Таблица кодов windows 1251 для русских букв
БлогNot. Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
Во-первых, напомню, что Юникод — не кодировка, а стандарт кодирования, кодировки — это UTF-8, UTF-16 и т.д., но, в силу инерции, разработчики и пользователи часто говорят о «кодировке Юникод», имея в виду распространённую именно в их деревне форму представления символов 🙂
Во-вторых, на самом деле кодирование там довольно замудрённое, возьмём, скажем русскую заглавную «Ж».
Представляемые в Юникоде символы кодируются целыми числами без знака, их можно называть «кодами символов Unicode».
Так, для буквы «Ж» Unicode = 104610 или 041616 или 10000 0101102. Unicode в двоичном виде разбивается на две части: пять левых бит и шесть правых. Левая часть в старших разрядах дополняется до байта признаком 110 двухбайтного кода UTF-8, получаем 11010000. К правой части в старших разрядах приписываются два бита 10 признака продолжения многобайтного кода, получаем 10010110. Окончательно код буквы «Ж» в UTF-8 будет иметь вид 11010000 100101102 или D0 9616.
Именно последний код мы увидим в любом 16-ричном вьюере файла, например, создав в текстовом редакторе файл со словом «Жора» и сохранив его в UTF-8 (только не из Блокнотика Windows, который добавит в начало файла 3-байтовую метку BOM):
То есть, каждая буква кодируется как бы дважды, сначала в 11-битный Unicode, затем в 16-битный UTF-8.
Ниже приведена таблица кодов кириллицы в Unicode, UTF-8 и однобайтовой кодировке Windows-1251.
| Символ | Unicode | UTF-8 | Windows-1251 | ||
|---|---|---|---|---|---|
| 16-ричн. | 10-тичн. | 16-ричн. | 10-тичн. | ||
| А | 0410 | 1040 | D090 | 208 144 | 192 |
| Б | 0411 | 1041 | D091 | 208 145 | 193 |
| В | 0412 | 1042 | D092 | 208 146 | 194 |
| Г | 0413 | 1043 | D093 | 208 147 | 195 |
| Д | 0414 | 1044 | D094 | 208 148 | 196 |
| Е | 0415 | 1045 | D095 | 208 149 | 197 |
| Ж | 0416 | 1046 | D096 | 208 150 | 198 |
| З | 0417 | 1047 | D097 | 208 151 | 199 |
| И | 0418 | 1048 | D098 | 208 152 | 200 |
| Й | 0419 | 1049 | D099 | 208 153 | 201 |
| К | 041A | 1050 | D09A | 208 154 | 202 |
| Л | 041B | 1051 | D09B | 208 155 | 203 |
| М | 041C | 1052 | D09C | 208 156 | 204 |
| Н | 041D | 1053 | D09D | 208 157 | 205 |
| О | 041E | 1054 | D09E | 208 158 | 206 |
| П | 041F | 1055 | D09F | 208 159 | 207 |
| Р | 0420 | 1056 | D0A0 | 208 160 | 208 |
| С | 0421 | 1057 | D0A1 | 208 161 | 209 |
| Т | 0422 | 1058 | D0A2 | 208 162 | 210 |
| У | 0423 | 1059 | D0A3 | 208 163 | 211 |
| Ф | 0424 | 1060 | D0A4 | 208 164 | 212 |
| Х | 0425 | 1061 | D0A5 | 208 165 | 213 |
| Ц | 0426 | 1062 | D0A6 | 208 166 | 214 |
| Ч | 0427 | 1063 | D0A7 | 208 167 | 215 |
| Ш | 0428 | 1064 | D0A8 | 208 168 | 216 |
| Щ | 0429 | 1065 | D0A9 | 208 169 | 217 |
| Ъ | 042A | 1066 | D0AA | 208 170 | 218 |
| Ы | 042B | 1067 | D0AB | 208 171 | 219 |
| Ь | 042C | 1068 | D0AC | 208 172 | 220 |
| Э | 042D | 1069 | D0AD | 208 173 | 221 |
| Ю | 042E | 1070 | D0AE | 208 174 | 222 |
| Я | 042F | 1071 | D0AF | 208 175 | 223 |
| а | 0430 | 1072 | D0B0 | 208 176 | 224 |
| б | 0431 | 1073 | D0B1 | 208 177 | 225 |
| в | 0432 | 1074 | D0B2 | 208 178 | 226 |
| г | 0433 | 1075 | D0B3 | 208 179 | 227 |
| д | 0434 | 1076 | D0B4 | 208 180 | 228 |
| е | 0435 | 1077 | D0B5 | 208 181 | 229 |
| ж | 0436 | 1078 | D0B6 | 208 182 | 230 |
| з | 0437 | 1079 | D0B7 | 208 183 | 231 |
| и | 0438 | 1080 | D0B8 | 208 184 | 232 |
| й | 0439 | 1081 | D0B9 | 208 185 | 233 |
| к | 043A | 1082 | D0BA | 208 186 | 234 |
| л | 043B | 1083 | D0BB | 208 187 | 235 |
| м | 043C | 1084 | D0BC | 208 188 | 236 |
| н | 043D | 1085 | D0BD | 208 189 | 237 |
| о | 043E | 1086 | D0BE | 208 190 | 238 |
| п | 043F | 1087 | D0BF | 208 191 | 239 |
| р | 0440 | 1088 | D180 | 209 128 | 240 |
| с | 0441 | 1089 | D181 | 209 129 | 241 |
| т | 0442 | 1090 | D182 | 209 130 | 242 |
| у | 0443 | 1091 | D183 | 209 131 | 243 |
| ф | 0444 | 1092 | D184 | 209 132 | 244 |
| х | 0445 | 1093 | D185 | 209 133 | 245 |
| ц | 0446 | 1094 | D186 | 209 134 | 246 |
| ч | 0447 | 1095 | D187 | 209 135 | 247 |
| ш | 0448 | 1096 | D188 | 209 136 | 248 |
| щ | 0449 | 1097 | D189 | 209 137 | 249 |
| ъ | 044A | 1098 | D18A | 209 138 | 250 |
| ы | 044B | 1099 | D18B | 209 139 | 251 |
| ь | 044C | 1100 | D18C | 209 140 | 252 |
| э | 044D | 1101 | D18D | 209 141 | 253 |
| ю | 044E | 1102 | D18E | 209 142 | 254 |
| я | 044F | 1103 | D18F | 209 143 | 255 |
| Символы вне общего правила | |||||
| Ё | 0401 | 1025 | D001 | 208 101 | 168 |
| ё | 0451 | 1105 | D191 | 209 145 | 184 |
23.09.2018, 12:37; рейтинг: 30197
Таблицы кодировок ASCII, CP1251 (windows1251), ISO-8859-5
Таблица ASCII
Таблица ASCII (American standard code for information interchange) является мировым стандартом для кодирования букв английского алфавита, популярных спец символов (! $ # % & и т.д.) и некоторых непечатных символов (например, возврат каретки 0x0D и перенос строки 0х0А).
