Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
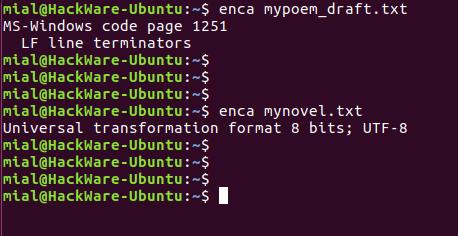
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
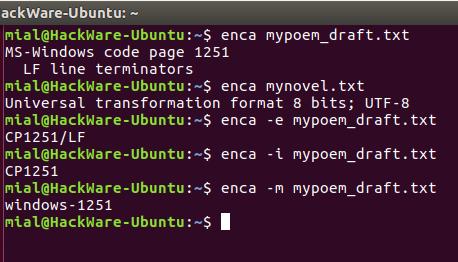
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
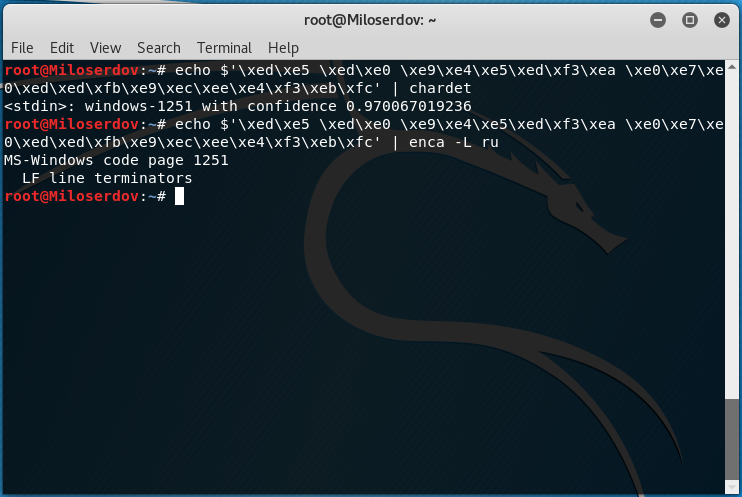
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
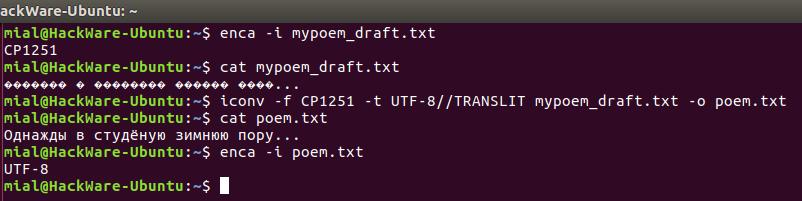
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
Урок 9
Кодирование текстовой информации
§ 2.1. Кодирование текстовой информации
Содержание урока
Практическая работа 2.1

Практическая работа 2.1
Кодирование текстовой информации
 Аппаратное и программное обеспечение. Компьютер с установленной операционной системой Windows или Linux.
Аппаратное и программное обеспечение. Компьютер с установленной операционной системой Windows или Linux.
Цель работы. Научиться определять числовые коды символов и осуществлять перекодировку русскоязычного текста в текстовом редакторе.
Задание 1. В текстовом редакторе определить числовые (шестнадцатеричные) коды нескольких символов в кодировке Unicode <Юникод).
Задание 2. В текстовом редакторе Hieroglyph представить слово «Кодировка» в пяти различных кодировках: Windows, MS-DOS, КОИ-8, Mac, ISO.

