Печенюшка
Технология Receive Side Scaling и терминальные сессии
 Помнится, года 2 назад я устанавливал на сервер Microsoft Exchange 2007 и были какие-то проблемы с сетевым взаимодействием, какие-то сервисы не работали вообще, какие-то работали, но очень криво. Ещё тогда проблему удалось решить и успешно забыть о решении. Сейчас натолкнулся на проблему работы терминального сервера на базе Windows Server 2003, проблема в том, что клиент от Windows 7 очень медленно работает, реакция на нажатия кнопок меню и прочего, такая медленная, что работать не возможно, тогда как клиент от Windows XP работает хорошо и гладко. Так в чем же все таки проблема и как её решить?
Помнится, года 2 назад я устанавливал на сервер Microsoft Exchange 2007 и были какие-то проблемы с сетевым взаимодействием, какие-то сервисы не работали вообще, какие-то работали, но очень криво. Ещё тогда проблему удалось решить и успешно забыть о решении. Сейчас натолкнулся на проблему работы терминального сервера на базе Windows Server 2003, проблема в том, что клиент от Windows 7 очень медленно работает, реакция на нажатия кнопок меню и прочего, такая медленная, что работать не возможно, тогда как клиент от Windows XP работает хорошо и гладко. Так в чем же все таки проблема и как её решить?
Дело в том, что на всех серверах, где всречалась данная проблема была установлена сетевая карта от Intel, с поддержкой Receive Side Scaling, возможно и другие сетевые карты поддерживают данную опцию.
Receive Side Scaling (RSS) — Это технология, которая равномерно распределяет нагрузку по обработке сетевых пакетов между ядрами процессора, позволяя оптимизировать производительность.
На сайте Intel написано: Microsoft признает, что такая проблема имеет место быть с операционной системой Windows Server 2003, о чем говорится в knowledge base 927695:
You cannot host TCP connections when Receive Side Scaling is enabled in Windows Server 2003 with Service Pack 2
Отключить данную опцию можно локально для сетевого интерфейса:
 Или глобально в операционной системе Windows Server 2003:
Или глобально в операционной системе Windows Server 2003:
1. Click Start, click Run, type regedit, and then click OK.
2. Locate and then click the following registry subkey:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
3. On the Edit menu, point to New, click DWORD Value, and then type EnableRSS.
4. Double-click EnableRSS, type 0, and then click OK.
5. Restart the computer on which you changed the EnableRSS value.
Для операционных систем Windows Vista и выше отключение производится с командной строки:
netsh interface tcp set global rss=disabled
После чего перезагружаемся, и проверяем статус:

Отключение Receive Side Scaling должно решить проблему.
Тюнинг сетевого стека Linux для ленивых
Сетевой стек Linux по умолчанию замечательно работает на десктопах. На серверах с нагрузкой чуть выше средней уже приходится разбираться как всё нужно правильно настраивать. На моей текущей работе этим приходится заниматься едва ли не в промышленных масштабах, так что без автоматизации никуда – объяснять каждому коллеге что и как устроено долго, а заставлять людей читать ≈300 страниц английского текста, перемешанного с кодом на C… Можно и нужно, но результаты будут не через час и не через день. Поэтому я попробовал накидать набор утилит для тюнинга сетевого стека и руководство по их использованию, не уходящее в специфические детали определённых задач, которое при этом остаётся достаточно компактным для того, чтобы его можно было прочитать меньше чем за час и вынести из него хоть какую-то пользу.
Чего нужно добиться?
Главная задача при тюнинге сетевого стека (не важно, какую роль выполняет сервер — роутер, анализатор трафика, веб-сервер, принимающий большие объёмы трафика) – равномерно распределить нагрузку по обработке пакетов между ядрами процессора. Желательно с учётом принадлежности CPU и сетевой карты к одной NUMA-ноде, а также не создавая при этом лишних перекидываний пакета между ядрами.
Перед главной задачей, выполняется первостепенная задача — подбор аппаратной части, само собой с учётом того, какие задачи лежат на сервере, откуда и сколько приходит и уходит трафика и т.д.
Рекомендации по подбору железа
Таким образом, если дано 2+ источника объёма трафика больше 2 Гбит/сек, то стоит задуматься о сервере с числом процессоров и NUMA-нод, а также числу сетевых карт (не портов), равных числу этих источников.
«Господи, я не хочу в этом разбираться!»
