Одминский блог
Блог о технологиях, технократии и методиках борьбы с граблями
Смена кодировки сайта из CP1251 на UTF-8
Перевозил тут пачку сайтов с LAMP на LNAMP, где фронтэндом выступает NGINX. И все бы ничего, если бы не пачка статических сателлитов в кодировке Windows-1251 (cp1251).
Как тут прикололся девака – при анализе сайта, надо сначала чекать кодировку и в случае обнаружения кодировки сайта cp1251 – проверку возраста можно не осуществлять. Но, тем не менее, в инетах до сих пор встречаются такие мастадонты, которые клепают сайты в кодировке CP1251.
Под апачем, при добавлении сайта в ISP Panel это даже не заметишь, а вот при попытке добавить этот же сайт в Vesta CP, получаешь гемор на задницу с крикозябрами. Поэтому надо редактировать конфиг Nginx, предварительно прикрутив туда виндовую кодировку. Но, насколько я помню, у меня этот танец с бубнами не задался и в тот раз, я просто повесил саты на LAMP.
Так что оставалось либо плясать с бубнами вокруг прикручивания виндовой кодировки к NGINX, либо перекодивать файлы в родную для нжинкса UTF-8. Сделать это можно средствами текстового редактора Notepad++ путем перевода кодировки документа и последующего сохранения; либо же в самом линухе. Как я выше заметил, саты статические, то есть на файлах, без использования базы данных. Поэтому перекодировать надо было именно файлы. С базой данных все происходило бы несколько иначе.
Перекодировка файла из CP1251 в UTF-8 производится в консоли через команду iconv
# iconv -f cp1251 -t utf8 FILE-CP1251 -o FILE-UTF8
либо же можно переписать файл в самого себя
# iconv -f cp1251 -t utf8 file.txt -o file.txt
Но поскольку мне надо было перекодировать большое число файлов php, содержащихся в разных папках, то мне пришлось составить небольшое предложение:
# find /path-to-files/ -type f -name \*php -exec iconv -f cp1251 -t utf-8 ‘<>‘ -o ‘<>‘ \;
Конвертит все в лет.
Для конвертации кодировок есть еще утилита enconv, входящая в состав пакета enca – вот он как раз конвертит сам в себя по умолчанию, перезаписывая файл выходной кодировкой:
# enconv -c file.txt
но, к сожалению, я его не смог подружить с русским языком, т.к даже при указании языка через ключик -L russian скрипт матерился на ошибки. Но с другой стороны, все нормально решилось и через iconv
Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
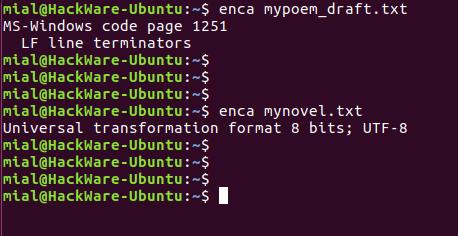
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
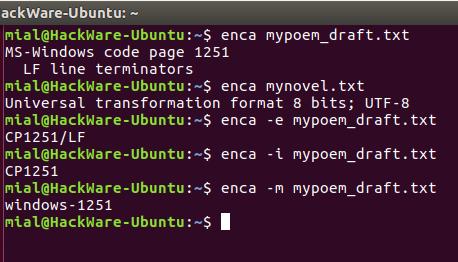
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
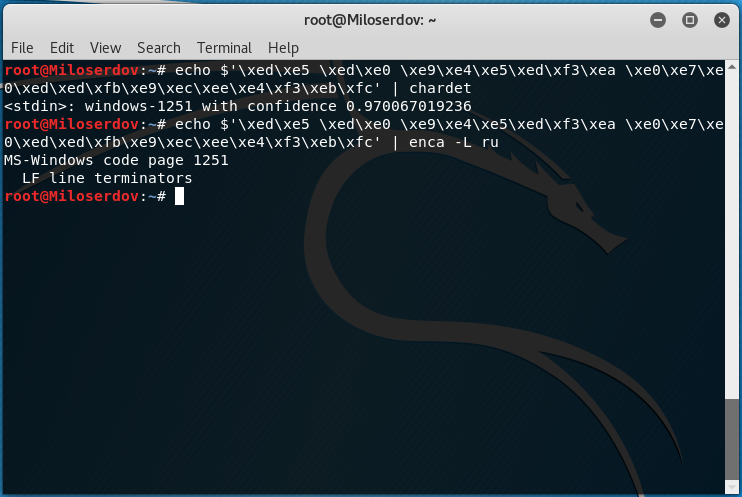
