Руководство по Selenium: Web Scraping с Selenium и Python

Представьте, какие возможности откроются перед вами, если вы автоматизируете всю нудную деятельность в интернете, такую как ежедневная проверка первых результатов в Google по ключевым запросам, или загрузка кучи разных файлов с разных сайтов. В данном разделе мы научимся пользоваться Selenium вместе с Python. Selenium – это инструмент для веб скрейпинга, имитирующий деятельность пользователя в интернете. К примеру, вы можете использовать Selenium для автоматических запросов в Google и чтения результатов, или заходить в ваши аккаунты в социальных сетях, имитировать пользователя для теста ваших веб приложений. А также многое другое, что вам нужно постоянно делать в интернете. Возможности безграничны!
Важно : Каждый код в этом разделе был протестирован на Python 2.7 и Python 3.4.
Установка и использование Selenium
Selenium – это пакет Python который может быть установлен при помощи pip. Рекомендую установить его в виртуальной среде (используя virtualenv и virtualenvwrapper).
Чтобы установить Selenium, вам нужно ввести следующее:
В этом разделе мы инициализируем драйвер Firefox, вы можете установить его, скачав исходники geckodriver. Если вы хотите работать в Chrome или IE, вы найдете всю нужную информацию у них на github.
Установка geckodriver драйвер для Firefox
для начинающих этот момент может быть первой проблемой, вроде как Selenium установлен но вот примеры из интернета не работают. Проблема заключается в отсутствии драйверов.
Первым делом скачиваем исходники драйвера geckodriver в моем случае это «geckodriver-v0.15.0-linux64.tar.gz» у меня Ubuntu.
Более подробно про установку можно прочитать на английском сайте документации. Там и список всех доступных драйверов под разные браузеры.
Начнем работу!
После установки Selenium и Firefox(geckodriver), создайте файл Python под названием selenium_script.py. Теперь приступаем к инициализации браузера при помощи Selenium:
Таким образом, код инициализировал браузер Firefox, и закрывает его спустя 5 секунд.
Что если мы перейдем в Google и поищем что-нибудь?
Web Scraping в Google при помощи Selenium
Давайте создадим скрипт, который загружает главную страницу Google, и создает запрос «Selenium»:
Что есть в данном коде:
1. Функция init_driver инициализирует экземпляр драйвера;
— Создает экземпляр драйвера;
— Добавляет функцию WebDriverWait в качестве атрибута драйвера, так что доступ к нему станет намного проще. Эта функция используется для того, чтобы дать драйверу подождать 5 секунд, перед следующим действием;
2. Функция lookup берет два аргумента: драйвер и запрос (строка);
— Это открывает поисковую страницу Google;
— Затем ждет, пока будет найден элемент окна запроса, а также кнопку для нажатия. Обратите внимание на то, что мы используем функцию WebDriverWait именно для того, чтобы дождаться появления этих элементов;
— Оба элементы были обнаружены по наименованию. Другими вариантами их поиска были бы ID, XPATH, TAG_NAME, CLASS_NAME, CSS_SELECTOR.
— Далее, запрос отправляется в элемент окна запроса, после чего кнопка поиска нажимается;
— Если окно запроса или кнопка небыли найдены, в пределах наших пяти секунд, возникает TimeoutException ;
3. Следующий оператор является условным выражением, которое истинно только тогда, когда скрипт запускается напрямую. Это предотвращает запуск следующих операторов при импорте этого файла;
— Далее драйвер инициализируется и запускается функция lookup, которая будет искать в Google слово «Selenium«;
— Ожидаем 5 секунд, чтобы увидеть результат, после чего мы выходим из драйвера.
И наконец, запустите свой код с:
Сработало? Если у вас появилась ошибка ElementNotVisibleException , читайте далее.
