Нагрузка на диски в Linux

Для измерения текущей нагрузки на диски (что происходит, кто куда копирует и прочее) в Linux можно использовать iotop (и здесь же lsof) и iostat. А для тестирования возможностей дисковой системы fio. Несмотря на то, что первое, о чем можно подумать в плане попугаев — это IOPS или же Мб/сек за чтение или запись, обратите внимание на время ожидания. Примерно как если бы вы стояли в очереди в кассу: вас обслужили бы за 2 минуты, но очередь может быть минут на 30. И со стороны наблюдателя ваш процесс обслуживания будет «висеть». Именно так могут ощущать себя клиенты сервера, если время ожидания будет намного превышать время выполнения конкретной задачи. Поэтому определение длинной очереди и задержек часто бывает более важным, чем знать, что ваш диск «вау, может писать 400 Мбит/с». Нагрузка на диск может оказаться в 4000 Мбит/с в течение длительных периодов времени и все это время клиенты сервера будут недовольны.
Я здесь пишу свой опыт, со своим видением и трактовкой. Пожалуйста, учитывайте это.
IOTOP
Посмотреть, какие процессы в настоящее время создают нагрузку на диск удобно смотреть командой iotop:
Здесь видно, что в данный момент mc что-то пишет (а в это время в другом окне я в самом деле копировал кучу файлов на usb-диск в Midnight Commander (он же mc).
Понять, что коипрует mc в данный момент можно узнать командой:
IOSTAT
Пример вывода iostat на незагруженной в данный момент старенькой системе из двух SATA HDD в soft raid 1 (зеркало) mdadm:
Команда выглядела так:
-x — расширенная статистика
-t — выводить время для каждой порции замеров
-m — результаты в Мбайт
5 — интервал замеров 5 секунд.
Если нужны не история, а динамика процесса, попробуйте так:
watch iostat -x -t -m 1 2
В этом выводе r/s и w/s это отправленные к устройству запросы на выполнение (IOPS, которые хотелось бы, чтобы устройство выполнило).
await — время, включающее ожидание выполнения запроса (как если бы вы встали в очередь в кассу и ждали бы, пока вас обслужат).
svctm — время, реально затраченное на выполнение запроса (время «на самой кассе»).
Для обычных SATA дисков нагрузка IOPS где-то до 100-130 вполне выполнимая. В момент проведения замеров запрошенная нагрузка была 40 IOPS, поэтому запрос практически в очереди и не стоял, его обслужили почти сразу (на «кассе» никого не было). Поэтому await практически равен svctm.
Другое дело, когда нагрузка на диск вырастает:
%iowait — простой процессора (время в процентах) от или процессоров, в то время пока обрабатывались запросы. Т.е. в среднем процессор отдыхал почти 50% времени.
%user — загруженность процессора пользовательскими приложениями. По этому параметру видно, например, что в данный период процессор был почти не занят. Это важно, т.к. может помочь отсечь подозрения в тормозах из-за процессора.
Замер сделан во время переноса большого количества писем из одной папки IMAP в другую. Особо обратите внимание на await и svctm. Налицо длинная очередь (отношение await к svctm). Дисковая система (или чипсет, или медленный контроллер SATA, или. ) не справляется с запрошенной нагрузкой (w/s).. Для пользователей в этот момент все выглядело просто — сервер тупит или даже завис.
Заранее проверить производительность дисков можно с помощью fio. Также можно примерно оценить на одной машине производительность дисков и понимать, какой уровень «в среднем по больнице» вы можете ожидать. Это, конечно же, не правильно, но оценить все же поможет. Глубже анализировать результаты, а, главное, методики тестов мне пока трудно.
# apt-get install fio
В общем виде запуск выглядит так:
Файл your.cfg (название произвольное) может быть примерно таким (пример рабочего конфига для теста на чтение):
Буферизацию не используем (buffered=0), чтение не последовательное (rw=randread).
Во время выполнения этого теста (а выполняться тест может доооолго, надоест — Ctrl+C, результаты все равно будут) можно запустить iostat и посмотреть, что происходит:
Обратите внимание на отношение await к svctm: await/svctm = 32,11..11, т.е. можно считать 32. Это и есть iodepth из конфига your.cfg. Теперь проще понять смысл iodepth — мы указываем, насколько хотим в тесте имитировать длинную очередь заданий.
Я не стал ждать два дня, Ctrl+C и вот результат:
Получили 109 iops, что в принципе нормально, диск обычный, SATA.
