Урок 17
§14. Кодирование текстовой информации
Содержание урока:

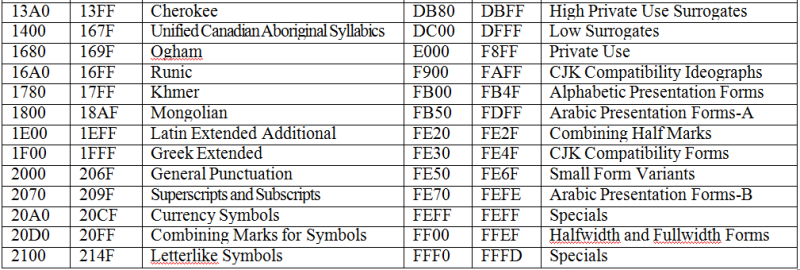
 | 14.1. Кодировка ASCII и её расширения |  |
| Кодирование текстовой информации |  | 14.2. Стандарт Unicode |
14.1. Кодировка ASCII и её расширения
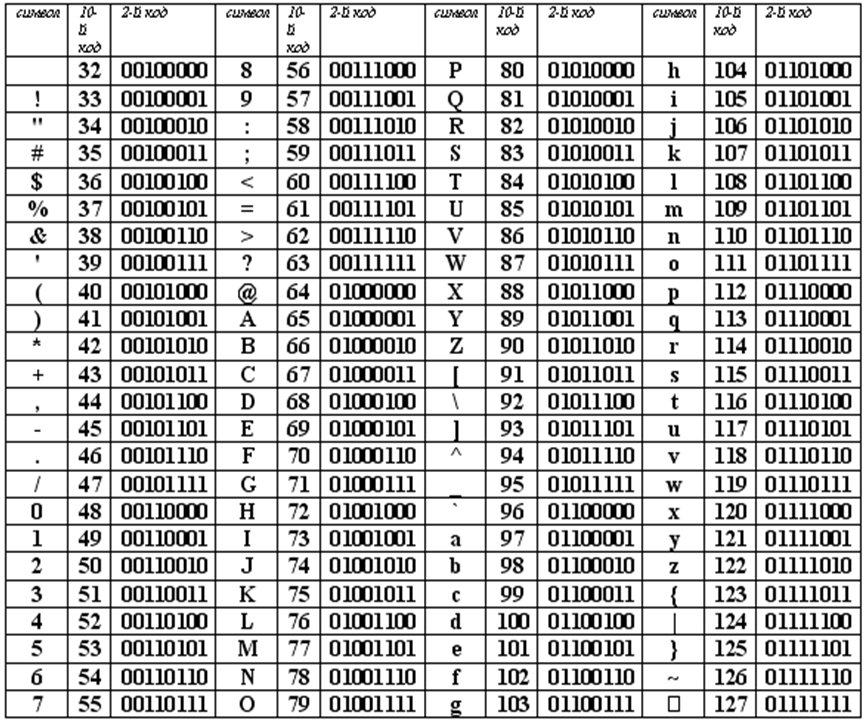
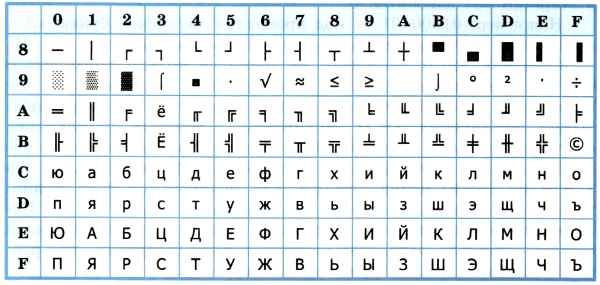
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.). Этот код 7-битовый: общее количество символов составляет 2 7 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII
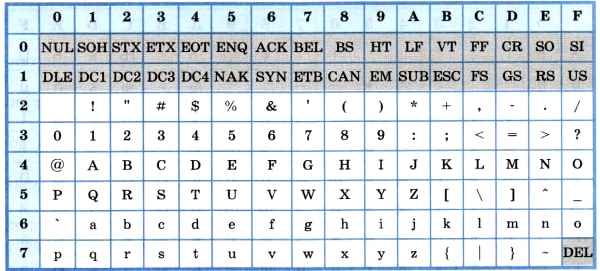
Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Стандарт ASCII рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII -кодировки, в которых применялись однобайтовые коды символов. При этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано несколько вариантов кодовых таблиц (например, для русского языка их было создано около десятка!).
