The OCR Software Blog
Updates on OCR and Cloud vision.
Tesseract OCR Software GUI
Welcome to the official home page for the (a9t9) Free OCR for Windows Desktop В tool.В As the name suggests, it extracts text from image files and PDF items. It uses the open-source Tesseract OCR engine from HP/Google for OCR processing.
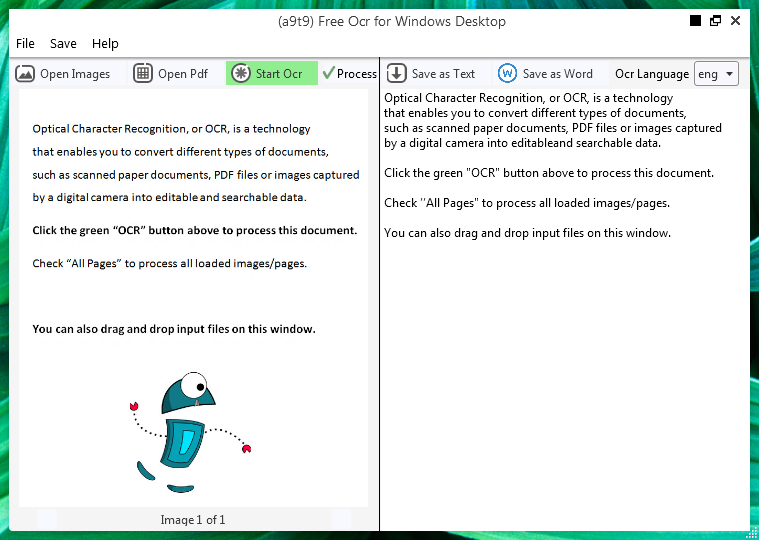 TScreenshot of (a9t9) Free OCR for Windows Desktop — a modern open source Tesseract GUI
TScreenshot of (a9t9) Free OCR for Windows Desktop — a modern open source Tesseract GUI
Why useВ (a9t9) Free OCR for Windows Desktop?
- The application is simple to install/uninstall, and very easy to use
- Free to use
- 100% adware and spyware free
- Uses the well-known Tesseract OCR engine (so essentially it is a modern Tesseract GUI)
- You can improve and customize it — it is open source (GPL)
В If you have not done it yet, download the installer here:
30MB, runs on Win 7 and higher)
 The OCR software includes full PDF support (powered by Ghostscript).
The OCR software includes full PDF support (powered by Ghostscript).
How to get started:
You can open an image or PDF file. The content of the source file will be displayed in the left window. If your document has more than one page, or if you opened multi-page documents, use the arrows at the bottom to navigate between them,
You start the OCR by clicking the green Start Ocr , and you will see the result in the right window. Output text can be saved as a text file or Word document.
Unfortunately the conversion quality is not so great. Behind the scene it uses the Tesseract open-source OCR engine. Its quality varies from language to language — so go ahead and test if it is sufficient for your needs.
Tips for better recognition results:
Tesseract’s output will be very poor quality if the input images are not preprocessed to suit it:
- Images (especially screenshots) must be scaled up such that the text height is at least 20 pixels.
- Any rotation or skew must be corrected or no text will be recognized,
- Dark borders must be manually removed, or they will be misinterpreted as characters.
Still need better text recognition results? Then try these new alternatives:
1. Online OCR — our free web-based OCR app. 2. OCR API — our free web API**, includes OCR command line examples with cURL.
3. Windows 8 OCR software — our free, open-source (GPL) Windows Store OCR app.
Both new services use a different OCR component and have much better text recognition rates than the Tesseract-based OCR desktop software on this page.
For software developers and geeks:
The (a9t9)В Free OCR for Windows Desktop tool is a graphical user interface front-end (GUI) for the Tesseract engine. It isВ written in C#/WPF and the full source code is available as ready-to-compile Microsoft Visual Studio 2013 projectВ on GitHubВ under the GPL V2 open source license. В Feedback of all kind is welcome, especially ideas on how to improve the OCR quality. In theВ Best OCR Software review on this blog the mediocre OCR performance of Tesseract was on of the Five OCR surprisesВ of this test.
