Команда wc в Linux
Анализ файлов — неотъемлемая часть работы с ними. Иногда возникает необходимость подсчитать количество строк или слов в тексте. С этой задачей эффективно справляется команда wc Linux.
Утилита устанавливается по умолчанию практически во всех дистрибутивах GNU/Linux. В этой статье рассмотрим её функции и применение на практике.
Синтаксис команды wc
Для запуска утилиты откройте терминал и введите:
Терминал будет ожидать ввода данных. После нажатия комбинации клавиш Ctrl + D командный интерпретатор завершит работу программы и выведет три числа, обозначающих количество строк, слов и байт введённой информации.
Утилита может обрабатывать файлы. Стандартная инструкция выглядит так:
- wc — имя утилиты;
- file — название обрабатываемого файла.
Программа также может принимать параметры для анализа отдельных значений. Наиболее используемые из них приведены в таблице ниже:
| Параметр | Длинный вариант | Значение |
| -c | —bytes | Отобразить размер объекта в байтах |
| -m | —count | Показать количесто символов в объекте |
| -l | —lines | Вывести количество строк в объекте |
| -w | —words | Отобразить количество слов в объекте |
Под объектом следует понимать файл или данные, полученные на стандартный поток ввода.
Команда может обработать несколько файлов, если указать их через пробел или выбрать по шаблону.
Применение команды wc
Обработка стандартного потока ввода с завершением через Ctrl + D:

Согласно анализу, было введено 4 строки, содержащих 5 слов, объёмом в 35 байт.
Перенаправление потока вывода на вход wc:

Обработка всех файлов с расширением .sh в текущем каталоге:

В конце выводится итоговая информация, суммирующая значения для каждого столбца.
Выведем только количество символов и строк двух файлов:
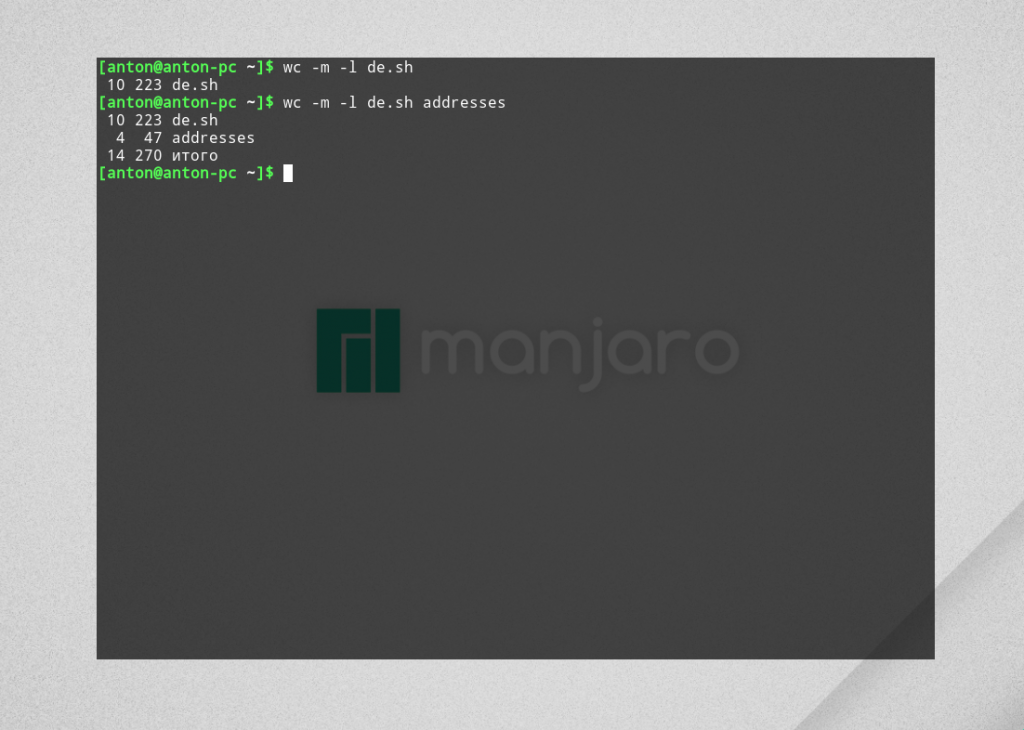
Обратите внимание: порядок указания параметров не влияет на итоговый вид информации. Программа всегда выводит данные в виде СТРОК — СЛОВ — БАЙТ (СИМВОЛОВ) [— ФАЙЛ]. Если какой-то параметр будет отсутствовать, его столбец просто проигнорируется, не задевая остальные. Количество символов будет стоять первым, если в команде содержался и вывод байт.
Вывод
Команда wc Linux является эффективным инструментом при анализе файлов в GNU/Linux. Она может обрабатывать как стандартный поток ввода, так и несколько файлов одновременно. Для извлечения конкретных данных используются параметры командной строки.
Команда wc в Linux
Для анализа файлов в Линуксе часто используют команду wc. Она считать количество строк, слов, букв в тексте.
Синтаксис
wc [параметры] [файлы]
- -с — показывает размер в байтах;
- -m — считает количество символом в документе;
- -l — считает количество строк в документе;
- -L — показывает длину наибольшей строки в документе;
- -w — количество слов в документе;
- —help — показывает справочную информацию;
- —version — информация о версии.
Примеры
Сосчитаем сколько байт в файле под названием «file». Для этого будем использовать ключ «-с».