 Задание 1. Определение числового кода символа с помощью текстовых редакторов Microsoft Word и OpenOffice.org Writer
Задание 1. Определение числового кода символа с помощью текстовых редакторов Microsoft Word и OpenOffice.org Writer
1. В операционной системе Windows запустить текстовый редактор Microsoft Word командой [Пуск — Все программы — Microsoft Office — Microsoft Word] или текстовый редактор OpenOffice.org Writer командой [Пуск — Все программы — OpenOffice — OpenOffice Writer].
в операционной системе Linux запустить текстовый редактор OpenOffice.org Writer командой [Пуск — Офис — OpenOffice Writer].
 Определим числовой код символа в текстовом редакторе Microsoft Word.
Определим числовой код символа в текстовом редакторе Microsoft Word.
2. В текстовом редакторе Microsoft Word ввести команду [Вставка — Символ — Другие символы. ]. На экране появится диалоговое окно Символы. Центральную часть диалогового окна занимает фрагмент таблицы символов.
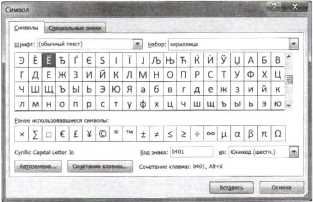
3. Для определения числового кода знака кириллицы с помощью раскрывающегося списка Набор: выбрать пункт кириллица.
4. Для определения шестнадцатеричного числового кода символа в кодировке Unicode с помощью раскрывающегося списка из: выбрать тип кодировки Юникод (шести.).
5. В таблице символов выбрать символ (например, заглавную букву «Ё»). В текстовом поле Код знака: появится его шестнадцатеричный числовой код (в данном случае 0401).
Перевод числового кода символа из шестнадцатеричной системы счисления в десятичную систему счисления можно осуществить с помощью программного калькулятора NumLock Calculator.
Определим числовой код символа в текстовом редакторе OpenOffice.org Writer.
6. В текстовом редакторе OpenOffice.org Writer ввести команду [Вставка — Специальные символы. ]. На экране появится диалоговое окно Выбор символа. Центральную часть диалогового окна занимает фрагмент таблицы символов.

7. Для определения числового кода знака кириллицы с помощью раскрывающегося списка Набор выбрать пункт Кириллица.
8. В таблице символов выбрать символ (например, заглавную букву «Ё»). В правом нижнем углу диалогового окна появится его шестнадцатеричный числовой код (в данном случае 0401).
Перевод числового кода символа из шестнадцатеричной системы счисления в десятичную систему счисления можно осуществить с помощью программного калькулятора KCalc.
Задание 2. Перекодирование русскоязычного текста в текстовом редакторе Hieroglyph
Текстовый редактор Иероглиф является на сегодняшний день единственным редактором серьезно ориентированным на работу с русскими текстами с таким обширным набором функций (порядка 30) при совсем небольшом размере (порядка 3 MB в архиве). Иероглиф может использоваться как редактор по умолчанию вместо Notepad и Wordpad. Иероглиф является хорошим дополнением к Microsoft Word. Иероглиф также заменит вам все ваши программы перекодировки, работы с испорченной почтой, работы с UNICODE и решит все проблемы русификации.
Загрузить текстовый редактор Иероглиф:
✑ С сайта Hieroglyph Web Page.
✑ Скачать архив установочных файлов (Hieroglyph.zip) редактора.
1. В операционной системе Windows запустить текстовый редактор Hieroglyph командой [Пуск — Все программы — Hieroglyph].
2. В раскрывающемся списке исходных кодировок выбрать кодировку WIN и ввести текст: «Кодировка Windows».
3. Скопировать текст четыре раза.
Последовательно выделить строки, выбрать для каждой конечную кодировку в раскрывающемся списке (DOS, ISO, KOI и Mac), нажать кнопку Перевод кодировки.
Для каждой кодировки отредактировать ее название.
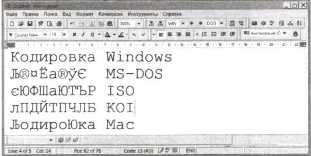
4. В результате получим пять строк символов в различных кодировках, где первое слово в каждой строке соответствует одной и той же последовательности числовых кодов.
Cкачать материалы урока