Оптимизация производительности PostgreSQL
Ниже перечислены основные параметры, на которые следует обратить внимание при оптимизации производительности PostgreSQL.
Объём совместно используемой памяти, выделяемой PostgreSQL для кэширования данных, определяется числом страниц ( shared_buffers ) по 8 килобайт каждая. Следует учитывать, что операционная система сама кеширует данные, поэтому нет необходимости отводить под кэш всю наличную оперативную память. Размер shared_buffers зависит от многих факторов, для начала можно принять следующие значения:
- 8–16 Мб – Обычный настольный компьютер с 512 Мб и небольшой базой данных
- 80–160 Мб – Небольшой > сервер, предназначенный для обслуживания базы данных с объёмом оперативной памяти 1 Гб и базой данных около 10 Гб.
- 400 Мб – Сервер с несколькими процессорами, с объёмом памяти в 8 Гб и базой данных занимающей свыше 100 Гб обслуживающий несколько сотен активных соединений одновременно .
Под каждый запрос выделяется ограниченный объём памяти для работы. Этот объём используется для сортировки, объединения и других подобных операций. При превышении этого объёма сервер начинает использовать временные файлы на диске, что может существенно снизить производительность. Оценить необходимое значение для work_mem можно разделив объём доступной памяти (физическая память минус объём занятый под другие программы и под совместно используемые страницы shared_buffers ) на максимальное число одновременно используемых активных соединений.
Эта память используется для выполнения операций по сбору статистики (ANALYZE), сборке мусора (VACUUM), создания индексов (CREATE INDEX) и добавления внешних ключей. Размер выделяемой под эти операции памяти должен быть сравним с физическим размером самого большого индекса на диске.
PostgreSQL в своих планах опирается на кэширование файлов, осуществляемое операционной системой. Этот параметр соответствует максимальному размеру объекта, который может поместиться в системный кэш. Это значение используется только для оценки. effective_cache_size можно установить в 1/2 — 2/3 от объёма имеющейся в наличии оперативной памяти, если вся она отдана в распоряжение PostgreSQL.
Следующие параметры могут существенно увеличить производительность работы PostgreSQL. Однако их рекомендуется использовать только если имеются надежные ИБП и программное обеспечение, завершающее работу системы при низком заряде батарей.
Данный параметр отвечает за сброс данных из кэша на диск при завершении транзакций. Если установить его значение fsync =off то данные не будут записываться на дисковые накопители сразу после завершения операций. Это может существенно повысить скорость операций insert и update, но есть риск повредить базу, если произойдет сбой (неожиданное отключение питания, сбой ОС, сбой дисковой подсистемы).
Включает/выключает синхронную запись в лог файлы после каждой транзакции. Это защищает от возможной потери данных. Но это накладывает ограничение на пропускную способность сервера.
Если вашей системе не критична потенциально низкая возможность потери небольшого количества изменений при крахе системы, но необходимо обеспечить в несколько раз большую производительность по количеству транзакций в секунду. В этом случае можно установить этот параметр в off (отключение синхронной записи).
Записки IT специалиста
Технический блог специалистов ООО»Интерфейс»
Оптимизация производительности PostgreSQL для работы с 1С:Предприятие
 PostgreSQL приобретает все большую популярность как СУБД для использования в связке с 1С:Предприятие. При этом одним из самых частых нареканий является низкая производительность этого решения. Во многом это связано с тем, что настройки PostgreSQL по умолчанию не являются оптимальными, а обеспечивают запуск и работу СУБД на минимальной конфигурации. Поэтому имеет смысл потратить некоторое количество времени на оптимизацию производительности сервера, тем более что это не очень сложно.
PostgreSQL приобретает все большую популярность как СУБД для использования в связке с 1С:Предприятие. При этом одним из самых частых нареканий является низкая производительность этого решения. Во многом это связано с тем, что настройки PostgreSQL по умолчанию не являются оптимальными, а обеспечивают запуск и работу СУБД на минимальной конфигурации. Поэтому имеет смысл потратить некоторое количество времени на оптимизацию производительности сервера, тем более что это не очень сложно.
Существуют разные рекомендации по оптимизации PostgreSQL для совместной работы с 1С, мы будем опираться на официальные рекомендации, изложенные на ИТС, также можно использовать онлайн-калькулятор для быстрого расчета некоторых параметров. Если данные калькулятора и рекомендации 1С будут расходиться — то предпочтение будет отдано рекомендациям 1С.