Как выявить ElementNotVisibleException
Недавно был изменен поиск Google, поэтому вначале Google показывает эту страницу:
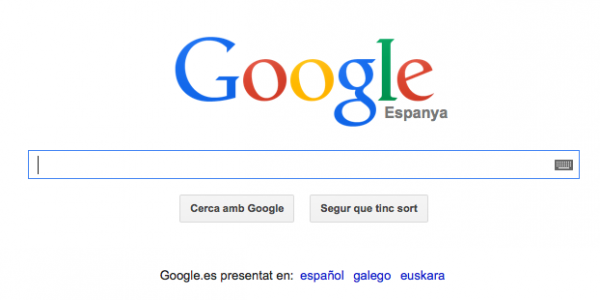
И после того, как вы начали вводить свой запрос, кнопка запроса смещается в верхнюю часть окна:
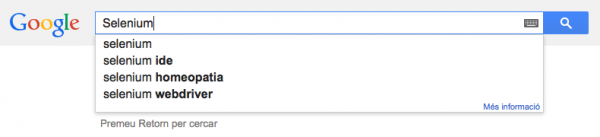
Что ж, на самом деле она не двигается. Старая кнопка стала невидимой, а новая все еще видна (по этой причине и возникает ошибка, когда вы нажимаете на старую кнопку: она невидима!). Мы можем обновить функцию lookup в нашем коде, чтобы выявить ошибку:
Элемент button.click(), который и вызывал ошибку, находится внутри оператора try. Если ошибка возникла, мы взглянем на следующую кнопку, при помощи visibility_of_element_located, чтобы убедиться в том, что нужный нам элемент видим, после чего нажимаем на кнопку. Если в какой-либо момент, какой-либо элемент не будет найден в течение 5 секунд, ошибка TimeoutException возникнет и будет выявлена двумя последними строками кода. Обратите внимание на то, что название кнопки “btn K ” , а название новой кнопки — “btn G ”.
Финальный вид кода
Демонстрируя возможные ошибки в работе, мы исправляли код по ходу работы. Если у вас возникли ошибки при выполнении наших советов то вот вам окончательный вид нашего примера. Если и этот код не работает, то пишите в комментариях — разберемся.
Список методов в Selenium
Подводя итоги, я создал таблицу с основными методами, которые нам потребуются:
Внимание : это не файл Python, не пытайтесь запустить или импортировать его! Спасибо за внимание, надеюсь, эта статья вам очень помогла.
Python: Selenium WebDriver
Всем привет, сегодня я вам расскажу как использовать Selenium в python для парсинга страниц.
Selenium WebDriver – это программная библиотека для управления браузерами. WebDriver представляет собой драйверы для различных браузеров и клиентские библиотеки на разных языках программирования, предназначенные для управления этими драйверами.
По сути своей программа с использованием Selenium это бот который выполняет всю ручную работу с браузером автоматически.
Иногда могут возникать проблемы с работой на некоторых браузерах ( зачастую на Windows, машины на базах Mac OS имеют меньшие проблемы)
Приступим, для начала установим нужные нам библиотеки Selenium , выполнив команду в консоли:
Дальше нам нужно скачать web driver для нужного нам браузера (у меня лично на Windows очень хорошо работал firefox, для использования на Mac OS вы можете использовать Safari его web driver установлен вместе с Safari и находится /usr/bin/safaridriver). Зачастую на Windows если вы используете Firefox вам потребуется в папку с проектом добавить geckodriver.log это файл обычно загружается вместе с драйвером. Скачав нужные нам файлы поместим их для удобства в папку где будет находится наш скрипт.
Приступим к написанию самого скрипта. Будем парсить картинки из яндекса, благодаря использования selenium мы будем полностью эмулировать действия пользователя, следовательно нас не заблочат, и мы сможем безнаказанно загружать картинки.
1 — Импортируем selenium, os и time.
from selenium import webdriver
2 — Добавим путь до geckodriver. Я использую библиотеку os, но вы можете указать путь любым удобным для вас способом.
gecko = os.path.normpath(os.path.join(os.path.dirname(__file__), ‘geckodriver’))
3 — Добавим путь до используемого браузера.
binary = FirefoxBinary(r’C:\Program Files\Mozilla Firefox\firefox.exe’)
4 — Инициализируем экземпляр драйвера, передадим в него путь до загруженного нами драйвера и до браузера. Еще есть необязательный параметр, options в котором можно указать тип запуска драйвера т.е. при старте скрипта браузер не будет открываться.
driver = webdriver.Firefox(firefox_binary=binary, executable_path=gecko+’.exe’)
5 — Передадим в метод get ссылку на нужную нам страницу, в нашем случае это яндекс картинки и добавим небольшую задержку в 2 секунды чтобы страница прогрузилась.
6 — Для поиска по странице в selenium есть несколько методов подробнее про каждый метод вы можете прочитать в официальной документации selenium. Мы будем искать окно поиска, оно имеет класс input__control для поиска по классам будем использовать find_element_by_class_name для строки поиска.