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.
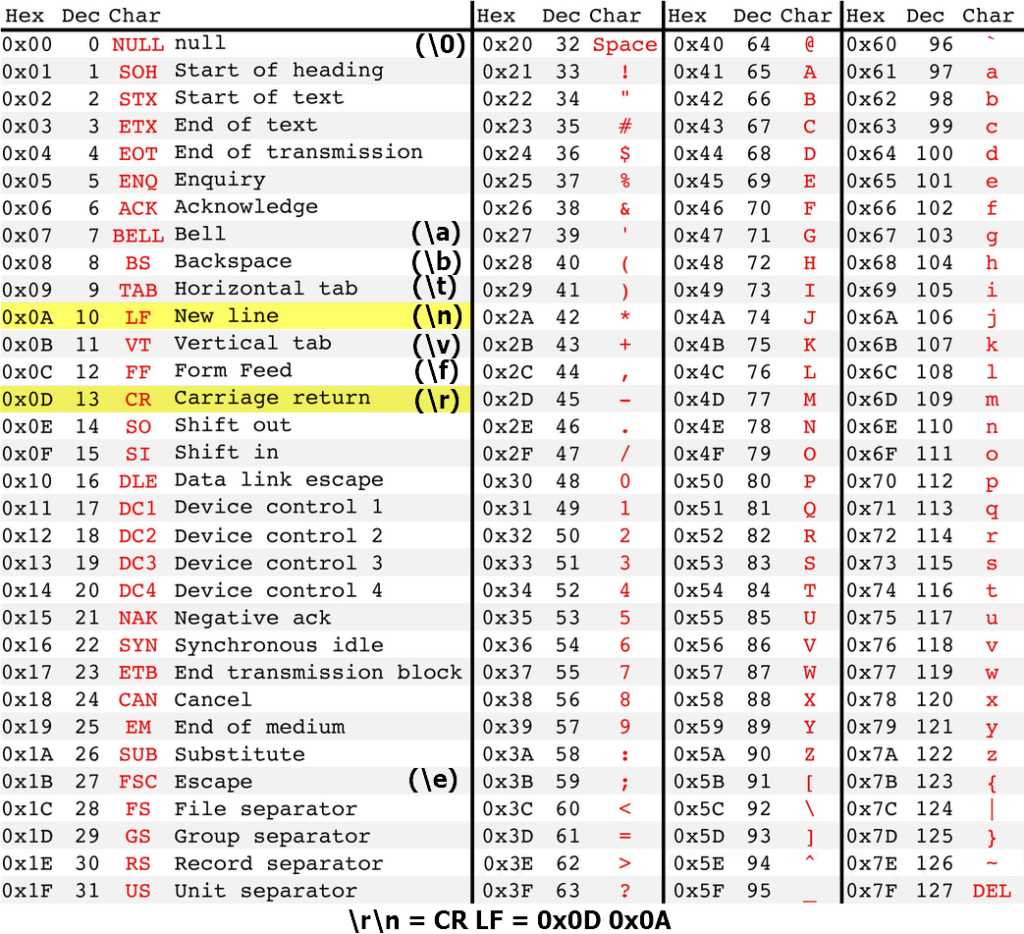
Таблица CP1251 (windows-1251)
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.
Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.

Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.
Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.
Кодирование текстовой информации
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Вспомним некоторые известные нам факты:
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации: N = 2 b ,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер
Символ
0 — 31
00000000 — 00011111
Символы с номерами от 0 до 31 принято называть управляющими.
Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п.
32 — 127
00100000 — 01111111
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы.
Символ 32 — пробел, т.е. пустая позиция в тексте.
Все остальные отражаются определенными знаками.
128 — 255
10000000 — 11111111
Альтернативная часть таблицы (русская).
Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.
Первая половина таблицы кодов ASCII
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Вторая половина таблицы кодов ASCII
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 («CP» означает «Code Page», «кодовая страница»).
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.