Для тестирования мы использовали систему:
- CPU — Core i5-4670 — 3.4/3.8 ГГц
- RAM — 32 ГБ DDR3
- Системный диск — SSD WD Green 120 ГБ
- Диск для данных — 2 х SSD Samsung 860 EVO 250 ГБ — RAID1
- СУБД — PostgresPro 11.6
- Платформа — 8.3.16.1148
- ОС — Debian 10 x64
Прежде всего выполним тестирование с параметрами по умолчанию:
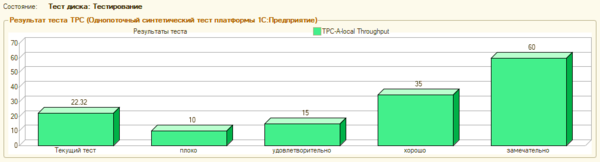 Полученный результат — 22,32 по Гилеву высоким не назовешь, для субъективного контроля мы использовали конфигурацию Розница 2.2 с базой реального торгового предприятия объемом в 8 ГБ, в целом работу можно было признать удовлетворительной, но местами наблюдалась некоторая «задумчивость», особенно при открытии динамических списков.
Полученный результат — 22,32 по Гилеву высоким не назовешь, для субъективного контроля мы использовали конфигурацию Розница 2.2 с базой реального торгового предприятия объемом в 8 ГБ, в целом работу можно было признать удовлетворительной, но местами наблюдалась некоторая «задумчивость», особенно при открытии динамических списков.
Перейдем к оптимизации. Все изменения следует вносить в файл postgesql.conf, который располагается в Linuх для сборки от 1С по пути /etc/postgres/1x/main, а для сборки от PostgresPro в /var/lib/pgpro/1c-1x/data. В Windows данный файл располагается в каталоге данных, по умолчанию это C:\Program Files\PostgreSQL 1C\1х\data. Все параметры указаны в порядке их следования в конфигурационном файла.
Одним из основных параметров, используемых при расчетах, является объем оперативной памяти. При этом следует использовать то значение, которое вы готовы выделить серверу СУБД, за вычетом ОЗУ используемой ОС и другими службами, скажем, сервером 1С. В нашем случае будет использоваться значение в 24 ГБ.
Затем рассчитаем значения отдельных параметров с помощью калькулятора, для чего укажем ОС и версию Postgres, тип накопителя, количество доступной памяти и количество ядер процессора. В поле DB Type указываем Data Warehouses, количество соединений можем проигнорировать, так как вычисляемый результат будет значительно расходиться с рекомендациями 1С.
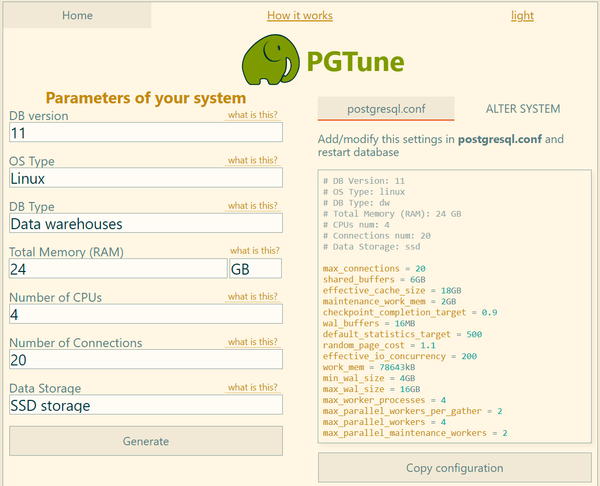 Теперь можно приступать к редактированию файла конфигурации. Многие значения в нем закомментированы и содержат значения по умолчанию, при изменении таких параметров данные строки следует раскомментировать.
Теперь можно приступать к редактированию файла конфигурации. Многие значения в нем закомментированы и содержат значения по умолчанию, при изменении таких параметров данные строки следует раскомментировать.
Максимальное число соединений, 1С рекомендует указанные выше значения, мы установили 1000.
Объем памяти для совместного кеша страниц, разделяется между всеми процессами Postgres, рекомендуемое значение — четверть доступного объема памяти, в нашем случае 6 ГБ.
Верхний лимит для временных таблиц в каждой сессии, рекомендуется фиксированное значение.
Указывает объем памяти, который может быть использован для запроса прежде, чем будут задействованы временные файлы на диске. Применяется для каждого соединения и каждой операции, поэтому итоговый объем используемой памяти может существенно превосходить указанное значение. Это один из тех параметров, вычисляемое значение которого калькулятором существенно отличается от рекомендаций 1С. Для объема памяти в 24 ГБ рекомендуемыми значениями будут 375 — 750 МБ, мы выбрали 512 МБ.
Объем памяти для обслуживающих задач (автовакуум, реиндексация и т.д.), указываем рекомендованный калькулятором объем, в нашем случае 2 ГБ.
Максимальное количество открытых файлов на один процесс, в сборке от PostgresPro для Linux это значение по умолчанию.
Параметры процесса фоновой записи, который отвечает за синхронизацию страниц в shared_buffers с диском.
Допустимое число одновременных операций ввода/вывода. Для жестких дисков указывается по количеству шпинделей, для массивов RAID5/6 следует исключить диски четности. Для SATA SSD это значение рекомендуется указывать равным 200, а для быстрых NVMe дисков его можно увеличить до 500-1000. При этом следует понимать, что высокие значения в сочетании с медленными дисками сделают обратный эффект, поэтому подходите к этой настройке грамотно.
