливает различные переменные среды, которые Hadoop должен выполнить. Откройте conf/hadoop-env.sh в текстовом редакторе. Найдите строку, начинающуюся с «#export JAVA_HOME». Измените эту строку на следующее:
export JAVA_HOME=c:\\Program\ Files\\Java\\jdk1.6.0_06
Это должен быть домашний каталог вашей установки Java. Обратите внимание, что вам нужно удалить ведущий символ «#» (комментарий), и вам нужно избежать обратных косых черт и пробелов с помощью обратного слэша.
Затем найдите строку, которая начинается с «#export HADOOP_IDENT_STRING». Измените его на следующее:
Где MYHADOOP может быть любым, с чем вы хотите идентифицировать свой кластер Hadoop. Просто убедитесь, что каждая машина в вашем кластере использует одно и то же значение.
Чтобы проверить эти изменения, выполните следующие действия в cygwin:
Вы должны увидеть результат, аналогичный этому:
Subversion http://svn.apache.org/repos/asf/hadoop/core/branches/branch-0.17 -r 656523
Compiled by hadoopqa on Thu May 15 07:22:55 UTC 2008
Если вы видите такой вывод:
bin/hadoop: line 166: c:\Program Files\Java\jdk1.6.0_05/bin/java: No such file or directory
bin/hadoop: line 251: c:\Program Files\Java\jdk1.6.0_05/bin/java: No such file or directory
bin/hadoop: line 251: exec: c:\Program Files\Java\jdk1.6.0_05/bin/java: cannot execute: No such file or directory
Это означает, что ваш домашний каталог Java неверен. Вернитесь назад и убедитесь, что вы указали правильный каталог и использовали соответствующее экранирование.