How to add more languages
One of the key advantages of the Tessearct engine is the wide variety of supported В OCR languages — it even includes Esperanto! The (a9t9) Free OCR for Windows Desktop installer includes English (ENG), Spanish (SPA) and German (GER). To add more languages just follow these three steps:
- Download the language file you need from Google code, for example Chinese (Traditional).
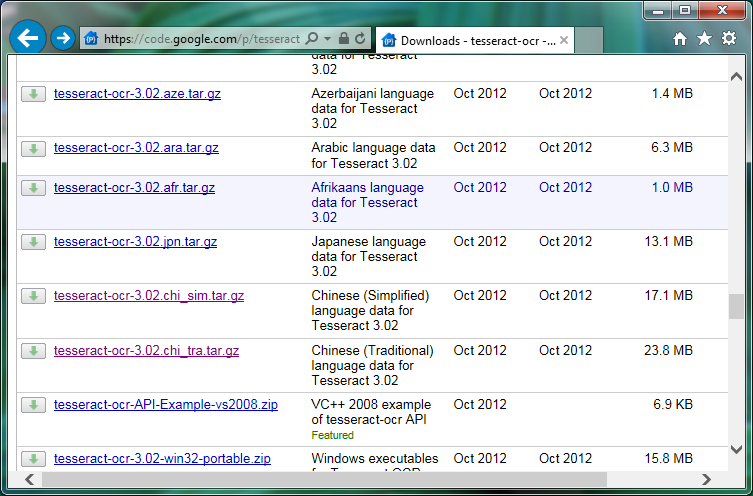 TTesseract language download section
TTesseract language download section
- Un”zip” the download (first the .gz file, and then the .tar file inside). If you have no software to manage compressed archives yet, get free 7zip tool. It is a great choice.
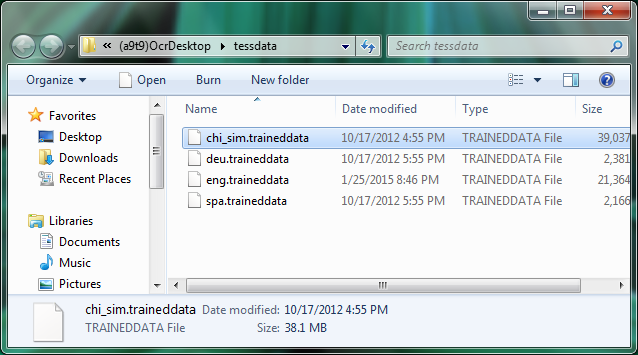 Example: Adding Simplified Chinese as OCR language to the /tessdata folder
Example: Adding Simplified Chinese as OCR language to the /tessdata folder
- Copy the files into the tessdata language folder on your PC. You find that folder easily by opening it from inside the application. In the menu of the OCR software go to the Help > Open Language Folder — and a new Explorer window opens.