Важно! Параметр effective_io_concurrency настраивается только в среде Linux, в Windows системах его значение должно быть равно нулю.
Настройки фоновых рабочих процессов, выбираются исходя из количества процессорных ядер, берем значения из калькулятора. Выше указаны настройки для четырехъядерного СРU.
Заставляет сервер добиваться физической записи изменений на диск. Выключение данной опции хотя и позволяет повысить производительность, но значительно увеличивает риск неисправимой порчи данных при внезапном выключении питания.
Альтернатива отключению fsync, позволяет серверу не ждать сохранения данных на диске, прежде чем сообщить клиенту об успешном завершении операции. Позволяет достаточно безопасно повысить производительность работы. В случае внезапного выключения питания могут быть потеряны несколько последних транзакций, но сама база останется в рабочем состоянии, также, как и при штатной отмене потерянных транзакций.
Задает размер буферов журнала предзаписи (WAL, он же журнал транзакций), если оставить эту настройку без изменений, то сервер будет автоматически устанавливать это значение в 1/32 от shared_buffers, но не менее 64 КБ и не более размера одного сегмента WAL в 16 МБ.
Указывает задержку в мс перед записью транзакций на диск при числе открытых транзакций, указанных во второй опции. Имеет смысл при количестве транзакций более 1000 в секунду, на меньших значениях эффекта не имеет.
Минимальный и максимальный размер файлов журнала предзаписи. Указываем значения из калькулятора, в нашем случае это 4 ГБ и 16 ГБ.
Скорость записи изменений на диск, рассчитывается как время между точками сохранения транзакций (чекпойнты) умноженное на данный показатель, позволяет растянуть процесс записи по времени и тем самым снизить одномоментную нагрузку на диски. В нашем случае использовано рекомендованное калькулятором максимальное значение 0,9.
Стоимость последовательного чтения с диска, является относительным числом, вокруг которого определяются все остальные переменные стоимости, данное значение является значением по умолчанию.
Стоимость случайного чтения с диска, чем ниже это число, тем более вероятно использование сканирования по индексу, нежели полное считывание таблицы, однако не следует указывать слишком низких, не соответствующих реальной производительности дисковой подсистемы, значений, иначе вы можете получить обратный эффект, когда производительность упрется в медленный случайный доступ.
Так как это относительные значения, но не имеет смысла устанавливать random_page_cost ниже seq_page_cost, однако при применении производительных SSD имеет смысл понизить стоимость обоих значений, чтобы повысить приоритет дисковых операций по отношению к процессорным.
Для производительных SSD можно использовать значения:
Но еще раз напомним, данные значения не являются панацеей и должны устанавливаться осмысленно, с реальным пониманием производительности дисковой подсистемы сервера, бездумное копирование настроек способно привести к обратному эффекту.
Определяет эффективный размер кеша, который может использоваться при одном запросе. Этот параметр не влияет на размер выделяемой памяти, не резервирует ее, а служит для ориентировочной оценки доступного размера кеша планировщиком запросов. Чем он выше, тем большая вероятность использования сканирования по индексу, а не последовательного сканирования. При расчете следует использовать выделенный серверу объем RAM, а не полный объем ОЗУ. В нашем случае это 18 ГБ.
Включение автовакуума, это очень важный для производительности базы параметр. Не отключайте его!
Количество рабочих процессов автовакуума, рассчитывается по числу процессорных ядер, не менее 4, в нашем случае 4.
Время сна процессов автовакуума, большое значение будет приводить к неэффективно работе, слишком малое только повысит нагрузку без видимого эффекта.
Отключает политику защиты на уровне строк, данная опция не используется платформой и ее отключение дает некоторое повышение производительности.
Максимальное количество блокировок в одной транзакции, рекомендация от 1С.
Данные опции специфичны для 1С и регулируют использование символа \ для экранирования.
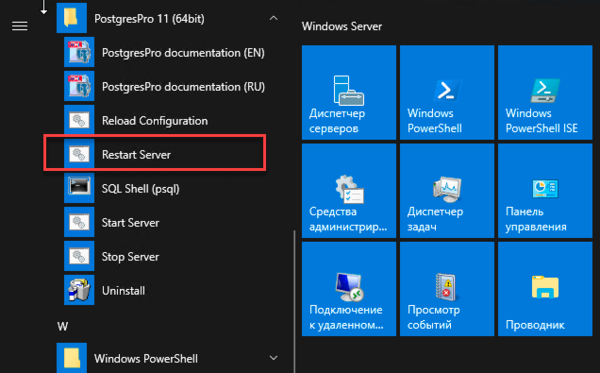
Сохраним файл конфигурации и перезапустим PostgreSQL, в Linux это можно выполнить командами:
В Windows штатными средствами операционной системы, либо скриптами из поставки сборки PostgreSQL:
 После чего снова выполним тестирование производительности, на этот раз мы получили следующий результат:
После чего снова выполним тестирование производительности, на этот раз мы получили следующий результат:
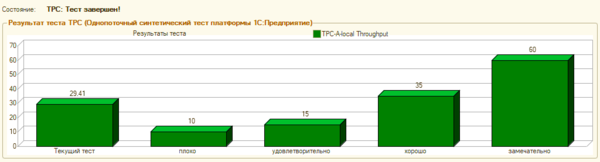 Как видим, достаточно несложные действия по оптимизации добавили серверу около 30% производительности, субъективные ощущения от работы с конфигурацией Розница также повысились, исчезло ощущение «задумчивости», повысилась отзывчивость системы.