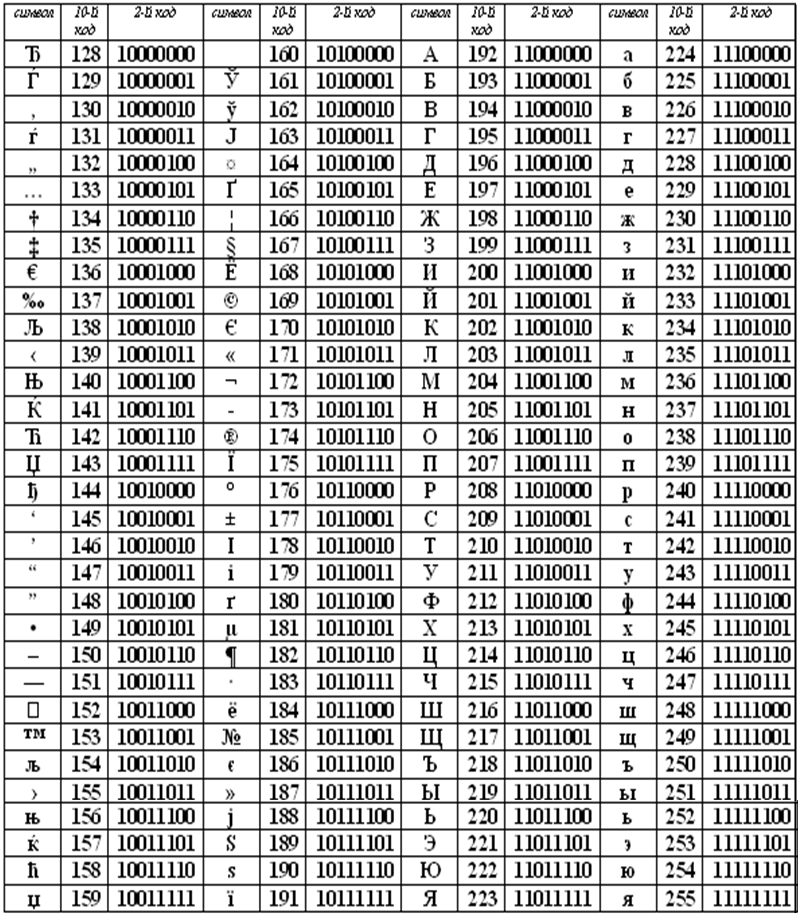
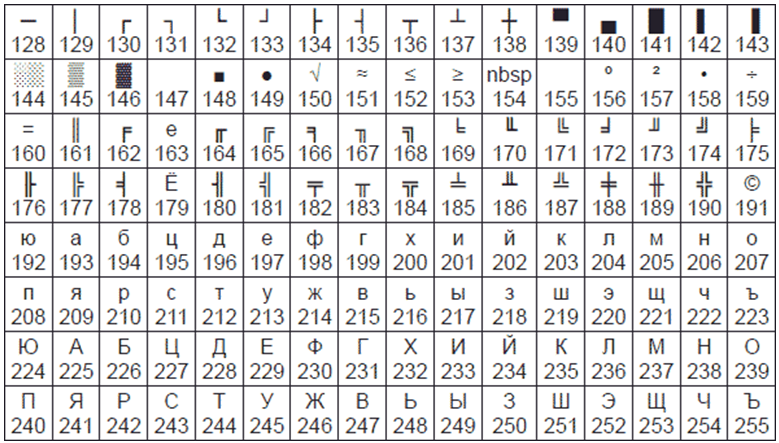
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10). В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251
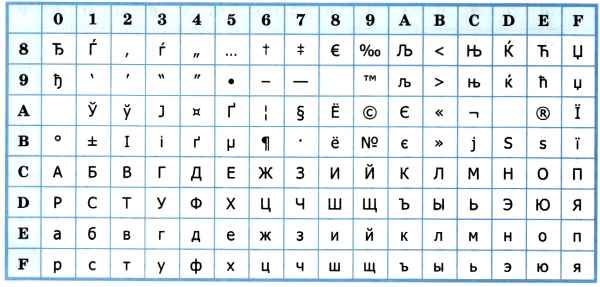
Таблица 3.10
Кодировка КОИ-8
Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах. Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов. Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
Cкачать материалы урока
Урок 12
Представление нечисловой информации в компьютере
 |  |  |
|
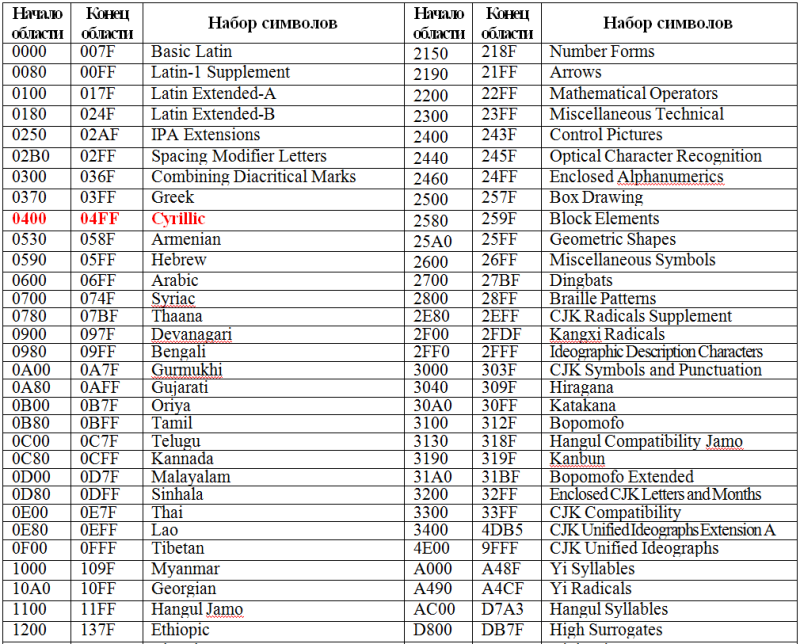
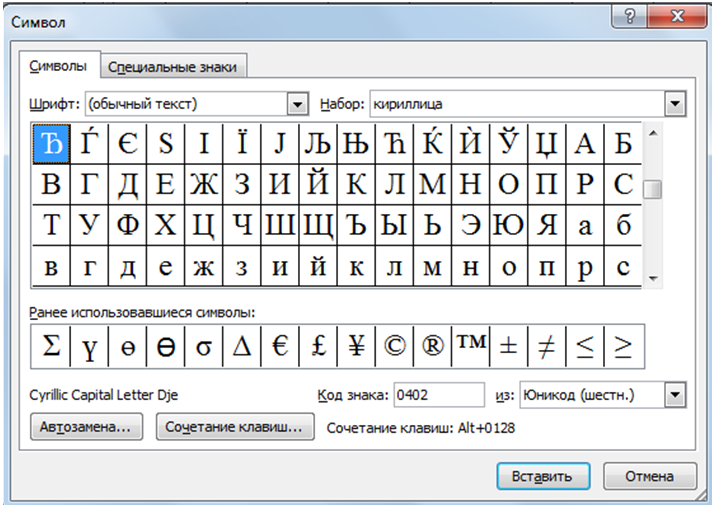
Представление текстовой информации в компьютереИзучив эту тему, вы узнаете и повторите: — как в компьютере представляется текстовая информация; Компьютеры не с самого рождения могли обрабатывать символьную информацию. Лишь с конца 60-х годов они стали использоваться для обработки текстов и в настоящее время большинство пользователей ПК занимаются вводом, редактированием и форматированием текстовой информации. 1. Таблица кодирования ASCII.А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация. Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью. Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 2 в 8 степени равно 256. 8 битов = 1 байт, следовательно: Один символ в компьютерном тексте занимает 1 байт памяти. Как мы выяснили, традиционно для кодирования одного символа используется 8 бит. И, когда люди определились с количеством бит, им осталось договориться о том, каким кодом кодировать тот или иной символ, чтобы не получилось путаницы, т.е. необходимо было выработать стандарт – все коды символов сохранить в специальной таблице кодов. В первые годы развития вычислительной техники таких стандартов не существовало, а сейчас наоборот, их стало очень много, но они противоречивы. Первыми решили эти проблемы в США, в институте стандартизации. Этот институт ввел в действие таблицу кодов ASCII (AmericanStandardCodeforInformationInterchange – стандартный код информационного обмена США). Рассмотрим таблицу кодов ASCII. Пояснение: раздать учащимся распечатанную таблицу кодов ASCII. Таблица ASCII разделена на две части. Первая – стандартная – содержит коды от 0 до 127. Вторая – расширенная – содержит символы с кодами от 128 до 255. Первые 32 кода отданы производителям аппаратных средств и называются они управляющие, т.