Справочная информация
про свой опыт решения некоторых проблем и использования ряда возможностей ОС и приложений
понедельник, 4 февраля 2019 г.
Автоопределение кодировки в xed (Linux Mint)

По умолчанию текстовый редактор xed не осуществляет определения кодировки текста. В результате чего при открытии текстовых файлов, набранных в Блоноте Windows имеется следующая картина:
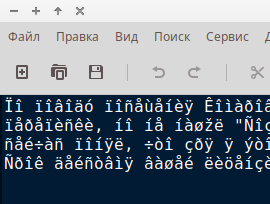
Чтобы текст отображался нормально выполните в терминале одну из двух команд, указанных ниже. Если команда не соответствует, то терминал выдаст какое-либо сообщение. При правильной команде терминал после некоторого «размышления» вернётся к состоянию готовности к приёму команд.
Для Linux Mint xfce 18.3 и 19.* вводить вторую команду.
gsettings set org.x.editor auto-detected-encodings «[‘UTF-8’, ‘WINDOWS-1251’, ‘KOI8-R’, ‘CP866’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]»
gsettings set org.x.editor.preferences.encodings auto-detected «[‘UTF-8’, ‘WINDOWS-1251’, ‘KOI8-R’, ‘CP866’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]»
При открытии проблемного файла снова вопрос с повестки дня был снят.
Linux Mint Forums
Welcome to the Linux Mint forums!
Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by Zeppelin250 » Sat Feb 25, 2017 12:54 pm

Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by Chocobo » Sun Feb 26, 2017 4:55 pm
Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by Olej » Fri Apr 21, 2017 7:47 am
Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by motordig » Tue Jan 08, 2019 1:15 pm
[‘UTF-8’, ‘WINDOWS-1251’, ‘KOI8-R’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by bgdnvs » Mon Apr 01, 2019 7:29 am
Re: так я tty-консоли русифицировал от кракозябров
Post by Labuzhskiy » Sun Jun 30, 2019 6:19 am
Для русификации консолей tty Линукс, по завершении русификации интерфейса по-умолчанию,
необходимо выполнить ряд не сложных манипуляций:
1. Приводим файл /etc/default/console-setup к виду:
labuzhskiy@MINT-LIN-CIN-X64
$ cat /etc/default/console-setup
# CONFIGURATION FILE FOR SETUPCON
# Consult the console-setup(5) manual page.
CODESET=»CyrSlav»
FONTFACE=»Fixed»
FONTSIZE=»8×16″
# The following is an example how to use a braille font
# FONT=’lat9w-08.psf.gz brl-8×8.psf’
2. Выявив местоположение файла rc.local в операционной системе (стандартный путь /etc/rc.local либо /etc/init.d/rc.local), дописываем в него следующие строки:
setfont CyrSlav
DAEMON_LOCALE= «yes»
можно так:
sudo -s
echo ‘setfont CyrSlav’ >> /etc/init.d/rc.local && echo ‘DAEMON_LOCALE=»yes»‘ >> /etc/init.d/rc.local
пример конфигов NanoPC-T4 здесь
Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by altRUist » Sat Apr 11, 2020 7:31 pm
Проблема с кодировкой текстового редактора Xed

Установил mint 18 и файлы открываются с кракозябрами, попробовал сделать следующее
gsettings set org.x.editor auto-detected-encodings «[‘UTF-8’, ‘WINDOWS-1251’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]»
Результата никакого нет, открывается также со знаками вопроса. Что еще можно сделать?
| dex tor: |
| Что еще можно сделать? |
1. Прежде всего нужно установить (если не установлен) редактор конфигурации dconf
2. Затем в редакторе dconf перейти по пути: org -> x -> editor -> auto-datedted-encodings
3. В auto-datedted-encodings добавить в список кодировок следующую строку — «WINDOWS-1251» (поместить её в списке второй по счету).
ПС. На форме уже была тема по данной проблеме.
| VALENTINUS: |
| 1. Прежде всего нужно установить (если не установлен) редактор конфигурации dconf 2. Затем в редакторе dconf перейти по пути: org -> x -> editor -> auto-datedted-encodings 3. В auto-datedted-encodings добавить в список кодировок следующую строку — «WINDOWS-1251» (поместить её в списке второй по счету). |
Ну как-бы если ты посмотришь то я тоже самое и сделал только через консоль. Проблема не решилась
Есть еще один способ —
//Заходим в директорию с нашим файлом.