Как видим, достаточно несложные действия по оптимизации добавили серверу около 30% производительности, субъективные ощущения от работы с конфигурацией Розница также повысились, исчезло ощущение «задумчивости», повысилась отзывчивость системы.
Указанные выше настройки и параметры являются базовым набором для оптимизации PostgreSQL при совместной работе с 1С:Предприятие и доступны даже начинающим администраторам. Для выполнения этих действий не требуется глубокого понимания работы СУБД, достаточно просто правильно рассчитать ряд значений. Данные рекомендации основаны на официальных и рекомендуются в качестве базовой настройки сервера СУБД сразу после инсталляции.
Shared buffers postgresql windows
Задаёт объём памяти, который будет использовать сервер баз данных для буферов в разделяемой памяти. По умолчанию это обычно 128 мегабайт ( 128MB ), но может быть и меньше, если конфигурация вашего ядра накладывает дополнительные ограничения (это определяется в процессе initdb ). Это значение не должно быть меньше 128 килобайт. (Этот минимум зависит от величины BLCKSZ .) Однако для хорошей производительности обычно требуются гораздо большие значения. Задать этот параметр можно только при запуске сервера.
Если вы используете выделенный сервер с объёмом ОЗУ 1 ГБ и более, разумным начальным значением shared_buffers будет 25% от объёма памяти. Существуют варианты нагрузки, при которых эффективны будут и ещё большие значения shared_buffers , но так как Postgres Pro использует и кеш операционной системы, выделять для shared_buffers более 40% ОЗУ вряд ли будет полезно. При увеличении shared_buffers обычно требуется соответственно увеличить max_wal_size , чтобы растянуть процесс записи большого объёма новых или изменённых данных на более продолжительное время.
В серверах с объёмом ОЗУ меньше 1ГБ следует использовать меньший процент ОЗУ, чтобы оставить достаточно памяти для операционной системы. Кроме того, большие значения shared_buffers не так эффективны в Windows. Возможно, вы получите лучшие результаты, если оставите это значение относительно небольшим и будете больше полагаться на кеш операционной системы. Оптимальные значения shared_buffers для Windows обычно лежат в интервале от 64 до 512 мегабайт. huge_pages ( enum )
Включает/отключает использование огромных страниц памяти. Допустимые значения: try (попытаться, по умолчанию), on (вкл.) и off (выкл.).
В настоящее время это поддерживается только в Linux. В других системах значение try просто игнорируется.
В результате использования огромных страниц уменьшаются таблицы страниц и сокращается время, которое тратит процессор на управление памятью. За подробностями обратитесь к Подразделу 17.4.5.
Когда huge_pages имеет значение try , сервер попытается использовать огромные страницы, но может переключиться на обычные, если это не удастся. Со значением on , если использовать огромные страницы не получится, сервер не будет запущен. Со значением off огромные страницы использоваться не будут. temp_buffers ( integer )
Задаёт максимальное число временных буферов для каждого сеанса, По умолчанию объём временных буферов составляет восемь мегабайт (1024 буфера). Этот параметр можно изменить в отдельном сеансе, но только до первого обращения к временным таблицам; после этого изменить его значение для текущего сеанса не удастся.
Сеанс выделяет временные буферы по мере необходимости до достижения предела, заданного параметром temp_buffers . Если сеанс не задействует временные буферы, то для него хранятся только дескрипторы буферов, которые занимают около 64 байт (в количестве temp_buffers ). Однако если буфер действительно используется, он будет дополнительно занимать 8192 байта (или BLCKSZ байт, в общем случае). max_prepared_transactions ( integer )
Задаёт максимальное число транзакций, которые могут одновременно находиться в « подготовленном » состоянии (см. PREPARE TRANSACTION ). При нулевом значении (по умолчанию) механизм подготовленных транзакций отключается. Задать этот параметр можно только при запуске сервера.
Если использовать транзакции не планируется, этот параметр следует обнулить, чтобы не допустить непреднамеренного создания подготовленных транзакций. Если же подготовленные транзакции применяются, то max_prepared_transactions , вероятно, должен быть не меньше, чем max_connections, чтобы подготовить транзакцию можно было в каждом сеансе.