Как просмотреть нагрузку на диск в Linux
Статистику по операциям ввода-вывода для дисков можно посмотреть при помощи команд iostat и pidstat. Это поможет понять какие процессы создают набольшую нагрузку на дисковую подсистему.
Для работы с этими утилитами придется установить дополнительные пакеты. Инструкция по установка:
1) Debian\Ubuntu:
Команда iostat
Просмотр общей статистики ввода-вывода по дискам можно осуществить командой:
Пример вывода команды:
Важными столбцами являются:
- r/s Число операций чтения с диска в секунду
- w/s Число операций записи на диск в секунду
- rkB/s Число прочитанных килобайт за секунду
- wkB/s Число записанных килобайт за секунду
Команда pidstat
Просмотр статистики в разрезе процессов можно посмотреть в интерактивном режиме при помощи команды:
Пример вывода команды:
Важными столбцами являются:
- UID Идентификатор пользователя, от имени которого работает процесс
- PID Идентификатор процесса
- kB_rd/s Скорость в килобайтах в секунду, с которой процесс читает с диска
- kB_wr/s Скорость в килобайтах в секунду, с которой процесс записывает на диск
Выполняю установку, настройку, сопровождение серверов. Для уточнения деталей используйте форму обратной связи
Иногда бывают ситуации, когда в top’e вроде бы всё нормально, но сервер всё равно тормозит. Тогда нужно обратить внимание на нагрузки дисковой подсистемы. В статье мы рассмотрим варианты для Unix систем: FreBSD, OpenBSD, Linux, Solaris.
FreeBSD
Во FreeBSD есть штатная утилита gstat, при запуске которой без параметров мы увидим текущую нагрузку на диски.
Как видно из примера, очень большая нагрузка на диск ad4.
Так же можно смотреть и через iostat (пример из другой ОС):
А ещё можно использовать команду systat -iostat:
А что-бы определить процесс, который нагружает диски, выполним такую команду:
OpenBSD
Для OpenBSD есть штатная утилита iostat, которая показывает нагрузку на диски+CPU usage. При обычном запуске она показывает не больше 4 дисков, но если нужно больше, то указываем все нужные диски.
Linux
Для Linux есть аналог утилиты gstat — iostat. В Debian/Ubuntu она находится в пакете sysstat.
Здесь мы поставили автообновление каждую секунду. Хочу обратить внимание на то, что первые пару выводов во внимание не брать, так как в первом выводе отображается информация из кеша, а не реальные показатели. Как видим, диски здесь не нагружены
Для определения процесса, который нагружает диски, есть утилита iotop, правда её нужно ставить отдельно.
Solaris
Для solaris существует 3 метода: zpool iostat, утилита iostat, fsstat. Единственный недостаток, это то, что мы не сможем отображать статистику отдельно по каждой из zfs, а только можем отдельно по каждому диску:
Здесь как и в случае с Linux не учитываем первый вывод. Как видим, диски простаивают (значение столбца %b — busy).
Общую картину можно так же посмотреть через fsstat:
Очень удобно просматривать информацию по конкретной zfs:
Смотрим нагрузку на диски : 5 комментариев
Программа ‘gstat’ на данный момент не установлена. Вы можете установить ее, напечатав:
apt-get install ganglia-monitor
Это не тот gstat, которым смотрят диски — просто названия одинаковые.
FreeBSD
top -m io -o total
ога ))
по моему то чё он предлагает имеет отношение к sql
если zfs на фре то «zpool iostat -vl 1» надо юзать без l
zpool iostat -v 1
20 инструментов командной строки для мониторинга производительности Linux

Действительно трудной задачей для каждого администратора является ежедневное отслеживание и отладка проблем производительности системы Linux. Будучи администратором Linux более 5 лет в ИТ-индустрии, я узнал, насколько сложно контролировать и поддерживать работу систем. По этой причине мы составили список 20 наиболее часто используемых инструментов мониторинга производительности Linux, которые могут быть полезны для каждого системного администратора Linux/Unix. Эти команды доступны во всех дистрибутивах Linux и могут быть полезны для мониторинга и поиска фактических причин проблемы с производительностью.
1. Top — мониторинг процессов Linux
Команда top — это команда мониторинга производительности, которая часто используется многими системными администраторами для мониторинга производительности Linux. Команда top используется для отображения всех запущенных и активных процессов в реальном времени в упорядоченном списке. Она отображает использование ЦП, использование памяти, память swap, размер кэша, размер буфера, идентификатор процесса, пользователя и многое другое. Команда top очень удобна для мониторинга и принятия правильных решений в случае возникновения проблем. Давайте посмотрим команду top в действии.