И не нужно. Я уже разобрался и, чтобы не тратить время на то, чтобы объяснять это коллегам, написал набор утилит — netutils-linux. Написаны на Python, проверены на версиях 2.6, 2.7, 3.4, 3.6.
network-top
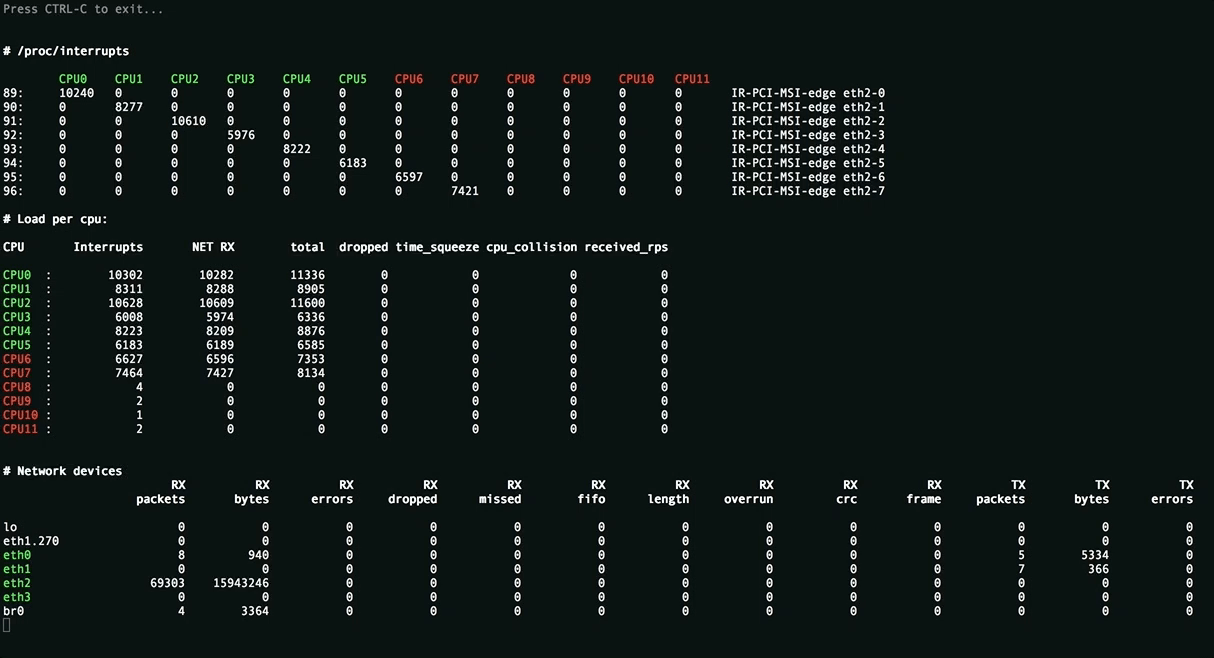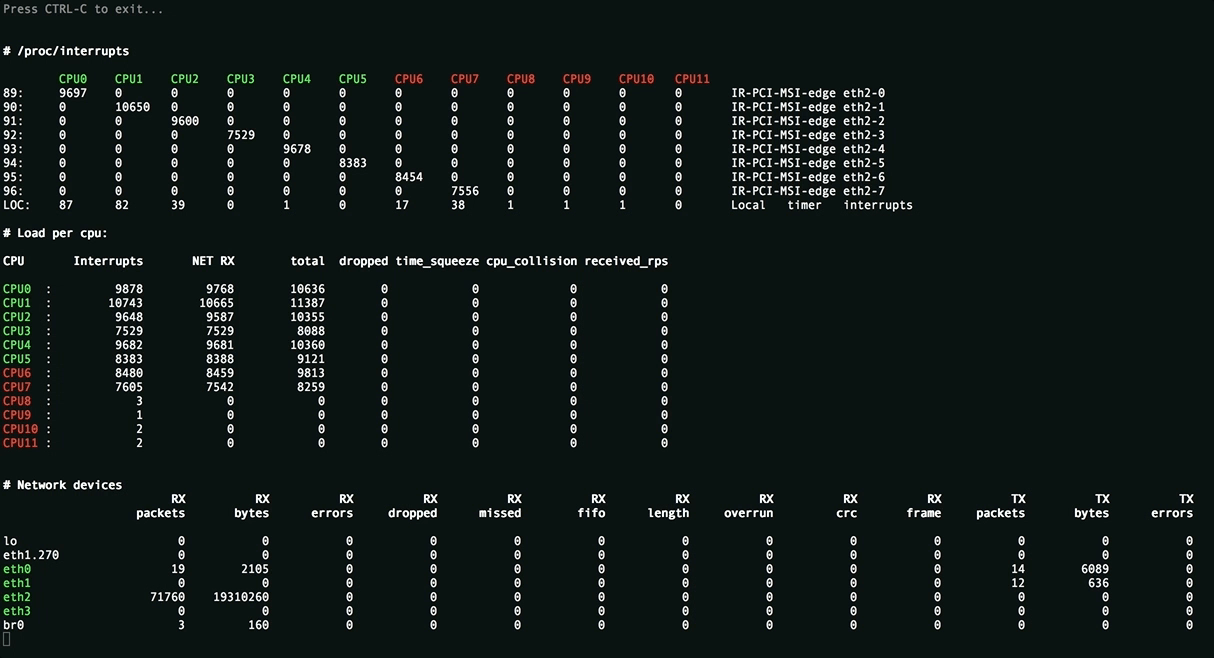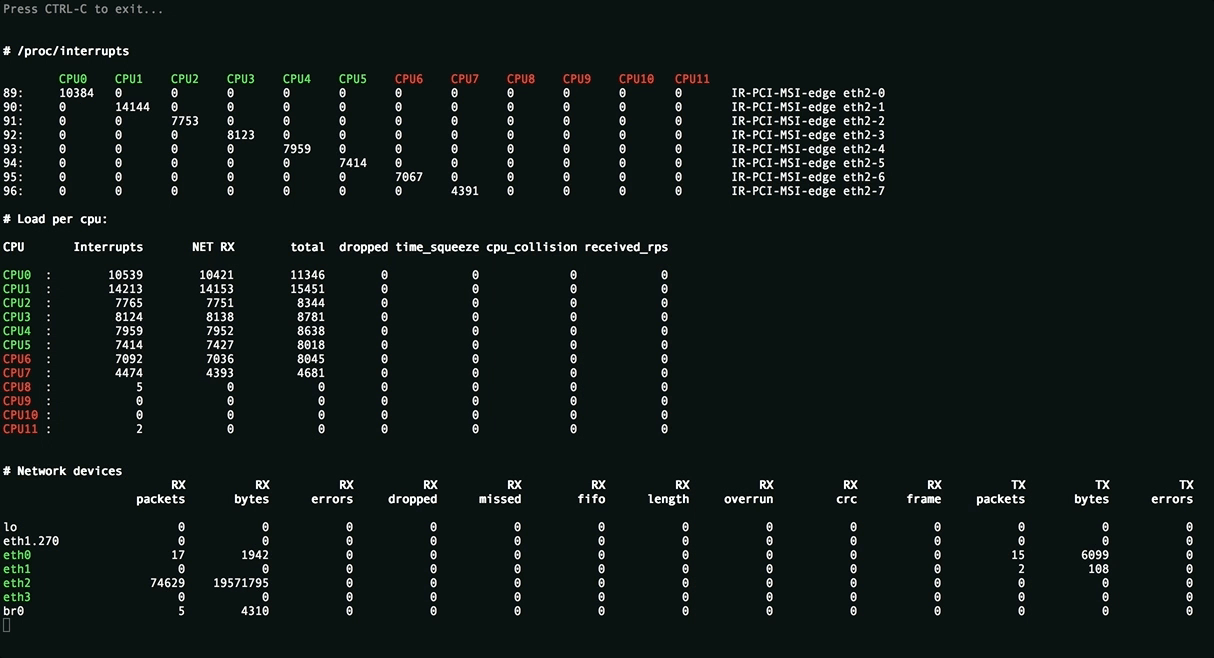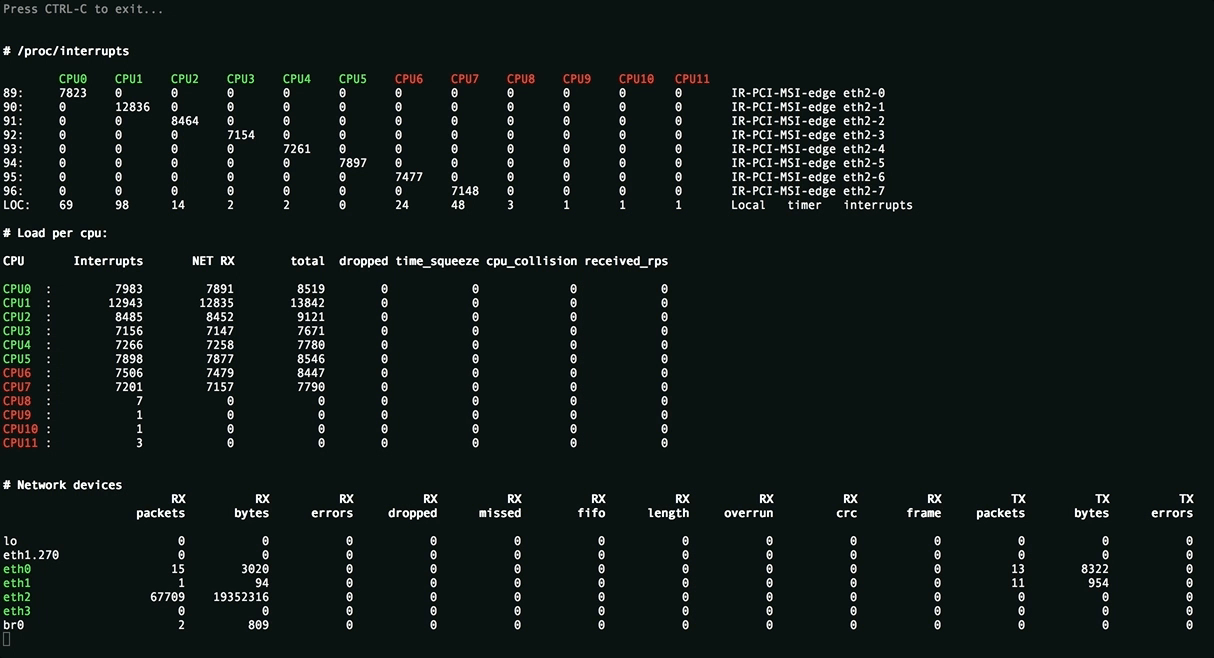
Эта утилита нужна для оценки применённых настроек и отображает равномерность распределения нагрузки (прерывания, softirqs, число пакетов в секунду на ядро процессора) на ресурсы сервера, всевозможные ошибки обработки пакетов. Значения, превышающие пороговые подсвечиваются.
rss-ladder
Эта утилита распределяет прерывания сетевой карты на ядра выбранного физического процессора (по умолчанию на нулевой).
autorps