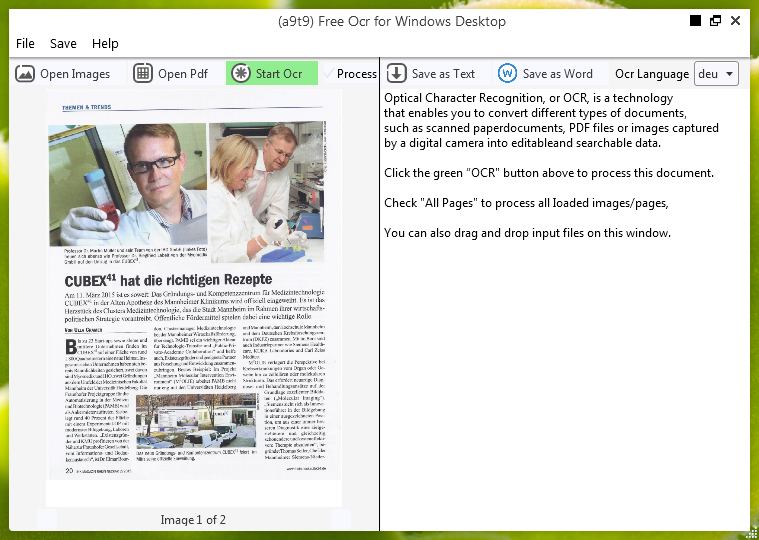
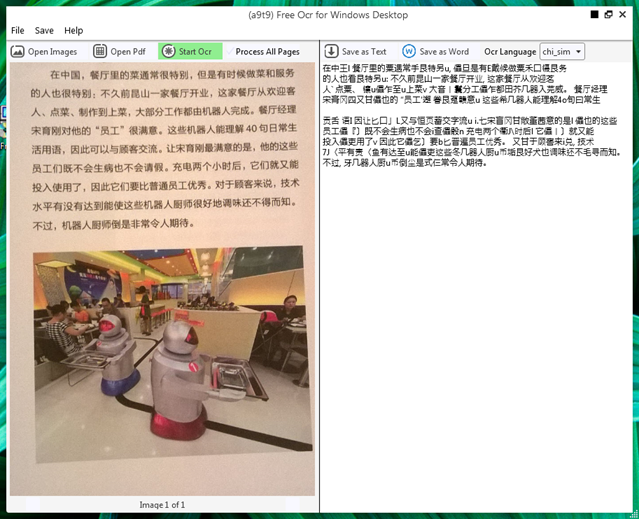 (a9t9) Free OCR for Windows Desktop ocr’ing a mobile phone image of a Chinese magazine article.
(a9t9) Free OCR for Windows Desktop ocr’ing a mobile phone image of a Chinese magazine article.
The Tesseract OCR results are mediocre, but still better than transcribing the text yourself
Now start the software again and the new language appears in the OCR language selection drop down as abbreviated code, e. g. ENG for English, SPA for Spanish, GER for German, POR for Portugese , CHI_TRA for traditional Chinese character support or CHI_SIM for simplified Chinese character support.
Favicon
Блог по web технологиям. Веб студия г. Воронеж. Создание и поддержка сайтов на заказ.
Обучаем вместе с Tesseract OCR
Tesseract — свободная платформа для оптического распознавания текста, исходники которой Google подарил сообществу в 2006 году. Если вы пишете софт для распознавания текста, то вам наверняка приходилось обращаться к услугам этой мощной библиотеки. И если она не справилась с вашим текстом (а скорее всего это именно так), то выход у вас остаётся один — научить её. Процесс этот достаточно сложный и изобилует не очевидными, а порой и прям-таки магическими действиями.
Оригинальный проект находится на гитхабе, а скачать установщик можно здесь, На момент написания статьи версия установщика была 3.05.01. Мне понадобилось немало времени на постижение всей его глубины, поэтому я решил написать что и как, вдруг забуду что-то в будущем, а также чтобы помочь другим пройти этот путь в следующий раз быстрее.
0. Что нам нужно
- Tesseract собственно.
Сборки этой библиотеки есть под windows (можно скачать установщик отсюда) и под linux. Для большинства linux-дистрибутивов установить tesseract можно просто через sudo apt-get install tesseract-ocr.
- Изображение с текстом для тренировки
Желательно чтобы это был реальный текст, который потом придётся распознавать. Важно, чтобы каждый символ шрифта встречался в сканированном фрагменте не менее 5 раз, а желательно — 20 раз. Использовать будем формат tiff, без сжатия, желательно не многостраничный, но можно и многостраничный. Создать многостраничный tiff можно с помощью просмотрщика IrfanView .