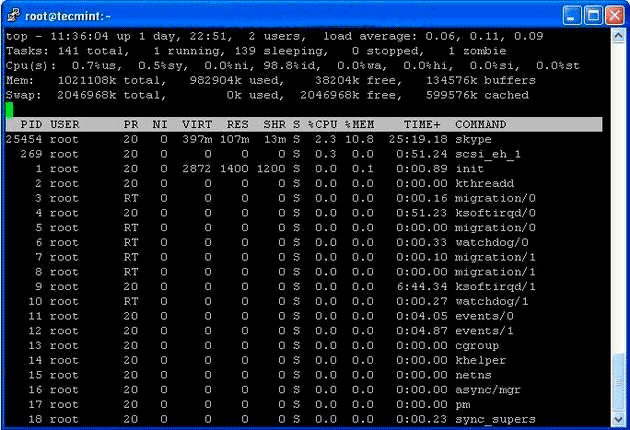
Дополнительные примеры команды Top: Как сохранить вывод команды top в файл?
2. VmStat — статистика виртуальной памяти
Команда VmStat используется для отображения статистики виртуальной памяти, потоков ядер, дисков, системных процессов, блоков ввода-вывода, прерываний, активности процессора и многого другого. По умолчанию команда vmstat недоступна в системах Linux, вам необходимо установить пакет sysstat, который включает в себя программу vmstat.


3. Lsof — список открытых файлов
Команда Lsof используется во многих системах Linux/Unix, при отображении списка всех открытых файлов и процессов. В число открытых файлов входят файлы дисков, сетевые сокеты, каналы, устройства и процессы. Одной из основных причин использования этой команды является то, что диск нельзя размонтировать иначе он отображает ошибку, когда какие-то файлы используются или открыты. С помощью этой команды вы можете легко определить, какие файлы используются.
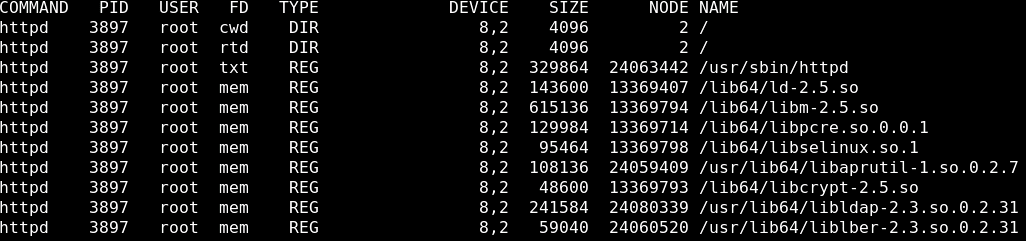

4. Tcpdump — анализатор сетевых пакетов
Tcpdump — один из наиболее широко используемых программных анализаторов сетевых пакетов, который используется для сбора или фильтрации пакетов TCP/IP, которые были получены или переданы по определенному интерфейсу в сети. Он также предоставляет возможность сохранять захваченные пакеты в файле для последующего анализа. tcpdump доступен почти во всех основных дистрибутивах Linux.

Больше примеров использования tcpdump: tcpdump — полезное руководство с примерами
5. Netstat — статистика сети
Netstat — это инструмент командной строки для мониторинга статистики входящих и исходящих сетевых пакетов, а также статистики интерфейса. Это очень полезный инструмент для каждого системного администратора при работе с задачами мониторинга производительности сети и устранения неполадок, связанных с сетью.

6. Htop — мониторинг процессов Linux
Htop — это очень продвинутый интерактивный инструмент мониторинга процессов Linux в реальном времени. Он очень похож на команду top, но у него есть некоторые характерные особенности, такие как удобный интерфейс для управления процессами, горячие клавиши, вертикальный и горизонтальный просмотр процессов и многое другое. Htop является сторонним инструментом и не входит в системы Linux, вам нужно установить его с помощью инструмента управления пакетами YUM.