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
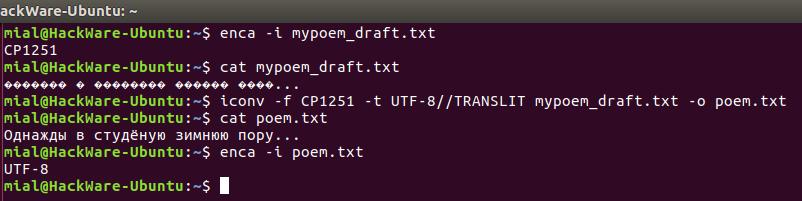
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
Как: Определить и Изменить Кодировку Файла
Linux администраторы, работающие с веб-хостингом, знают насколько важно хранить html документы в правильной кодировке.
Из этой статьи вы узнаете, как определить кодировку файла из командной строки в Linux.
А также, вы познакомитесь с лучшим решением для конвертации текста между различными кодировками.
Дополнительно я приведу примеры конвертации текста между такими наиболее распространенными кодировками, как CP1251 (Windows-1251, Кириллица), UTF-8 , ISO-8859-1 и ASCII .
Дельный Совет: Хотите видеть родной язык в Linux терминале? Просто поменяйте локаль! Читать далее →
Определить Кодировку Файла
Используйте следующую команду, чтобы узнать какая кодировка используется в файле:
| Опция | Описание |
|---|---|
| -b , —brief | Не печатать имя файла (краткий режим) |
| -i , —mime | Определить тип файла и кодировку |
Определить кодировку файлы in.txt :
Изменить Кодировку Файла
Используйте следующую команду для изменения кодировки файла:
| Опция | Описание |
|---|---|
| -f , —from-code | Изменить с кодировки |
| -t , —to-code | Изменить на кодировку |
| -o , —output | Сохранить результат в файл |
Изменить кодировку файла с CP1251 (Windows-1251, Кириллица) на UTF-8 :
Изменить кодировку файла с ISO-8859-1 на UTF-8 и сохранить результат в out.txt :
Изменить кодировку файла с ASCII на UTF-8 :
Изменить кодировку файла с UTF-8 на ASCII :
Illegal input sequence at position: Поскольку UTF-8 может содержать символы которые не конвертируются в ASCII, iconv будет генерировать сообщение об ошибке «Illegal input sequence at position«, пока вы не скажете пропускать все неконвертируемые в ASCII символы, с помощью опции -c .
| Опция | Описание |
|---|---|
| -c | Исключить из вывода недопустимые символы |
Вы можете потерять символы: Обратите внимание, что используя iconv с опцией -c некоторые символы могут быть потеряны.
В частности, это касается Windows машин с Кириллицей.
Вы скопировали какой-то файл с Windows в Linux, но при его открытии в Linux, вы видите “Êàêèå-òî êðàêîçÿáðû” – Что за … !?
Без паники — подобные строки могут быть быть легко преобразованы из кодировки CP1251 (Windows-1251, Кириллица) в UTF-8 с помощью:
Список Всех Кодировок
Перечислить все известные кодировки:
| Опция | Описание |
|---|---|
| -l , —list | Список всех известных кодировок |
7 Replies to “Как: Определить и Изменить Кодировку Файла”
Thank you very much. Your reciept helped a lot!