Эта утилита позволяет настроить распределение обработки пакетов между ядрами выбранного физического процессора (по умолчанию на нулевой). Если вы используете RSS, скорее всего вам эта утилита не потребуется. Типичный сценарий использования — многоядерный процессор и сетевые карты с одной очередью.
server-info
Данная утилита позволяет сделать две вещи:
- server-info show : посмотреть, что за железо вообще установлено на сервере. В целом похоже на велосипед, повторяющий lshw , но с акцентом на интересующие нас параметры.
- server-info rate : найти узкие места в аппаратном обеспечении сервера. В целом похоже на индекс производительности Windows, но опять же с акцентом на интересующие нас параметры. Оценка производится по шкале от 1 до 10.
Прочие утилиты
Господи, я хочу в этом разбираться!
Прочитайте статьи про:
Эти статьи вдохновили меня на написание этих утилит .
Также хорошую статью написали в блоге одноклассников 2 года назад.
Обычные кейсы
Но руководство по запуску утилит само по себе мало что говорит о том, как именно их нужно применять в зависимости от ситуации. Приведём несколько примеров.
Пример 1. Максимально простой.
- один процессор с 4 ядрами
- одна 1 Гбит/сек сетевая карта (eth0) с 4 combined очередями
- входящий объём трафика 600 Мбит/сек, исходящего нет.
- все очереди висят на CPU0, суммарно на нём ≈55000 прерываний и 350000 пакетов в секунду, из них около 200 пакетов/сек теряются сетевой картой. Остальные 3 ядра простаивают
- распределяем очереди между ядрами командой rss-ladder eth0
- увеличиваем ей буфер командой rx-buffers-increase eth0
Пример 2. Чуть сложнее.
- два процессора с 8 ядрами
- две NUMA-ноды
- Две двухпортовые 10 Гбит/сек сетевые карты (eth0, eth1, eth2, eth3), у каждого порта 16 очередей, все привязаны к node0, входящий объём трафика: 3 Гбит/сек на каждую
- 1 х 1 Гбит/сек сетевая карта, 4 очереди, привязана к node0, исходящий объём трафика: 100 Мбит/сек.