//Вправляем мозги на место.
| Ocean: |
| Друзья, помогите решить проблему с кодировкой в документах созданных в винде, но открытых в Минте 18 встроенным текстовым редактором Xed. Русский вообще крякозябрами отображается. С Gedit решение нашел, но по Xed вообще нет информации. Решаем проблему с кодировкой текстового редактора Gedit в Ubuntu и Pluma в Linux Mint |
Cтавим dconf-editor и делаем так, как на фото
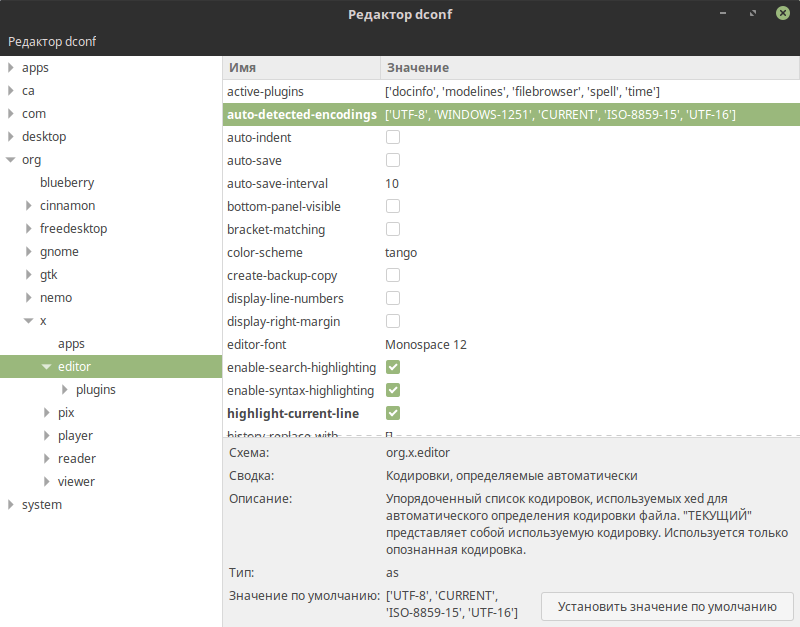 | 20161210163730_88ub1.png | 81,29 Кб | Скачали: 1342 |
| dex tor: |
| Всем привет |
Установил mint 18 и файлы открываются с кракозябрами, попробовал сделать следующее
gsettings set org.x.editor auto-detected-encodings «[‘UTF-8’, ‘WINDOWS-1251’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]»
Результата никакого нет, открывается также со знаками вопроса. Что еще можно сделать?
Ставим dconf-editor и делаем по фото
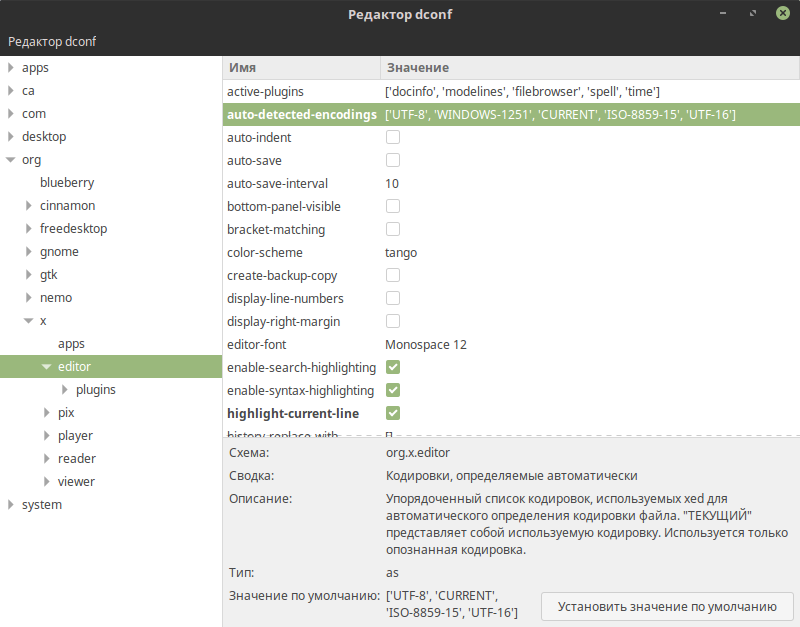 | 20161210163730_88ub1.png | 81,29 Кб | Скачали: 1011 |
Ставим dconf-editor и делаем по фото
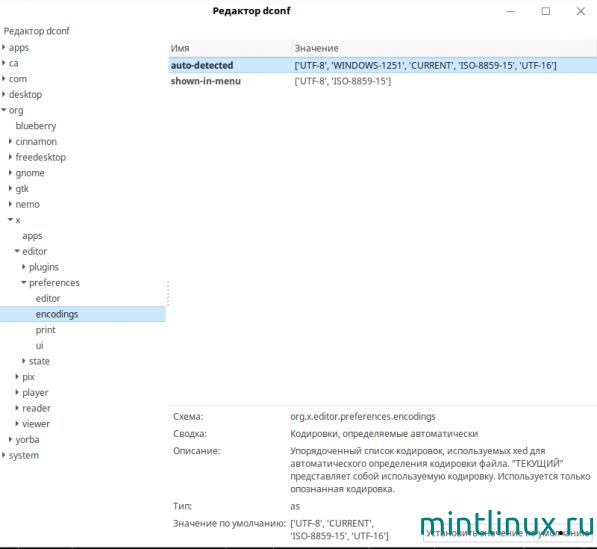
Мне помогла команда в терминале от простого юзера :
gsettings set org.x.editor.preferences.encodings auto-detected «[‘UTF-8’, ‘WINDOWS-1251’, ‘KOI8-R’, ‘CP866’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]»
После этого закрыть xed, открыть его заново и усё работает. Достаточно одно таблЭтки, и никаких танцев с бубнами 
Минт 18.03 (Сильва) х64 с корицей
Как: Определить и Изменить Кодировку Файла
Linux администраторы, работающие с веб-хостингом, знают насколько важно хранить html документы в правильной кодировке.
Из этой статьи вы узнаете, как определить кодировку файла из командной строки в Linux.
А также, вы познакомитесь с лучшим решением для конвертации текста между различными кодировками.
Дополнительно я приведу примеры конвертации текста между такими наиболее распространенными кодировками, как CP1251 (Windows-1251, Кириллица), UTF-8 , ISO-8859-1 и ASCII .