к. эти коды управляют выводом данных. Им не соответствуют никакие символы. Коды с 32 по 127 соответствуют символам английского алфавита, знакам препинания, цифрам, арифметическим действиям и некоторым вспомогательным символам. Коды расширенной части таблицы ASCII отданы под символы национальных алфавитов, символы псевдографики и научные символы. Стандартная часть таблицы кодов ASCII Если вы внимательно посмотрите на обе части таблицы, то увидите, что все буквы расположены в них по алфавиту, а цифры – по возрастанию. Этот принцип последовательного кодирования позволяет определить код символа, не заглядывая в таблицу. Коды цифр берутся из этой таблицы только при вводе и выводе и если они используются в тексте. Если же они участвуют в вычислениях, то переводятся в двоичную систему счисления. Коды национального (русского) алфавита расширенной частитаблицы ASCII Альтернативные системы кодирования кириллицы.Тексты, созданные в одной кодировке, не будут правильно отображаться в другой.В настоящее время для поддержки букв русского алфавита (кириллицы) существует несколько кодовых таблиц (кодировок), которые используются различными операционными системами, что является существенным недостатком и в ряде случаев при-водит к проблемам, связанным с операциями декодирования числовых значений символов. Для разных типов ЭВМ используются различные кодировки: В настоящее время существует 5 кодовых таблиц для русских букв: Windows (СР(кодовая страница)1251), MS – DOS (СР(кодовая страница)866), KOИ – 8 (Код обмена информацией, 8-битный) (используется в OS UNIX), Mac (Macintosh), ISO (OS UNIX). Одним из первых стандартов кодирования кириллицы на компьютерах был стан-дарт КОИ-8. Национальная часть кодовой таблицы стандарта КОИ8-Р В настоящее время применяется и кодовая таблица, размещенная на странице СР866 стандарта кодирования текстовой информации, которая используется в операционной системе MS DOS или сеансе работы MS DOS для кодирования кириллицы. Национальная часть кодовой таблицы СР866 В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица, размещенная на странице СР1251 соответствующего стандарта, которая используется в операционных системах семейства Windows фирмы Microsoft. Национальная часть кодовой таблицы СР1251 Во всех представленных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит). В мире существует примерно 6800 различных языков. Если прочитать текст, напечатанный в Японии на компьютере в России или США, то понять его будет нельзя. Чтобы буквы любой страны можно было читать на любом компьютере, для их кодировки стали использовать 2 байта (16 бит). Основополагающая таблица использования кодового пространства Unicode Использование Unicode значительно упрощает создание многоязычных документов, публикаций и программных приложений. Рассмотрим примеры. 