Для ведомого сервера значение этого параметра должно быть больше или равно значению на ведущем. В противном случае на ведомом сервере не будут разрешены запросы. work_mem ( integer )
Задаёт объём памяти, который будет использоваться для внутренних операций сортировки и хеш-таблиц, прежде чем будут задействованы временные файлы на диске. Значение по умолчанию — четыре мегабайта ( 4MB ). Заметьте, что в сложных запросах одновременно могут выполняться несколько операций сортировки или хеширования, так что этот объём памяти будет доступен для каждой операции. Кроме того, такие операции могут выполняться одновременно в разных сеансах. Таким образом, общий объём памяти может многократно превосходить значение work_mem ; это следует учитывать, выбирая подходящее значение. Операции сортировки используются для ORDER BY , DISTINCT и соединений слиянием. Хеш-таблицы используются при соединениях и агрегировании по хешу, а также обработке подзапросов IN с применением хеша. maintenance_work_mem ( integer )
Задаёт максимальный объём памяти для операций обслуживания БД, в частности VACUUM , CREATE INDEX и ALTER TABLE ADD FOREIGN KEY . По умолчанию его значение — 64 мегабайта ( 64MB ). Так как в один момент времени в сеансе может выполняться только одна такая операция и обычно они не запускаются параллельно, это значение вполне может быть гораздо больше work_mem . Увеличение этого значения может привести к ускорению операций очистки и восстановления БД из копии.
Учтите, что когда выполняется автоочистка, этот объём может быть выделен autovacuum_max_workers раз, поэтому не стоит устанавливать значение по умолчанию слишком большим. Возможно, будет лучше управлять объёмом памяти для автоочистки отдельно, изменяя autovacuum_work_mem. replacement_sort_tuples ( integer )
Когда количество сортируемых кортежей меньше заданного числа, для получения первого потока сортируемых данных будет применяться не алгоритм quicksort, а выбор с замещением. Это может быть полезно в системах с ограниченным объёмом памяти, когда кортежи, поступающие на вход большой операции сортировки, характеризуются хорошей корреляцией физического и логического порядка. Заметьте, что это не относится к кортежам с обратной корреляцией. Вполне возможно, что алгоритм выбора с замещением сформирует один длинный поток и слияние не потребуется, тогда как со стратегией по умолчанию может быть получено много потоков, которые затем потребуется слить для получения окончательного отсортированного результата. Это позволяет ускорить операции сортировки.
Значение по умолчанию — 150000 кортежей. Заметьте, что увеличивать это значение обычно не очень полезно, и может быть даже контрпродуктивно, так как эффективность приоритетной очереди зависит от доступного объёма кеша процессора, тогда как со стандартной стратегией потоки сортируются кеш-независимым алгоритмом. Благодаря этому стандартная стратегия позволяет автоматически и прозрачно использовать доступный кеш процессора более эффективным образом.
Если в maintenance_work_mem задано значение по умолчанию, внешние сортировки в служебных командах (например, сортировки, выполняемые командами CREATE INDEX для построения-индекса B-дерева) обычно никогда не используют алгоритм выбора с замещением (так как все кортежи помещаются в память), кроме случаев, когда входные кортежи достаточно велики. autovacuum_work_mem ( integer )
Задаёт максимальный объём памяти, который будет использовать каждый рабочий процесс автоочистки. По умолчанию равен -1, что означает, что этот объём определяется значением maintenance_work_mem. Этот параметр не влияет на поведение команды VACUUM , выполняемой в других контекстах. max_stack_depth ( integer )
Задаёт максимальную безопасную глубину стека для исполнителя. В идеале это значение должно равняться предельному размеру стека, ограниченному ядром (который устанавливается командой ulimit -s или аналогичной), за вычетом запаса примерно в мегабайт. Этот запас необходим, потому что сервер проверяет глубину стека не в каждой процедуре, а только в потенциально рекурсивных процедурах, например, при вычислении выражений. Значение по умолчанию — два мегабайта ( 2MB ) — выбрано с большим запасом, так что риск переполнения стека минимален. Но с другой стороны, его может быть недостаточно для выполнения сложных функций. Изменить этот параметр могут только суперпользователи.
Если max_stack_depth будет превышать фактический предел ядра, то функция с неограниченной рекурсией сможет вызвать крах отдельного процесса сервера. В системах, где Postgres Pro может определить предел, установленный ядром, он не позволит установить для этого параметра небезопасное значение. Однако эту информацию выдают не все системы, поэтому выбирать это значение следует с осторожностью. dynamic_shared_memory_type ( enum )
Выбирает механизм динамической разделяемой памяти, который будет использоваться сервером. Допустимые варианты: posix (для выделения разделяемой памяти POSIX функцией shm_open ), sysv (для выделения разделяемой памяти System V функцией shmget ), windows (для выделения разделяемой памяти в Windows), mmap (для эмуляции разделяемой памяти через отображение в память файлов, хранящихся в каталоге данных) и none (для отключения этой функциональности). Не все варианты поддерживаются на разных платформах; первый из поддерживаемых данной платформой вариантов становится для неё вариантом по умолчанию. Применять mmap , который нигде не выбирается по умолчанию, вообще не рекомендуется, так как операционная система может периодически записывать на диск изменённые страницы, что создаст дополнительную нагрузку; однако это может быть полезно для отладки, когда каталог pg_dynshmem находится на RAM-диске или когда другие механизмы разделяемой памяти недоступны.