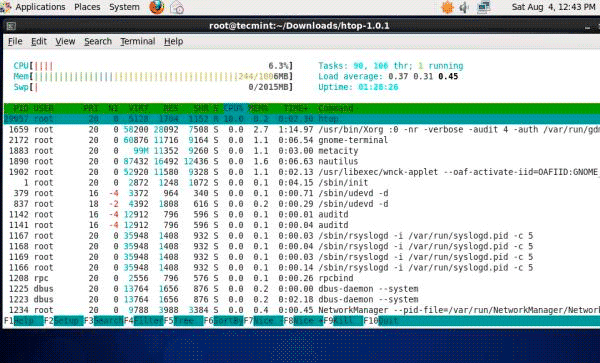
7. Iotop — мониторинг дискового ввода-вывода Linux
Iotop также очень похож на команду top и команду htop, но выполняет функцию мониторинга и отображения операций ввода/вывода процессов в реальном времени. Этот инструмент очень полезен для поиска конкретного процесса:
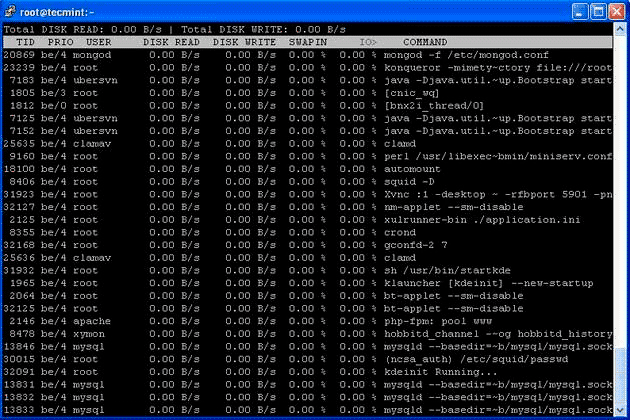
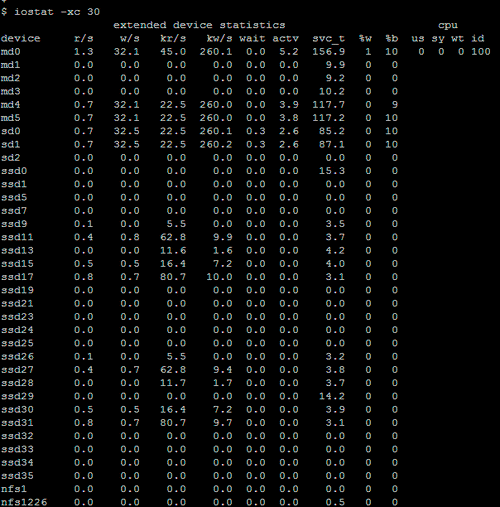
8. Iostat — Статистика ввода/вывода
IoStat — это простой инструмент, который будет собирать и отображать статистику ввода/вывода системных входов. Этот инструмент часто используется для отслеживания проблем с производительностью устройств хранения данных, включая локальные диски, удаленные диски, такие как NFS и т.д.
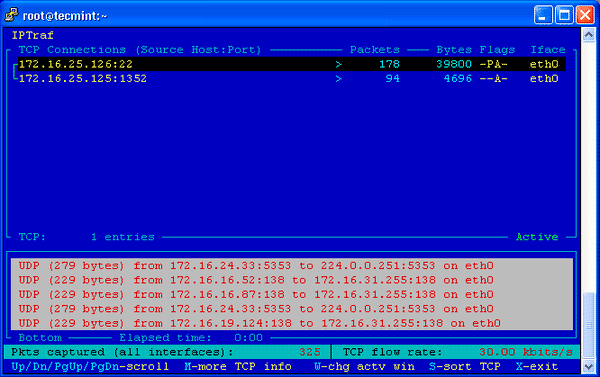
9. IPTraf — мониторинг сети IP в реальном времени
IPTraf — это консольная утилита мониторинга сети реального времени (IP LAN) с открытым исходным кодом для Linux. Она собирает разнообразную информацию, такую как мониторинг трафика IP, который проходит по сети, включая информацию о флагах TCP, данных ICMP, сбои трафика TCP/UDP, пакеты TCP-соединения и подсчеты byne. Она также собирает информацию общей и подробной статистики интерфейса TCP, UDP, IP, ICMP, no-IP, ошибок контрольной суммы IP, активности интерфейса и т.д.
Для получения дополнительной информации о использования инструмента IPTraf прочтите: 5 малоизвестных инструментов для администраторов Linux
10. Psacct или Acct — мониторинг активности пользователя
Инструменты psacct или acct очень полезны для мониторинга активности каждого пользователя в системе. Оба демона работают в фоновом режиме и внимательно следят за общей деятельностью каждого пользователя в системе, а также за тем, какие ресурсы потребляет каждый из пользователей.
Эти инструменты очень полезны для системных администраторов, при отслеживании активности каждого пользователя. Что они делают, какие команды они выполняли, сколько ресурсов использовали, сколько времени они активны в системе и т.д.
