Изучаем Информатику. 2 тема. Кодирование информации
Одно из основных достоинств компьютера связано с тем, что это удивительно универсальная машина. Каждый, кто хоть когда-нибудь с ним сталкивался, знает, что занятие арифметическими подсчетами составляет совсем не главный метод использования компьютера. Компьютеры прекрасно воспроизводят музыку и видеофильмы, с их помощью можно организовывать речевые и видеоконференции в Интернете, создавать и обрабатывать графические изображения и и.д
Человек выражает свои мысли в виде предложений, составленных из слов. Они являются алфавитным представлением информации. Основу любого языка составляет алфавит — конечный набор различных знаков (символов) любой природы, из которых складывается сообщение.
Одна и та же запись может нести разную смысловую нагрузку. Например, набор цифр 251299 может обозначать: массу объекта; длину объекта; расстояние между объектами; номер телефона; запись даты 25 декабря 1999 года.
Для представления информации могут использоваться разные коды и, соответственно, надо знать определенные правила — законы записи этих кодов, т.е. уметь кодировать.
Код — набор условных обозначений для представления информации.
Кодирование — процесс представления информации в виде кода.
Для общения друг с другом мы используем код — русский язык. При разговоре этот код передается звуками, при письме — буквами. Водитель передает сигнал с помощью гудка или миганием фар. Вы встречаетесь с кодированием информации при переходе дороги в виде сигналов светофора. Таким образом, кодирование сводиться к использованию совокупности символов по строго определенным правилам.
Кодировать информацию можно различными способами: устно; письменно; жестами или сигналами любой другой природы.
Способ кодирования (форма представления) информации зависит от цели, ради которой осуществляется кодирование. Такими целями могут быть сокращение записи, засекречивание (шифровка) информации, удобство обработки и т. п.
Чаще всего применяют следующие способы кодирования информации:
1) графический — с помощью рисунков или значков;
2) числовой — с помощью чисел:
3) символьный с помощью символов того же алфавита, что и исходный текст.
Переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки, также называют кодированием .
Действия по восстановлению первоначальной формы представления информации принято называть декодированием . Для декодирования надо знать код.
Кодирование текстовой информации
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Для хранения двоичного кода одного символа выделен 1 байт = 8 бит.
Учитывая, что каждый бит принимает значение 0 или 1, количество их возможных сочетаний в байте равно 28 = 256. Значит, с помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов. Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т.д.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду.
Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице. Кодирование текстовой информации с помощью байтов опирается на несколько различных стандартов, но первоосновой для всех стал стандарт ASCII (American Standart Code for Information Interchange), разработанный в США в Национальном институте ANSI (American National Standarts Institute). В системе ASCII закреплены две таблицы кодирования — базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 33 кода (с 0 до 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и т. д.).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, т.е. в национальных кодировках одному и тому же коду соответствуют различные символы. В настоящее время существует много различных кодовых таблиц для русских букв (КОИ-8, СР1251, СР866, Mac, ISO),поэтому тексты, созданные в одной кодировке , могут не правильно отображаться в другой.
Кодирование графической информации
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые, в свою очередь, содержат определенное количество точек (пикселей). Каждому пикселю присвоен код, хранящий информацию о цвете пикселя.
Для получения черно-белого изображения (без полутонов) пиксель может принимать только два состояния: “белый” или “черный”. Тогда для его кодирования достаточно 1 бита:
Пиксель на цветном дисплее может иметь различную окраску. Поэтому 1 бита на пиксель – недостаточно.
Для кодирования 4-цветного изображения требуется два бита на пиксель, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов:
00 – черный 10 – зеленый
01 – красный 11 – коричневый
Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого, синего. Из трех цветов можно получить восемь комбинаций:
Следовательно, для кодирования 8-цветного изображения требуется три бита памяти на один пиксель.
Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности, тогда количество различных вариантов их сочетаний, дающих разные краски и оттенки, увеличивается.
Шестнадцатицветная палитра получается при использовании 4-разрядной кодировки пикселя: к трем битам базовых цветов добавляется один бит интенсивности. Этот бит управляет яркостью всех трех цветов одновременно.
Пиши комментарии, ставьте лайки, подписывайтесь на канал
Если символы отображаются неправильно в TextEdit на Mac
По умолчанию в программе TextEdit используется автоматическая кодировка текста для отображения документов. Если символы отображаются неверно, попробуйте выбрать другую кодировку при открытии файла.