18.4.2. Диск
Задаёт максимальный объём дискового пространства, который сможет использовать один процесс для временных файлов, например, при сортировке и хешировании, или для сохранения удерживаемого курсора. Транзакция, которая попытается превысить этот предел, будет отменена. Этот параметр задаётся в килобайтах, а значение -1 (по умолчанию) означает, что предел отсутствует. Изменить этот параметр могут только суперпользователи.
Этот параметр ограничивает общий объём, который могут занимать в момент времени все временные файлы, задействованные в данном процессе Postgres Pro . Следует отметить, что при этом учитывается только место, занимаемое явно создаваемыми временными таблицами; на временные файлы, которые создаются неявно при выполнении запроса, это ограничение не распространяется.
18.4.3. Использование ресурсов ядра
Задаёт максимальное число файлов, которые могут быть одновременно открыты каждым серверным подпроцессом. Значение по умолчанию — 1000 файлов. Если ядро реализует безопасное ограничение по процессам, об этом параметре можно не беспокоиться. Но на некоторых платформах (а именно, в большинстве систем BSD) ядро позволяет отдельному процессу открыть больше файлов, чем могут открыть несколько процессов одновременно. Если вы столкнётесь с ошибками « Too many open files » (Слишком много открытых файлов), попробуйте уменьшить это число. Задать этот параметр можно только при запуске сервера.
18.4.4. Задержка очистки по стоимости
Во время выполнения команд VACUUM и ANALYZE система ведёт внутренний счётчик, в котором суммирует оцениваемую стоимость различных выполняемых операций ввода/вывода. Когда накопленная стоимость превышает предел ( vacuum_cost_limit ), процесс, выполняющий эту операцию, засыпает на некоторое время ( vacuum_cost_delay ). Затем счётчик сбрасывается и процесс продолжается.
Данный подход реализован для того, чтобы администраторы могли снизить влияние этих команд на параллельную работу с базой, за счёт уменьшения нагрузки на подсистему ввода-вывода. Очень часто не имеет значения, насколько быстро выполнятся команды обслуживания (например, VACUUM и ANALYZE ), но очень важно, чтобы они как можно меньше влияли на выполнение других операций с базой данных. Администраторы имеют возможность управлять этим, настраивая задержку очистки по стоимости.
По умолчанию этот режим отключён для выполняемых вручную команд VACUUM . Чтобы включить его, нужно установить в vacuum_cost_delay ненулевое значение.
Продолжительность времени, в миллисекундах, в течение которого будет простаивать процесс, превысивший предел стоимости. По умолчанию его значение равно нулю, то есть задержка очистки отсутствует. При положительных значениях интенсивность очистки будет зависеть от стоимости. Заметьте, что во многих системах разрешение таймера составляет 10 мс, поэтому если задать в vacuum_cost_delay значение, не кратное 10, фактически будет получен тот же результат, что и со следующим за ним кратным 10.
При настройке интенсивности очистки для vacuum_cost_delay обычно выбираются довольно небольшие значения, например 10 или 20 миллисекунд. Чтобы точнее ограничить потребление ресурсов при очистке, лучше всего изменять другие параметры стоимости очистки. vacuum_cost_page_hit ( integer )
Примерная стоимость очистки буфера, оказавшегося в общем кеше. Это подразумевает блокировку пула буферов, поиск в хеш-таблице и сканирование содержимого страницы. По умолчанию этот параметр равен одному. vacuum_cost_page_miss ( integer )
Примерная стоимость очистки буфера, который нужно прочитать с диска. Это подразумевает блокировку пула буферов, поиск в хеш-таблице, чтение требуемого блока с диска и сканирование его содержимого. По умолчанию этот параметр равен 10. vacuum_cost_page_dirty ( integer )
Примерная стоимость очистки, при которой изменяется блок, не модифицированный ранее. В неё включается дополнительная стоимость ввода/вывода, связанная с записью изменённого блока на диск. По умолчанию этот параметр равен 20. vacuum_cost_limit ( integer )
Общая стоимость, при накоплении которой процесс очистки будет засыпать. По умолчанию этот параметр равен 200.
Примечание
Некоторые операции устанавливают критические блокировки и поэтому должны завершаться как можно быстрее. Во время таких операций задержка очистки по стоимости не осуществляется, так что накопленная за это время стоимость может намного превышать установленный предел. Во избежание ненужных длительных задержек в таких случаях, фактическая задержка вычисляется по формуле vacuum_cost_delay * accumulated_balance / vacuum_cost_limit и ограничивается максимумом, равным vacuum_cost_delay * 4.
18.4.5. Фоновая запись
В числе специальных процессов сервера есть процесс фоновой записи, задача которого — осуществлять запись « грязных » (новых или изменённых) общих буферов на диск. Он старается записывать данные из буферов так, чтобы обычным серверным процессам, обрабатывающим запросы, не приходилось ждать записи или это ожидание было минимальным. Однако процесс фоновой записи увеличивает общую нагрузку на подсистему ввода/вывода, так как он может записывать неоднократно изменяемую страницу при каждом изменении, тогда как она может быть записана всего раз в контрольной точке. Параметры, рассматриваемые в данном подразделе, позволяют настроить поведение фоновой записи для конкретных нужд.