1 Переткнуть одну из 10 Гбит/сек сетевых карт в другой PCI-слот, привязанный к NUMA node1.
2 Уменьшить число combined очередей для 10гбитных портов до числа ядер одного физического процессора:
3 Распределить прерывания портов eth0, eth1 на ядра процессора, попадающие в NUMA node0, а портов eth2, eth3 на ядра процессора, попадающие в NUMA node1:
4 Увеличить eth0, eth1, eth2, eth3 RX-буферы:
Необычные кейсы
Не всегда всё идёт идеально:
- Встречались сетевые карты, теряющие пакеты (missed) в случае использования RSS на несколько ядер в одной NUMA-ноде. Решение странное, но рабочее — 6 RX-очередей привязаны к CPU0, в rps_cpus каждой очереди записана маска процессоров 111110, потери пропали.
- Встречались сетевые карты mellanox и intel (X710) продолжающие работать при прекратившемся росте счётчиков прерываний. Трафик в tcpdump имелся, нагрузка, создаваемая сетевыми картами висела на CPU0. Нормальная работа восстановилась после включения и выключения RPS. Почему — неизвестно.
- Некоторые SFP-модули для Intel 82599ES при обновлении драйвера (сборка ixgbe из исходников с sourceforge) «пропадают» из списка сетевых карт. При этом в lspci этот порт отображается, второй аналогичный порт работает, а в dmesg на оба порта одинаковые warning’и. Помогает флаг unsupported_sfp=1,1 при загрузке модуля ixgbe. По хорошему, однако, стоит купить supported sfp.
- Некоторые драйверы сетевых карт подстраивают число очередей только под равные степени двойки значения (что обидно на 6-ядерных процессорах).
Update: после публикации автор осознал, что люди используют не только RHEL-based дистрибутивы для сетевых задач, а тесты в debian на наборах данных, собранных в RHEL-based системах, не отлавливают кучу багов. Большое спасибо всем сообщившим о том, что что-то не работает в Ubuntu/Debian/Altlinux! Все баги исправлены в релизе 2.0.10
Update2. в комментариях упомянули то, что RPS всё же часто бывает полезен людям и я его недооцениваю. В принципе это так, поэтому в релизе 2.2.0 появилась значительно улучшенная версия утилиты autorps.
Ой, у вас баннер убежал!
Редакторский дайджест
Присылаем лучшие статьи раз в месяц
Скоро на этот адрес придет письмо. Подтвердите подписку, если всё в силе.

Похожие публикации
Автоматизация IP-сети. Часть2 – Мониторинг скорости открытия Веб страниц
Сравнение производительности железного сервера и облака Amazon
Мониторинг серверов облачным сервисом: решения от ХостТрекера
Курсы
AdBlock похитил этот баннер, но баннеры не зубы — отрастут
Комментарии 45

Как расшифровывается RPS в данном конткесте, если не секрет?
RPS: Receive Packet Steering, программный аналог аппаратного Receive-Side Scaling (RSS). Обе технологии позволяют распределять входящие пакеты по очередям в зависимости от хеша нескольких байтов заголовка (фильтра).
Contemporary NICs support multiple receive and transmit descriptor queues (multi-queue). On reception, a NIC can send different packets to different queues to distribute processing among CPUs. The NIC distributes packets by
applying a filter to each packet that assigns it to one of a small number of logical flows. Packets for each flow are steered to a separate receive queue, which in turn can be processed by separate CPUs. This mechanism is
generally known as “Receive-side Scaling” (RSS). The goal of RSS and the other scaling techniques is to increase performance uniformly.
…
Receive Packet Steering (RPS) is logically a software implementation of RSS. Being in software, it is necessarily called later in the datapath. Whereas RSS selects the queue and hence CPU that will run the hardware
interrupt handler, RPS selects the CPU to perform protocol processing above the interrupt handler. This is accomplished by placing the packet on the desired CPU’s backlog queue and waking up the CPU for processing.
RPS has some advantages over RSS:
1) it can be used with any NIC,
2) software filters can easily be added to hash over new protocols,
3) it does not increase hardware device interrupt rate (although it does introduce inter-processor interrupts (IPIs)).
RPS is called during bottom half of the receive interrupt handler, when a driver sends a packet up the network stack with netif_rx() or netif_receive_skb(). These call the get_rps_cpu() function, which selects the queue that should process a packet.