Между всеми символами должны быть чётко различимые промежутки. Кладём наше изображение в отдельную директорию и называем в виде . .exp .tif. Изображение может быть не одно и отличаться они должны только номером в наименовании файла. Формат наименований файлов очень важен. На файлы с неверными наименованиями утилиты, которые мы будем использовать будут ругаться ошибками сегментирования и т.п. Для определённости будем считать, что изучаем мы язык ссс и шрифт eee. Таким образом называем файл со сканом тренировочного образца ccc.eee.exp0.tif
1. Создаём и редактируем box-файл
Для того чтобы отметить символы на изображении и задать им соответствие utf-8 символам текста служат box-файлы. Это обычные текстовые файлы, в которых каждому символу соответствует строка с символом и координатами прямоугольника в пикселях. Первоначально файл генерируем утилитой из пакета tesseract:
tesseract ccc.eee.exp0.tif ccc.eee.exp0 batch.nochop makebox
получим файл
в текущей директории. Заглянем в него. Да, чуть не забыл, не забудьте прописать адрес установленной Tesseract-OCR в переменную среды Path в windows, иначе команда tesseract не будет работать в консоли.
Символы в начале строки полностью соответствуют символам в файле? Если это так, то тренировать ничего не нужно, вы можете спать спокойно. В нашем случае скорее всего символы не будут совпадать ни по существу ни по количеству. Т.е. tesseract со словарём по умолчанию не распознал не только символы, но и посчитал некоторые из них за два или больше. Возможно часть символов у нас «слипнется», т.е. попадёт в общую коробку и будет распознано как один. Это всё нужно поправить прежде чем идти дальше.
Работа нудная и кропотливая, но к счастью для этого есть ряд сторонних утилит. Я например пользовался jTessBoxEditor. Открываем им изображение, box-файл с таким же именем он сам подтянет (главное чтобы всё лежало в одной папке).
Переходим на вкладку Box Editor перетаскиваем туда наше изображение, либо жмем Open . Поигравшись немного с вкладками Box Coordinates , где с помощью кнопок Merge , Split , Insert , Delete можно соответственно объединить, разделить, добавить или удалить символы, дабы привести все в соответствии с изображением справа. Во вкладке Box View можно поправить координаты распознаваемого символа.
Прошло полдня… Вы с чувством глубокого удовлетворения закрываете jTessBoxEditor (вы ведь не забыли сохранить результат, верно?) и у вас есть корректный box-файл. Теперь можно переходить к следующему этапу.
tesseract-ocr
Grow your team on GitHub
GitHub is home to over 50 million developers working together. Join them to grow your own development teams, manage permissions, and collaborate on projects.
Pinned repositories 

Tesseract Open Source OCR Engine (main repository)
Best (most accurate) trained LSTM models.
Trained models with support for legacy and LSTM OCR engine
Repositories
tessdata
Trained models with support for legacy and LSTM OCR engine
2 Updated Oct 20, 2020
tesseract
Tesseract Open Source OCR Engine (main repository)
13 Updated Oct 20, 2020
tesstrain
Train Tesseract LSTM with make
3 Updated Oct 13, 2020
tessdoc
4 Updated Oct 6, 2020
langdata_lstm
Data used for LSTM model training
3 Updated Jul 5, 2020
tessdata_best
Best (most accurate) trained LSTM models.
0 Updated Mar 9, 2020
tesseract-ocr.github.io
0 Updated Feb 2, 2020
tessapi
Tesseract source code and API documentation
0 Updated Jan 30, 2020
tessdata_contrib
User contributed (non google) data repository
0 Updated Jan 30, 2020
Various documents related to Tesseract OCR
0 Updated Jan 30, 2020
langdata
Source training data for Tesseract for lots of languages
8 Updated Nov 22, 2019
tessdata_fast
Fast integer versions of trained LSTM models
0 Updated Oct 30, 2019
tessconfigs
Tesseract Config files
0 Updated Oct 23, 2019
Repository for tesseract testing
0 Updated Jul 9, 2019
Top languages
Most used topics
People
This organization has no public members. You must be a member to see who’s a part of this organization.
You can’t perform that action at this time.
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session.