Задаёт задержку между раундами активности процесса фоновой записи. Во время раунда этот процесс осуществляет запись некоторого количества загрязнённых буферов (это настраивается следующими параметрами). Затем он засыпает на время bgwriter_delay (задаваемое в миллисекундах), и всё повторяется снова. Однако если в пуле не остаётся загрязнённых буферов, он может быть неактивен более длительное время. По умолчанию этот параметр равен 200 миллисекундам ( 200ms ). Заметьте, что во многих системах разрешение таймера составляет 10 мс, поэтому если задать в bgwriter_delay значение, не кратное 10, фактически будет получен тот же результат, что и со следующим за ним кратным 10. Задать этот параметр можно только в postgresql.conf или в командной строке при запуске сервера. bgwriter_lru_maxpages ( integer )
Задаёт максимальное число буферов, которое сможет записать процесс фоновой записи за раунд активности. При нулевом значении фоновая запись отключается. (Учтите, что на контрольные точки, которые управляются отдельным вспомогательным процессом, это не влияет.) По умолчанию значение этого параметра — 100 буферов. Задать этот параметр можно только в postgresql.conf или в командной строке при запуске сервера. bgwriter_lru_multiplier ( floating point )
Число загрязнённых буферов, записываемых в очередном раунде, зависит от того, сколько новых буферов требовалось серверным процессам в предыдущих раундах. Средняя недавняя потребность умножается на bgwriter_lru_multiplier и предполагается, что именно столько буферов потребуется на следующем раунде. Процесс фоновой записи будет записывать на диск и освобождать буферы, пока число свободных буферов не достигнет целевого значения. (При этом число буферов, записываемых за раунд, ограничивается сверху параметром bgwriter_lru_maxpages .) Таким образом, со множителем, равным 1.0, записывается ровно столько буферов, сколько требуется по предположению ( « точно по плану » ). Увеличение этого множителя даёт некоторую страховку от резких скачков потребностей, тогда как уменьшение отражает намерение оставить некоторый объём записи для серверных процессов. По умолчанию он равен 2.0. Этот параметр можно установить только в файле postgresql.conf или в командной строке при запуске сервера. bgwriter_flush_after ( integer )
Когда процессом фоновой записи записывается больше чем bgwriter_flush_after байт, сервер даёт указание ОС произвести запись этих данных в нижележащее хранилище. Это ограничивает объём «грязных» данных в страничном кеше ядра и уменьшает вероятность затормаживания при выполнении fsync в конце контрольной точки или когда ОС сбрасывает данные на диск большими порциями в фоне. Часто это значительно уменьшает задержки транзакций, но бывают ситуации (особенно когда объём рабочей нагрузки больше shared_buffers, но меньше страничного кеша ОС), когда производительность может упасть. Этот параметр действует не на всех платформах. Он может принимать значение от 0 (при этом управление отложенной записью отключается) до 2 мегабайт ( 2MB ). Значение по умолчанию — 512kB в Linux и 0 в других ОС. (Если BLCKSZ отличен от 8 КБ, значение по умолчанию и максимум корректируются пропорционально.) Задать этот параметр можно только в postgresql.conf или в командной строке при запуске сервера.
С маленькими значениями bgwriter_lru_maxpages и bgwriter_lru_multiplier уменьшается активность ввода/вывода со стороны процесса фоновой записи, но увеличивается вероятность того, что запись придётся производить непосредственно серверным процессам, что замедлит выполнение запросов.
18.4.6. Асинхронное поведение
Задаёт допустимое число параллельных операций ввода/вывода, которое говорит Postgres Pro о том, сколько операций ввода/вывода могут быть выполнены одновременно. Чем больше это число, тем больше операций ввода/вывода будет пытаться выполнить параллельно Postgres Pro в отдельном сеансе. Допустимые значения лежат в интервале от 1 до 1000, а нулевое значение отключает асинхронные запросы ввода/вывода. В настоящее время этот параметр влияет только на сканирование по битовой карте.
Для магнитных носителей хорошим начальным значением этого параметра будет число отдельных дисков, составляющих массив RAID 0 или RAID 1, в котором размещена база данных. (Для RAID 5 следует исключить один диск (как диск с чётностью).) Однако, если база данных часто обрабатывает множество запросов в различных сеансах, и при небольших значениях дисковый массив может быть полностью загружен. Если продолжать увеличивать это значение при полной загрузке дисков, это приведёт только к увеличению нагрузки на процессор. Диски SSD и другие виды хранилища в памяти часто могут обрабатывать множество параллельных запросов, так что оптимальным числом может быть несколько сотен.