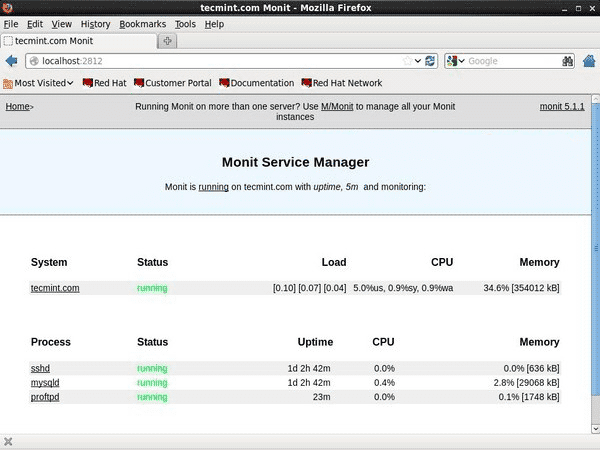
11. Monit — мониторинг процессов и сервисов Linux
Monit — бесплатная программа с открытым исходным кодом и веб-приложением, которая автоматически отслеживает и управляет системными процессами, программами, файлами, каталогами, разрешениями, контрольными суммами и файловыми системами.
Она контролирует такие сервисы, как Apache, MySQL, Mail, FTP, ProFTP, Nginx, SSH и т.д. Состояние системы можно просмотреть прямо из командной строки, также можно воспользоваться веб-интерфейсом.
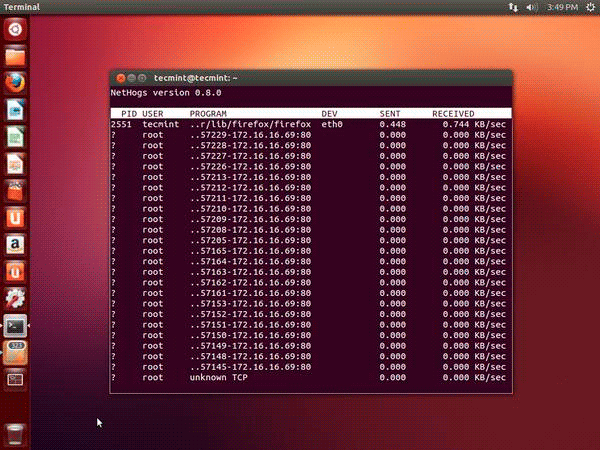
12. NetHogs — мониторинг пропускной способности сети
NetHogs — это небольшая программа с открытым исходным кодом (похожая на команду top), которая хранит данные каждой сетевой активности в вашей системе. Она также отслеживает пропускную способность сетевого трафика в реальном времени, используемую каждой программой или приложением.
13. iftop — мониторинг пропускной способности сети
iftop — еще одна утилита для мониторинга системы с открытым исходным кодом на терминальной основе, которая отображает обновляемый список использования пропускной способности сети (исходные и целевые узлы), которые проходят через сетевой интерфейс вашей системы. iftop рассматривается для использования в сети, в то время как «top» рассматривается для использования с ЦП. iftop — это инструмент, который контролирует выбранный интерфейс и отображает текущее использование полосы пропускания между двумя хостами.

14. Monitorix — мониторинг системы и сети
Monitorix — бесплатная утилита, предназначенная для запуска и мониторинга системных и сетевых ресурсов на серверах Linux/Unix. Она имеет встроенный HTTP-сервер, который регулярно собирает системную и сетевую информацию и отображает её на графиках. Она контролирует среднюю нагрузку на систему и её использование, распределение памяти, состояние драйвера диска, системные службы, сетевые порты, статистику почты (Sendmail, Postfix, Dovecot и т.д.), статистику MySQL и многие другие. Она предназначен для мониторинга общей производительности системы и помогает обнаруживать сбои, узкие места, необычное поведение системы действия и т.д.