I am running Linux Mint 18.1 with Cinnamon 3.2. I had some Czech characters in file names (e.g: Pešek.m4a). The š appeared as a ? and the filename included a warning about invalid encoding. I used convmv to convert the filenames (from iso-8859-1) to utf-8, but the š now appears as a different character (a square with 009A in it. I tried the file command you recommended, and got the answer that the charset was binary. How do I solve this? I would like to have the filenames include the correct utf-8 characters.
Thanks for your help—
Вообще-то есть 2 утилиты для определения кодировки. Первая этo file. Она хорошо определяет тип файла и юникодовские кодировки… А вот с ASCII кодировками глючит. Например все они выдаются как буд-то они iso-8859-1. Но это не так. Тут надо воспользоваться другой утилитой enca. Она в отличие от file очень хорошо работает с ASCII кодировками. Я не знаю такой утилиты, чтобы она одновременно хорошо работала и с ASCII и с юникодом… Но можно совместить их, написав свою. Это да. Кстати еnca может и перекодировать. Но я вам этого не советую. Потому что лучше всего это iconv. Он отлично работает со всеми типами кодировок и даже намного больше, с различными вариациями, включая BCD кодировки типа EBCDIC(это кодировки 70-80 годов, ещё до ДОСа…) Хотя тех систем давно нет, а файлов полно… Я не знаю ничего лучше для перекодировки чем iconv. Я думаю всё таки что file не определяет ASCII кодировки потому что не зарегистрированы соответствующие mime-types для этих кодировок… Это плохо. Потому что лучшие кодировки это ASCII.
Для этого есть много причин. И я не знаю ни одной разумной почему надо пользоваться юникодовскими кроме фразы «США так решило…» И навязывают всем их, особенно эту utf-8. Это худшее для кодирования текста что когда либо было! А главная причина чтобы не пользоваться utf-8, а пользоваться ASCII это то, что пользоваться чем-то иным никогда не имеет смысла. Даже в вебе. Хотите значки? Используйте символьные шрифты, их полно. Не вижу проблем… Почему я должен делать для корейцев, арабов или китайцев? Не хочу. Мне всегда хватало русского, в крайнем случае английского. Зачем мне ихние поганые языки и кодировки? Теперь про ASCII. KOI8-R это вычурная кодировка. Там русские буквы идут не по порядку. Нормальных только 2: это CP1251 и DOS866. В зависимости от того для чего. Если для графики, то безусловно CP1251. А если для полноценной псевдографики, то лучше DOS866 не придумали. Они не идеальны, но почти… Плохость utf-8 для русских текстов ещё и в том, что там каждая буква занимает 2 байта. Там ещё такая фишка как во всех юникодах это indian… Это то, в каком порядке идут байты, вначале младший а потом старший(как в памяти по адресам, или буквы в словах при написании) или наоборот, как разряды в числе, вначале старшие а потом младшие. А если символ 3-х, 4-х и боле байтов(до 16-ти в utf-8) то там кол-во заморочек растёт в геометрической прогрессии! Он ещё и тормозит, ибо каждый раз надо вычислять длину символа по довольно сложному алгоритму! А ведь нам ничего этого не надо! Причём заметьте, ихние англицкие буквы идут по порядку, ничего не пропущено и все помещаются в 1-м байте… Т.е. это искусственно придуманые штуки не для избранных америкосов. Их это вообще не волнует. Они разом обошли все проблемы записав свой алфавит в начало таблицы! Но кто им дал такое право? А все остальные загнали куда подальше… Особенно китайцев! Но если использовать CP1251, то она работает очень быстро, без тормозов и заморочек! Так же как и английские буквы…
а вот дальше бардак. Правда сейчас нам приходится пользоваться этим utf-8, Нет систем в которых бы системная кодировка была бы ASCII. Уже перестали делать. И все файлы системные именно в uft-8. А если ты хочешь ASCII, то тебе придётся всё время перекодировать. Раньше так не надо было делать. Надеюсь наши всё же сделают свою систему без ихних штатовких костылей…
Уважаемый Анатолий, огромнейшее Вам спасибо за упоминание enca. очень помогла она мне сегодня. Хотя пост Ваш рассистский и странный, но, видимо, сильно наболело.