Асинхронный ввод/вывод зависит от эффективности функции posix_fadvise , которая отсутствует в некоторых операционных системах. В случае её отсутствия попытка задать для этого параметра любое ненулевое значение приведёт к ошибке. В некоторых системах (например, в Solaris), эта функция присутствует, но на самом деле ничего не делает.
Значение по умолчанию равно 1 в системах, где это поддерживается, и 0 в остальных. Это значение можно переопределить для таблиц в определённом табличном пространстве, установив одноимённый параметр табличного пространства (см. ALTER TABLESPACE ). max_worker_processes ( integer )
Задаёт максимальное число фоновых процессов, которое можно запустить в текущей системе. Этот параметр можно задать только при запуске сервера. Значение по умолчанию — 8.
Для ведомого сервера значение этого параметра должно быть больше или равно значению на ведущем. В противном случае на ведомом сервере не будут разрешены запросы. max_parallel_workers_per_gather ( integer )
Задаёт максимальное число рабочих процессов, которые могут запускаться одним узлом Gather . Параллельные рабочие процессы берутся из пула процессов, контролируемого параметром max_worker_processes. Учтите, что запрошенное количество рабочих процессов может быть недоступно во время выполнения. В этом случае план будет выполняться с меньшим числом процессов, что может быть неэффективно. Значение 0 (заданное по умолчанию) отключает параллельное выполнение запросов.
Учтите, что параллельные запросы могут потреблять значительно больше ресурсов, чем не параллельные, так как каждый рабочий процесс является отдельным процессом и оказывает на систему примерно такое же влияние, как дополнительный пользовательский сеанс. Это следует учитывать, выбирая значение этого параметра, а также настраивая другие параметры, управляющие использованием ресурсов, например work_mem. Ограничения ресурсов, такие как work_mem , применяются к каждому рабочему процессу отдельно, что означает, что общая нагрузка для всех процессов может оказаться гораздо больше, чем при обычном использовании одного процесса. Например, параллельный запрос, задействующий 4 рабочих процесса, может использовать в 5 раз больше времени процессора, объёма памяти, ввода/вывода и т. д., по сравнению с запросом, не задействующим рабочие процессы вовсе.
За дополнительными сведениями о параллельных запросах обратитесь к Главе 15. backend_flush_after ( integer )
Когда одним обслуживающим процессом записывается больше backend_flush_after байт, сервер даёт указание ОС произвести запись этих данных в нижележащее хранилище. Это ограничивает объём «грязных» данных в страничном кеше ядра и уменьшает вероятность затормаживания при выполнении fsync в конце контрольной точки или когда ОС сбрасывает данные на диск большими порциями в фоне. Часто это значительно сокращает задержки транзакций, но бывают ситуации (особенно когда объём рабочей нагрузки больше shared_buffers, но меньше страничного кеша ОС), когда производительность может упасть. Этот параметр действует не на всех платформах. Он может принимать значение от 0 (при этом управление отложенной записью отключается) до 2 мегабайт ( 2MB ). По умолчанию он имеет значение 0 , то есть это поведение отключено. (Если BLCKSZ отличен от 8 КБ, максимальное значение корректируется пропорционально.) old_snapshot_threshold ( integer )
Задаёт минимальное время, которое можно пользоваться снимком без риска получить ошибку снимок слишком стар . Этот параметр можно задать только при запуске сервера.
По истечении этого времени старые данные могут быть вычищены. Это предотвращает замусоривание данными снимков, которые остаются задействованными долгое время. Во избежание получения некорректных результатов из-за очистки данных, которые должны были бы наблюдаться в снимке, клиенту будет выдана ошибка, если возраст снимка превысит заданный предел и из этого снимка будет запрошена страница, изменённая со времени его создания.
Значение -1 (по умолчанию) отключает это поведение. Полезные значения для производственной среды могут лежать в интервале от нескольких часов до нескольких дней. Заданное значение округляется до минут, а минимальные значения (как например, 0 или 1min ) допускаются только потому, что они могут быть полезны при тестировании. Хотя допустимым будет и значение 60d (60 дней), учтите, что при многих видах нагрузки критичное замусоривание базы или зацикливание идентификаторов транзакций может происходить в намного меньших временных отрезках.
Когда это ограничение действует, освобождённое пространство в конце отношения не может быть отдано операционной системе, так как при этом будет удалена информация, необходимая для выявления условия снимок слишком стар . Всё пространство, выделенное отношению, останется связанным с ним до тех пор, пока не будет освобождено явно (например, с помощью команды VACUUM FULL ).
Установка этого параметра не гарантирует, что обозначенная ошибка будет выдаваться при всех возможных обстоятельствах. На самом деле, если можно получить корректные результаты, например, из курсора, материализовавшего результирующий набор, ошибка не будет выдана, даже если нижележащие строки в целевой таблице были ликвидированы при очистке. Некоторые таблицы не могут быть безопасно очищены в сжатые сроки, так что на них этот параметр не распространяется. В частности, это касается системных каталогов и таблиц с хеш-индексами. Для таких таблиц этот параметр не сокращает раздувание, но и не чреват ошибкой снимок слишком стар при сканировании.