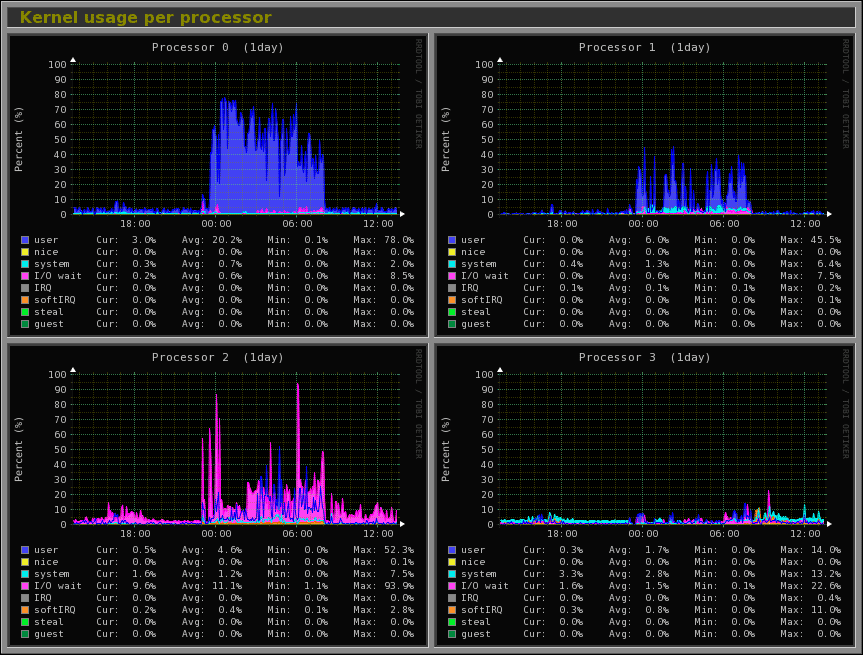
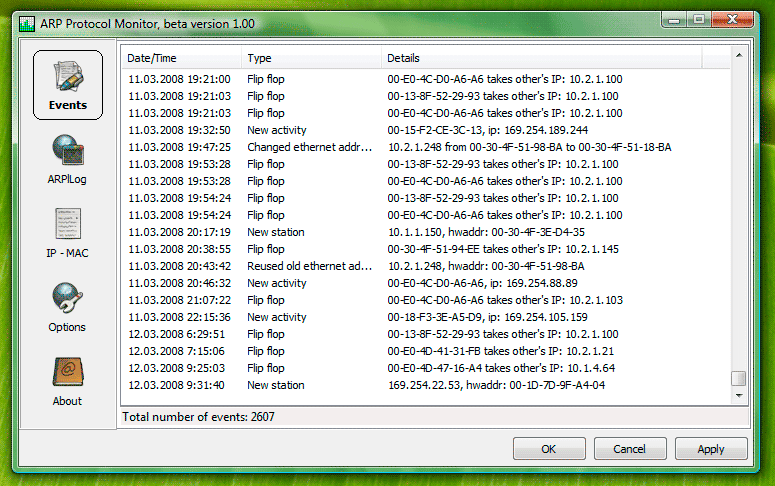
15. Arpwatch — мониторинг активности Ethernet
Arpwatch — это своего рода программа, предназначенная для мониторинга разрешения адресов (MAC и IP-адресов) сетевого трафика Ethernet в сети Linux. Она постоянно отслеживает трафик Ethernet и создает журнал изменений пары IP и MAC-адресов вместе с метками времени в сети. Она также имеет функцию отправки уведомлений по электронной почте администратору при добавлении или изменении пары. Это очень полезно при обнаружении спуфинга ARP в сети.
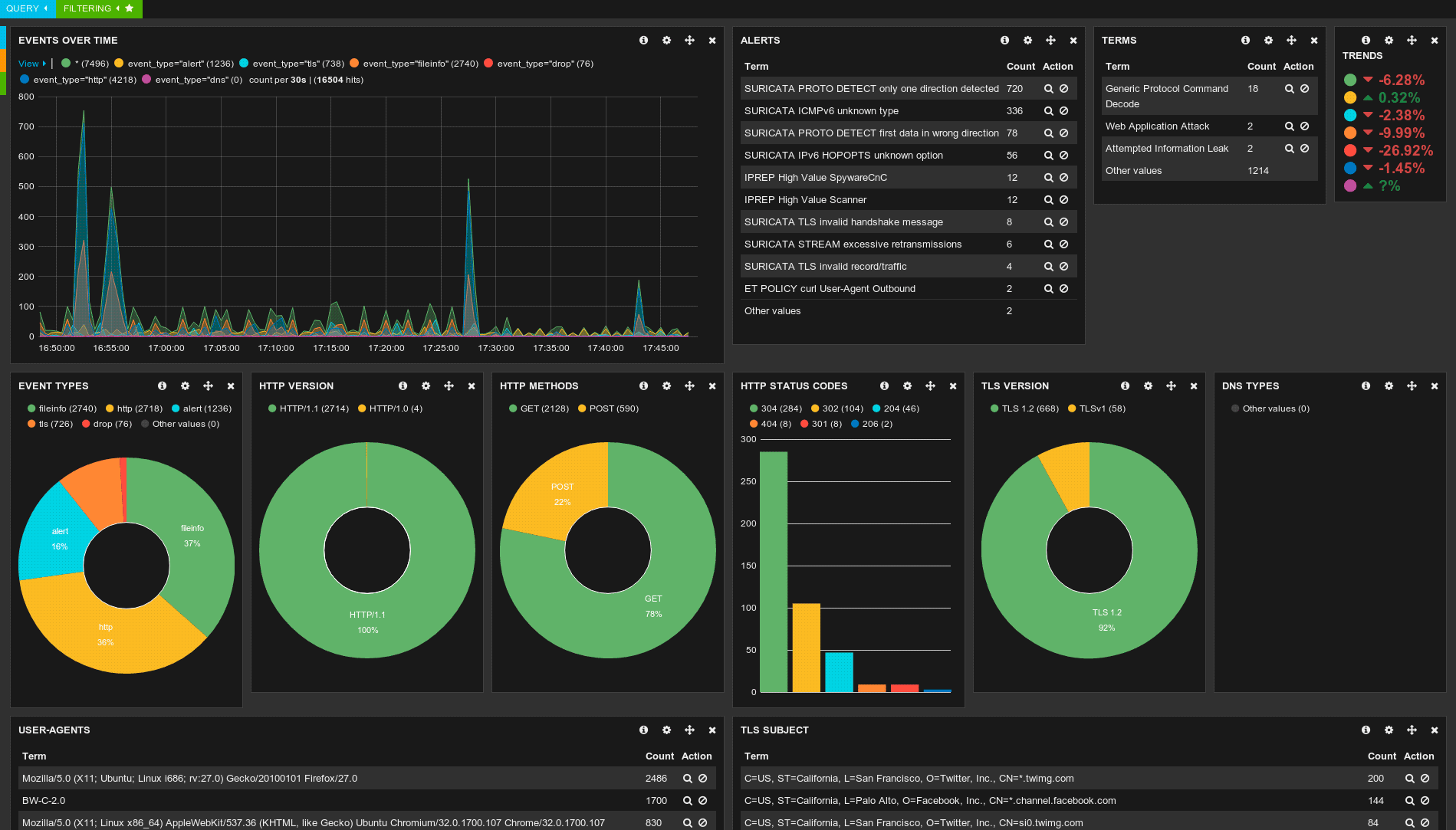
16. Suricata — мониторинг сетевой безопасности