7 — Далее нам нужно ввести какой то текст для поиска картинки. Для этого понадобится импортировать еще один метод, который будет нажимать в нашем случае клавишу Enter
from selenium.webdriver.common.keys import Keys
8 — Введем текст и выполним поиск нажав на Enter
9 — Получим ссылки на картинки которые показал нам поиск. Используем также поиск по классам но уже найдем все классы а не один класс как использовали выше.
10 — Теперь в images мы имеем данные всех тегов которые загружены на странице, теперь остается получить из них ссылки на файлы и загрузить их. Загружать будем с помощью отправки запросов по полученной ссылке и сохранение полученных данных в фал. Импортируем библиотеку request. Воспользуемся циклом, после загрузки каждого изображения добавим таймаут.
Добавим в конц скрипта метод для закрытия браузера.
Запустим наш скрипт.
После запуска мы увидим как откроется браузер, откроется страница яндекс картинок, в окне поиска введется текст «кошка» и произойдёт поиск похожих картинок далее из каждой загруженной картинки мы получим ссылку и сделаем get запрос а полученный результат сохраним в файл рядом со скриптом.
Автоматизация тестирования. Установка и настройка Selenium server и Selenium WebDriver на Ubuntu 16.04 LTS
В одном из наших проектов нам понадобилось организовать автоматическое тестирование воспроизведения видео в плеере в разных браузерах. Сегодня я расскажу, как мы это все настроили.
Selenium server и Selenium WebDriver
Для автоматизированного тестирования было принято решение использовать свободно распространяемое ПО Selenium server и Selenium WebDriver. Если вы не знакомы с этими программами я предлагаю сначала прочитать вот эту статью на Хабре.
У нас же стояла следующая задача. Нужно с помощью скрипта запускать на виртуальной машине с ОС Ubuntu 16.04 разные браузеры, в которых будет отрываться заданная веб страница (с видеотрансляцией с Wowza сервера). В будущем мы будем использовать созданные скрипты запуска автоматических тестов также и для проведения тестирования в облачных сервисах, например, в таких как www.browserstack.com или saucelabs.com
Установка и настройка Selenium
Заходим в терминал Linux и вводим следующие команды:
sudo apt-get update #обновляем список пакетов в системе
sudo apt-get install nodejs #устанавливаем nodejs
sudo apt-get install npm #устанавливаем nmp
sudo ln -s /usr/bin/nodejs /usr/bin/node #создаем ссылку
sudo npm install selenium-webdriver #устанавливаем Webdriver
sudo npm install yargs
sudo apt-get install default-jre #устанавливаем Java
sudo npm install selenium-standalone@latest -g
sudo selenium-standalone install #устанавливаем Selenium server
sudo selenium-standalone start #запускаем Selenium server
Установка браузера Google Chrome
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo apt-get -f install
sudo dpkg -i google-chrome-stable_current_amd64.deb
Скрипт автоматического тестирования
Скрипт для запуска тестирования я сделал на JavaScript. Ниже представляю код.
var webdriver = require(‘selenium-webdriver’);
// Input capabilities
var capabilities = <
‘browserName’ : ‘chrome’,
>
var driver = new webdriver.Builder().
usingServer(‘http://localhost:4444/wd/hub’).
withCapabilities(capabilities).
build();
driver.get(‘http://www.google.com’);
driver.findElement(webdriver.By.name(‘q’)).sendKeys(‘video testing’);
driver.findElement(webdriver.By.name(‘btnG’)).click();
driver.getTitle().then(function(title) <
console.log(title);
>);
После запуска (команда nodejs myautotest.js), данный скрипт открывает Интернет браузер Google Chrome вводит в поисковой строке video testing. После того как поисковой запрос будет выполнен окно браузера будет закрыто.
В данной статье я привел этот простой вариант запуска автоматического теста. Если вам нужно настроить что-то более сложное обращайтесь ко мне и нашей команде, всегда рады помочь!
Всего хорошего!
Если у вас появились какие-то вопросы по медиа-серверам, пишите нам. Если вам нужно что-то настроить или получить консультацию по медиа-серверам и системам видео-вещания, также можете обращаться ко мне и нашей команде. Разную полезную информацию на данную тему вы можете найти в нашем Справочнике по видеотрансляциям.