Выбор другой кодировки для одного документа
В программе TextEdit  на Mac выберите меню «Файл» > «Открыть», затем выберите файл (не открывайте его).
на Mac выберите меню «Файл» > «Открыть», затем выберите файл (не открывайте его).
Нажмите «Параметры» в левом нижнем углу окна.
Нажмите всплывающее меню «Кодировка простого текста» и выберите кодировку.
Если в списке нет нужной кодировки, выберите «Настройка списка кодировок», затем выберите кодировки, которые нужно включить в список.
Выбор другой кодировки для всех документов
В программе TextEdit на Mac выберите меню «TextEdit» > «Настройки», затем нажмите «Открытие и сохранение».
Нажмите всплывающее меню «Открытие файлов» (в разделе «Кодировка простого текста») и выберите кодировку.
Приводим русские тексты на Mac OS X в одну кодировку Python-скриптом
Случилось мне иметь ноут на OS X, комп на Linux и одного из друзей с Windows. И вот через dropbox обмениваются все эти три компа документами разными. В том числе и текстовыми, в которых хранятся разные заметки, задачи и т.п. И вот незадача: тексты написанные на MacOSx плохо читаются в блокноте Винды, а виндовые в textedit на MacOSx.
И вся причина в том, что на винде блокнот использует кодировку Windows 1251, а на OS X используется по умолчанию MACCYRILLIC. Причем обе программы без проблем работают с UTF-8 кодировкой.
Вот только конвертировать из одной кодировки в другую как-то неудобно, лишнее время тратить на открытие терминала и набор заветных команд iconv…
Пораздумав, написал небольшой скрипт, который сам определяет используемую кодировку и конвертирует в UTF-8 все txt-файлы.
Что использую для всего:
Python 2.7
Mac OS X 10.7.5
PyCharm IDE
Изначально сделал определение кодировки самостоятельно, без дополнительных модулей. Но по совету ad3w решил переписать с использованием готового модуля chardet для определения кодировки.
Кому интересно, предыдущий
Определение происходит простым перебором кодировок и выбором той, в которой не будет лишних символов. А набор символов определяете Вы. Конечно этот способ не подойдет для файлов с DOS-графикой, но в обычных целях использования txt его вполне хватит.
Скачиваем модуль chardet 1.1,
Распаковываем и устанавливаем:
Создаем свой скрипт для перекодировки файлов:
Далее необходимо сделать удобным запуск данного скрипта прямо из папки в OS X.
Открываем Automator и создаем Службу.
Вверху выбираем пункты, чтобы получилось «Служба получает файлы и папки в Finder.app».
Далее ставим действие «получить выбранные объекты Finder».
Далее «Запустить Shell-скрипт» в настройках его «Передать ввод: как аргументы» и в нем содержание:
Дописал 2>/dev/null, чтобы автоматор не останавливал выполнение при выводе ошибки модуля chardet.
И последний пункт «Show Growl Notification» (в нем можно написать, что конвертация произведена). 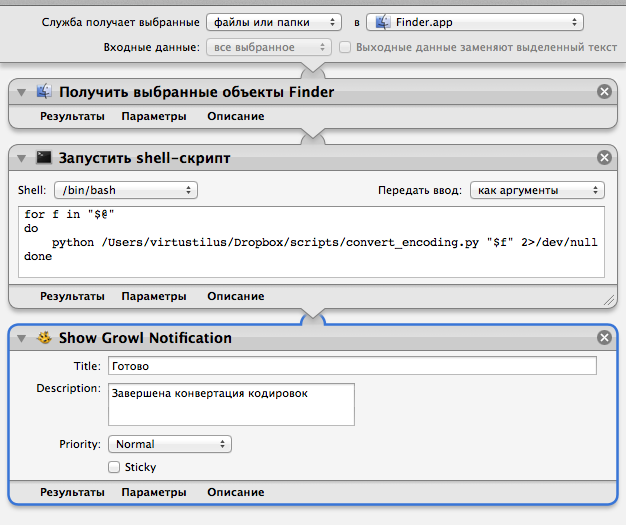
Сохраняем с именем латинскими буквами (с русскими у меня почему-то пункт в меню не появлялся, пока не переименовал) и проверяем.
Новый пункт меню появится в Finder в меню файлов и папок в подменю Сервисы.