Suricata — это высокопроизводительная система обнаружения и предотвращения вторжений с открытыми исходным кодом для обнаружения и предотвращения вторжений для Linux, FreeBSD и Windows. Она была разработана и принадлежит некоммерческому фонду OISF (Open Information Security Foundation).
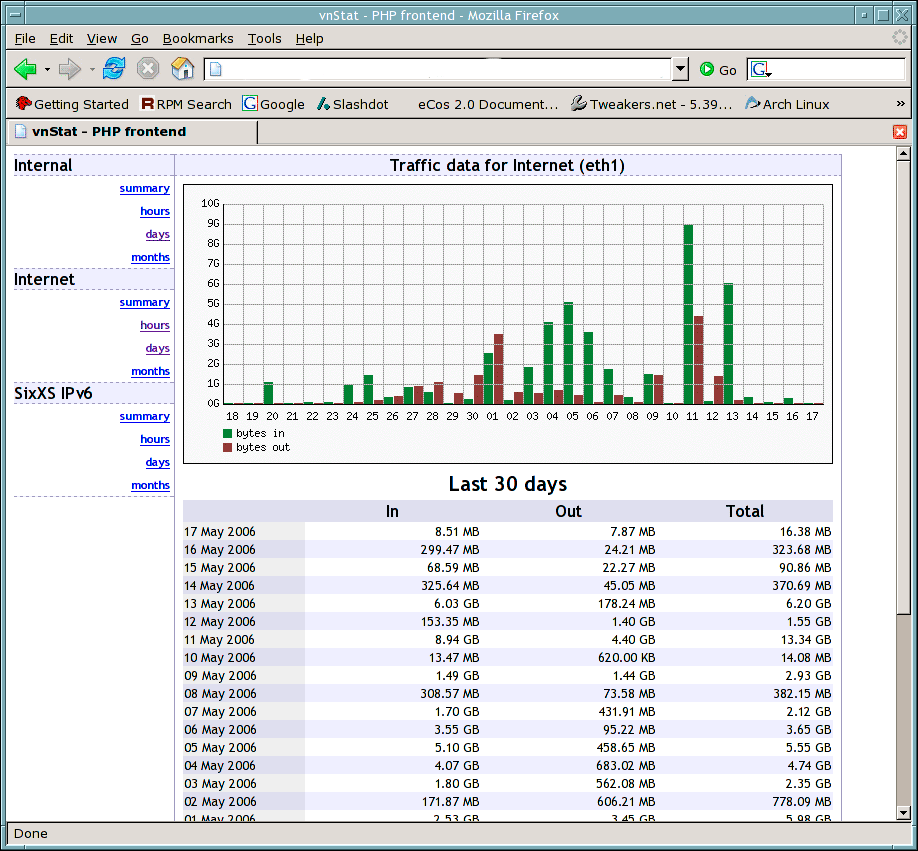
17. VnStat PHP — мониторинг пропускной способности сети
VnStat PHP — веб-интерфейс для большинства популярных сетевых инструментов под названием «vnstat». VnStat PHP показывает использование сетевого трафика в удобном графическом формате. Он отображает общее использование сетевого трафика IN и OUT в ежечасном, ежедневном, ежемесячном и полном сводном отчете.