Запустим утилиту без опций, укажем только название файла.

Команда без параметров сосчитала сколько строк, слов, байтов и название файла.
- первая цифра 13 — количество строк;
- вторая цифра 13 — количество слов;
- 37 — количество байт;
- file — название документа.
Выведем на экран количество слов в документе «test». Для этого будем использовать аргумент -w.
Опция -w считает слова вместе с пробелами.
Подсчитаем строки в документе test. Будем использовать опцию -l.

Часто в операционной системе Linux средствами терминала нужно узнать сколько пользователей зарегистрировано. С этой задачей легко справится утилита wc. Список пользователей хранится в файле passwd, необходимо только сосчитать их.
Команда wc в Linux

В этой статье мы покажем вам, как использовать команду wc в Linux, на простых и практичных примерах.
Как использовать команду Wc
Синтаксис команды wc следующий:
Команда wc может принимать ноль или более входных имен FILE. Если FILE не указан или если FILE установлен -, wc будет читать стандартный ввод. Слово – это строка символов, разделенных пробелом, символом табуляции или новой строкой.
В простейшей форме, когда она используется без каких-либо опций, команда wc напечатает четыре столбца, количество строк, слов, количество байтов и имя файла для каждого указанного файла. Если файлы не указаны, (при использовании стандартного ввода) имя файла не отображается.
Следующая команда отобразит информацию о виртуальном файле /proc/cpuinfo:
Вывод будет выглядеть примерно так:
356 – это количество строк, 2956 – это количество слов, а 19946 – это количество символов.
При использовании стандартного ввода имя файла не отображается:
Чтобы отобразить информацию о нескольких файлах, передайте имена файлов в качестве аргументов через пробел:
Команда предоставит вам информацию о каждом файле и строке, включая общую статистику:
Параметры ниже позволяют вам выбрать, какие счетчики будут напечатаны.
- -l, –lines- Распечатать количество строк.
- -w, –words- Распечатать количество слов.
- -m, –chars- Распечатать количество символов.
- -c, –bytes- Вывести количество байтов.
- -L, –max-line-length- Вывести длину самой длинной строки.
При использовании нескольких опций счетчик печатается в следующем порядке: новая строка, слова, символы, байты, максимальная длина строки.
Например, для отображения только того количества слов, которое вы бы использовали:
Вот еще один пример, который напечатает количество строк и длину самой длинной строки.
Опция –files0-from=F позволяет wc читать входные данные из файлов, указанных NUL-прерванных имен в файле F. Если F есть, -то читать имена из стандартного ввода. Например, вы можете искать файлы с помощью команды find и предоставлять эти файлы в качестве входных данных для wc:
Вывод покажет количество строк для всех файлов в каталоге /etc, имена которых начинаются с «host»:
Примеры команд wc
Команда wc обычно используется в сочетании с другими командами через |. Вот несколько примеров.
Подсчет файлов в текущем каталоге
Команда find передает список всех файлов в текущем каталоге с каждым именем файла в одной строке команде wc, которая считает количество строк и печатает результат:
Подсчитать количество пользователей
В приведенном ниже примере wc используется для подсчета количества строк в выходных данных команды getent.
Заключение
К настоящему времени вы должны хорошо понимать, как использовать команду wc в Linux.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Подсчет количества вхождений слова в текстовом файле