Дельный Совет: Хотите видеть родной язык в Linux терминале? Просто поменяйте локаль! Читать далее →
Определить Кодировку Файла
Используйте следующую команду, чтобы узнать какая кодировка используется в файле:
| Опция | Описание |
|---|---|
| -b , —brief | Не печатать имя файла (краткий режим) |
| -i , —mime | Определить тип файла и кодировку |
Определить кодировку файлы in.txt :
Изменить Кодировку Файла
Используйте следующую команду для изменения кодировки файла:
| Опция | Описание |
|---|---|
| -f , —from-code | Изменить с кодировки |
| -t , —to-code | Изменить на кодировку |
| -o , —output | Сохранить результат в файл |
Изменить кодировку файла с CP1251 (Windows-1251, Кириллица) на UTF-8 :
Изменить кодировку файла с ISO-8859-1 на UTF-8 и сохранить результат в out.txt :
Изменить кодировку файла с ASCII на UTF-8 :
Изменить кодировку файла с UTF-8 на ASCII :
Illegal input sequence at position: Поскольку UTF-8 может содержать символы которые не конвертируются в ASCII, iconv будет генерировать сообщение об ошибке «Illegal input sequence at position«, пока вы не скажете пропускать все неконвертируемые в ASCII символы, с помощью опции -c .
| Опция | Описание |
|---|---|
| -c | Исключить из вывода недопустимые символы |
Вы можете потерять символы: Обратите внимание, что используя iconv с опцией -c некоторые символы могут быть потеряны.
В частности, это касается Windows машин с Кириллицей.
Вы скопировали какой-то файл с Windows в Linux, но при его открытии в Linux, вы видите “Êàêèå-òî êðàêîçÿáðû” – Что за … !?
Без паники — подобные строки могут быть быть легко преобразованы из кодировки CP1251 (Windows-1251, Кириллица) в UTF-8 с помощью:
Список Всех Кодировок
Перечислить все известные кодировки:
| Опция | Описание |
|---|---|
| -l , —list | Список всех известных кодировок |
7 Replies to “Как: Определить и Изменить Кодировку Файла”
Thank you very much. Your reciept helped a lot!