18. Nagios — мониторинг сети/сервера
Nagios — это мощная система мониторинга с открытым исходным кодом, которая позволяет сетевым/системным администраторам идентифицировать и решать проблемы, связанные с сервером, прежде чем они повлияют на основные бизнес-процессы. С Nagios администраторы могут контролировать удаленные хосты Linux, Windows, коммутаторы, маршрутизаторы и принтеры. Она показывает критические предупреждения и указывает, что что-то пошло не так в вашей сети/сервере, что косвенно помогает вам начать процессы восстановления до их возникновения.
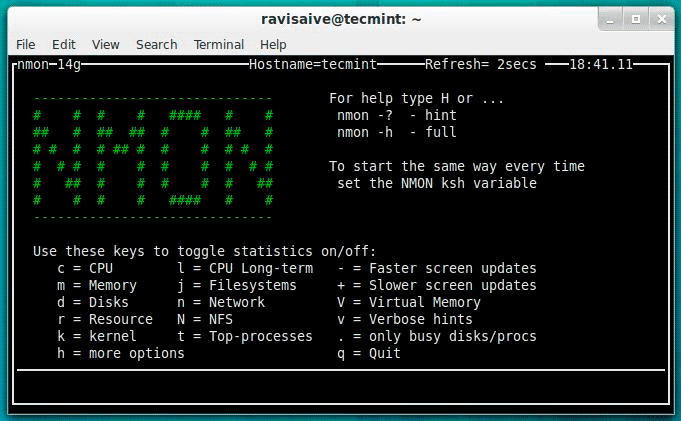
19. Nmon — мониторинг производительности Linux
Nmon (предназначен для монитора производительности Nigel), который используется для мониторинга всех ресурсов Linux, таких как процессор, память, использование диска, сеть, NFS, ядро и многое другое. Этот инструмент поставляется в двух режимах: онлайн-режиме и режиме захвата.
Режим Online, используемый для мониторинга в реальном времени. А режима захвата, используется для хранения вывода в формате CSV для последующей обработки.
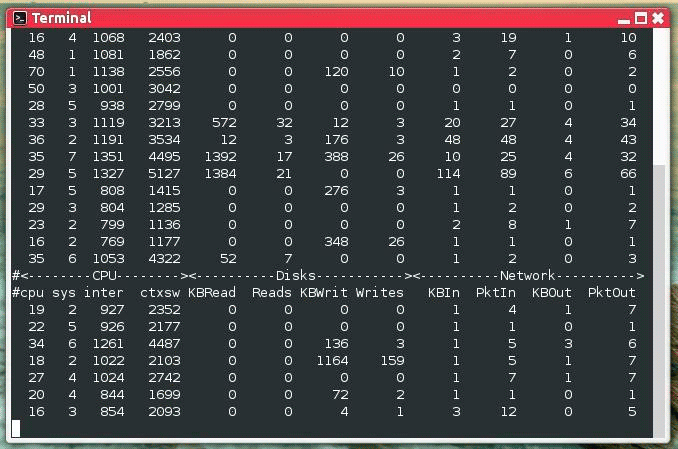
20. Collectl — инструмент мониторинга производительности «все-в-одном»
Collectl — еще одна мощная и многофункциональная утилита командной строки, которая может использоваться для сбора информации о системных ресурсах Linux, таких как использование ЦП, памяти, сети, inodes, процессах, nfs, tcp, сокетов и многого другого.
Мы хотели бы знать, какие программы мониторинга вы используете для мониторинга производительности ваших серверов Linux? Если мы пропустили какой-либо важный инструмент, который вы хотели бы нам порекомендовать добавить в этот список, пожалуйста, сообщите нам через раздел комментарии который находится ниже.
Спасибо за уделенное время на прочтение статьи!
Если возникли вопросы, задавайте их в комментариях.
Подписывайтесь на обновления нашего блога и оставайтесь в курсе новостей мира инфокоммуникаций!