1) Представьте в форме шестнадцатеричного кода слово «ЭВМ» во всех пяти кодировках. Воспользуемся компьютерным калькулятором для перевода чисел из десятичной в шестнадцатеричную систему счисления. Последовательности десятичных кодов слова «ЭВМ» в различных кодировках составляем на основе кодировочных таблиц: Переводим с помощью калькулятора последовательности кодов из десятичной системы в шестнадцатеричную: 2) Определить числовой код символа в кодировке Unicode с помощью тексто-вого редактора MicrosoftWord. 1. В операционной системе Windows запустить текстовый редактор MicrosoftWord. 2. В текстовом редакторе MicrosoftWord ввести команду [Вставка-Символ…]. На экране появится диалоговое окно Символ. Центральную часть диалогового окна занимает фрагмент таблицы символов. 3. Для определения числового кола знака кириллицы с помощью раскрывающегося списка Набор: выбрать пункт кириллица. 4. Для определения шестнадцатеричного числового кода символа в кодировке Unicode с помощью раскрывающегося списка из: выбрать тип кодировки Юникод (шестн.). 5. В таблице символов выбрать символ Э. В текстовом поле кодзнака : появится его шестнадцатеричный числовой код (в данном случае 042D). Решите задачи:№1. Закодируйте с помощью таблицы ASCII слова: А) Excel; Б) Access; В) Windows; Г) ИНФОРМАЦИЯ. №2. Буква «i» в таблице кодов имеет код 105. Не пользуясь таблицей, расшифруйте следующую последовательность кодов: 102, 105, 108, 101. №3. Десятичный код буквы «е» в таблице ASCII равен 101. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову help. №4. Десятичный код буквы «i» в таблице ASCII равен 105. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову link. №5. Декодируйте следующие тексты, заданные десятичным кодом: №6. Во сколько раз увеличится информационный объем страницы текста при его преобразовании из кодировки Windows 1251 (таблица кодировки содержит 256 символов) в кодировку Unicode (таблица кодировки содержит 65536 символов)? №7. Каков информационный объем текста, содержащего слово ПРОГРАММИРОВАНИЕ: №8. Текст занимает ¼ Кбайта. Какое количество символов он содержит? №9. Текст занимает полных 6 страниц. На каждой странице размещается 30 строк по 80 символов. Определить объем оперативной памяти, который займет этот текст. №10. Свободный объем оперативной памяти компьютера 320 Кбайт. Сколько страниц книги поместится в ней, если на странице: №11. Текст занимает 20 секторов на двусторонней дискете объемом 360 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст? |