Когда вы работаете с текстовым файлом в графическом редакторе, то можно увидеть количество вхождений слова, используя статистику, если она предоставляется редактором или, например, нажать Ctrl+F и увидеть количество найденных вхождений.
Иногда нужно выполнить подсчет вхождений слова или символов в файле, используя командую строку. Рассмотрим, как это можно сделать.
Используем grep | wc
Предположим, что у нас есть файл myfile.txt со следующим содержимым:
Воспользуемся командой grep и найдем вхождение слова « текст » в файле myfile.txt :
В результате будет выведено:
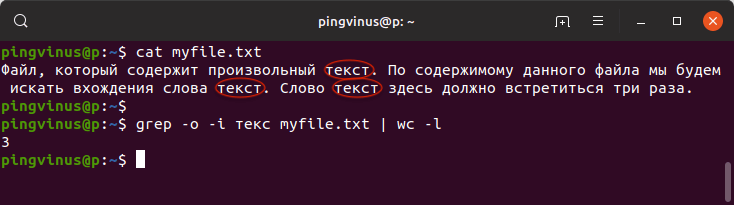
Описание команды:
Команда grep выполняет поиск слова « текст » в файле myfile.txt .
Опция -i — игнорировать регистр символов.
Опция -o — используется, чтобы возвращалось само найденное слово. Каждое найденное слово выводится на отдельной строке (в нашем случае каждое слово передается команде wc ).
Далее вывод команды grep направляется команде wc , так как используется оператор вертикальной черты | (конвейер).
Команда wc (от «word count») с опцией -l выполняет подсчет количества строк. То есть в нашем случае количество, найденных командной grep , слов.
Используем tr | grep
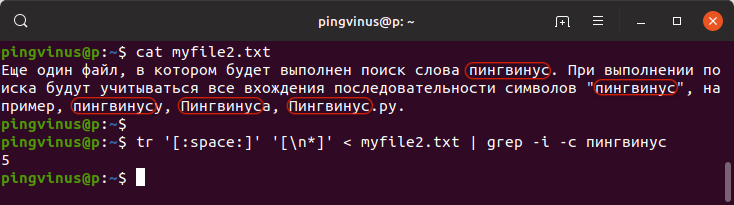
Для разнообразия воспользуемся еще одной командой, которая также выполняет подсчет количества вхождений строки в текстовом файле:
В результате будет выведено:
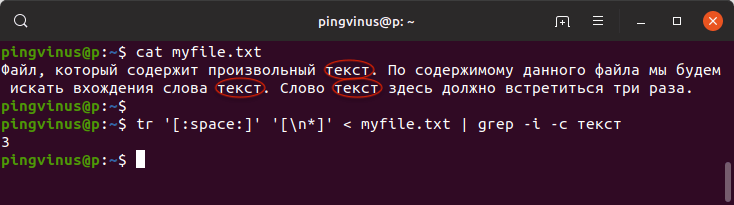
Описание команды:
Мы воспользовались командой tr (от «translate» или «transliterate»), которая используется для преобразования одних символов в другие. В нашем случае мы командной tr разбиваем файл на строки: все пробельные символы ( [:space:] ) заменяются на символ новой строки ( [\n*] ) .
Затем вывод команды tr направляется команде grep , так как используется конвейер |
Опция -c команды grep считает количество строк.
Еще один пример
Обращаю внимание на то, что описанные выше команды, ищут не отдельное слово, а именно вхождение слова (вхождение символов) в тексте. То есть, если в тексте встречается строка вида « Это хорошие помидоры », и мы ищем вхождение слова « помидор », то получим в результате одно вхождение, так как в нашем тексте есть эти символы.
Приведем пример. Выполним поиск в следующем файле:
В результате будет выведено:
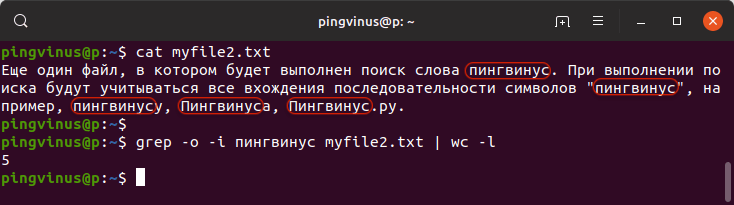
Аналогично командой tr
В результате будет выведено:
Заключение
Мы рассмотрели, как можно посчитать количество вхождений определенных символов в текстовом файле, используя командую строку. Вы также познакомились с некоторыми возможностями команд grep , wc и tr , и перенаправлением результата одной команды на вход другой — конвейером |