I am running Linux Mint 18.1 with Cinnamon 3.2. I had some Czech characters in file names (e.g: Pešek.m4a). The š appeared as a ? and the filename included a warning about invalid encoding. I used convmv to convert the filenames (from iso-8859-1) to utf-8, but the š now appears as a different character (a square with 009A in it. I tried the file command you recommended, and got the answer that the charset was binary. How do I solve this? I would like to have the filenames include the correct utf-8 characters.
Thanks for your help—
Вообще-то есть 2 утилиты для определения кодировки. Первая этo file. Она хорошо определяет тип файла и юникодовские кодировки… А вот с ASCII кодировками глючит. Например все они выдаются как буд-то они iso-8859-1. Но это не так. Тут надо воспользоваться другой утилитой enca. Она в отличие от file очень хорошо работает с ASCII кодировками. Я не знаю такой утилиты, чтобы она одновременно хорошо работала и с ASCII и с юникодом… Но можно совместить их, написав свою. Это да. Кстати еnca может и перекодировать. Но я вам этого не советую. Потому что лучше всего это iconv. Он отлично работает со всеми типами кодировок и даже намного больше, с различными вариациями, включая BCD кодировки типа EBCDIC(это кодировки 70-80 годов, ещё до ДОСа…) Хотя тех систем давно нет, а файлов полно… Я не знаю ничего лучше для перекодировки чем iconv. Я думаю всё таки что file не определяет ASCII кодировки потому что не зарегистрированы соответствующие mime-types для этих кодировок… Это плохо. Потому что лучшие кодировки это ASCII.
Для этого есть много причин. И я не знаю ни одной разумной почему надо пользоваться юникодовскими кроме фразы «США так решило…» И навязывают всем их, особенно эту utf-8. Это худшее для кодирования текста что когда либо было! А главная причина чтобы не пользоваться utf-8, а пользоваться ASCII это то, что пользоваться чем-то иным никогда не имеет смысла. Даже в вебе. Хотите значки? Используйте символьные шрифты, их полно. Не вижу проблем… Почему я должен делать для корейцев, арабов или китайцев? Не хочу. Мне всегда хватало русского, в крайнем случае английского. Зачем мне ихние поганые языки и кодировки? Теперь про ASCII. KOI8-R это вычурная кодировка. Там русские буквы идут не по порядку. Нормальных только 2: это CP1251 и DOS866. В зависимости от того для чего. Если для графики, то безусловно CP1251. А если для полноценной псевдографики, то лучше DOS866 не придумали. Они не идеальны, но почти… Плохость utf-8 для русских текстов ещё и в том, что там каждая буква занимает 2 байта. Там ещё такая фишка как во всех юникодах это indian… Это то, в каком порядке идут байты, вначале младший а потом старший(как в памяти по адресам, или буквы в словах при написании) или наоборот, как разряды в числе, вначале старшие а потом младшие. А если символ 3-х, 4-х и боле байтов(до 16-ти в utf-8) то там кол-во заморочек растёт в геометрической прогрессии! Он ещё и тормозит, ибо каждый раз надо вычислять длину символа по довольно сложному алгоритму! А ведь нам ничего этого не надо! Причём заметьте, ихние англицкие буквы идут по порядку, ничего не пропущено и все помещаются в 1-м байте… Т.е. это искусственно придуманые штуки не для избранных америкосов. Их это вообще не волнует. Они разом обошли все проблемы записав свой алфавит в начало таблицы! Но кто им дал такое право? А все остальные загнали куда подальше… Особенно китайцев! Но если использовать CP1251, то она работает очень быстро, без тормозов и заморочек! Так же как и английские буквы…
а вот дальше бардак. Правда сейчас нам приходится пользоваться этим utf-8, Нет систем в которых бы системная кодировка была бы ASCII. Уже перестали делать. И все файлы системные именно в uft-8. А если ты хочешь ASCII, то тебе придётся всё время перекодировать. Раньше так не надо было делать. Надеюсь наши всё же сделают свою систему без ихних штатовких костылей…
Уважаемый Анатолий, огромнейшее Вам спасибо за упоминание enca. очень помогла она мне сегодня. Хотя пост Ваш рассистский и странный, но, видимо, сильно наболело.