Урок 12
Представление нечисловой информации в компьютере
 |  |  |
|
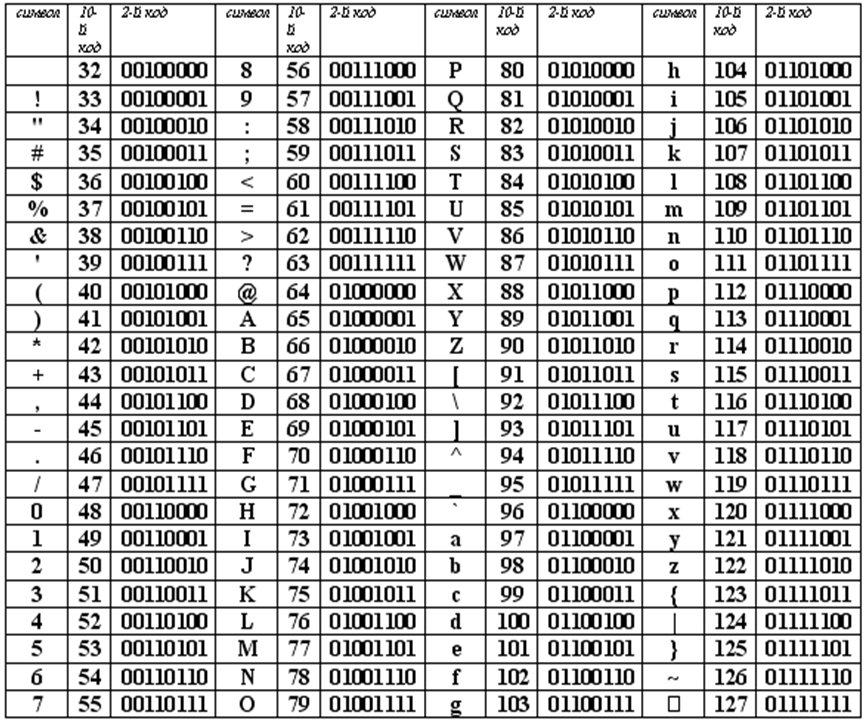
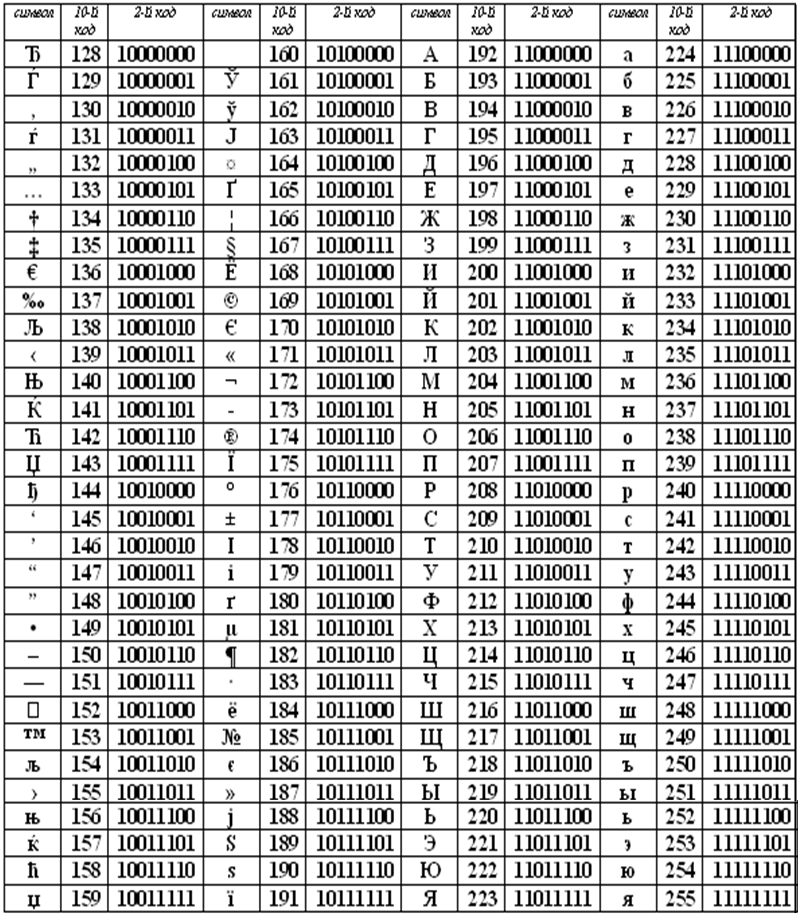
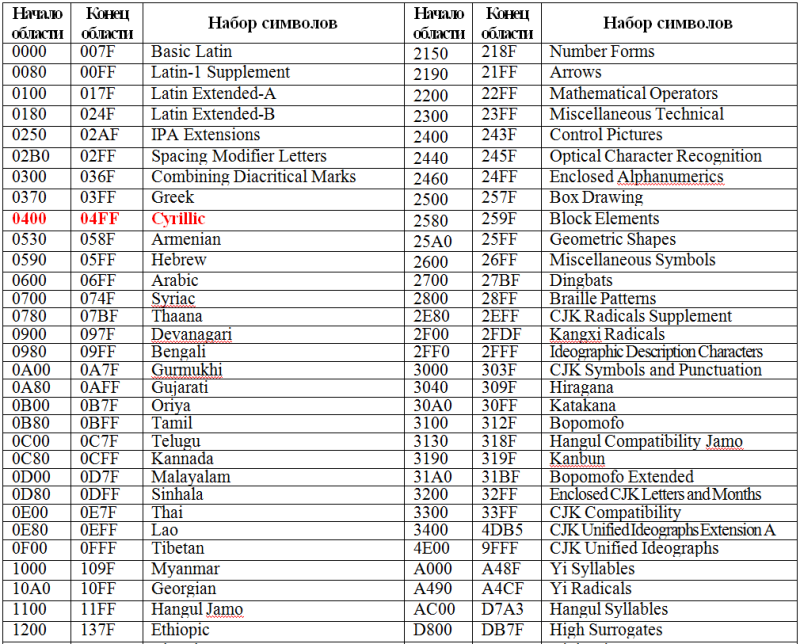
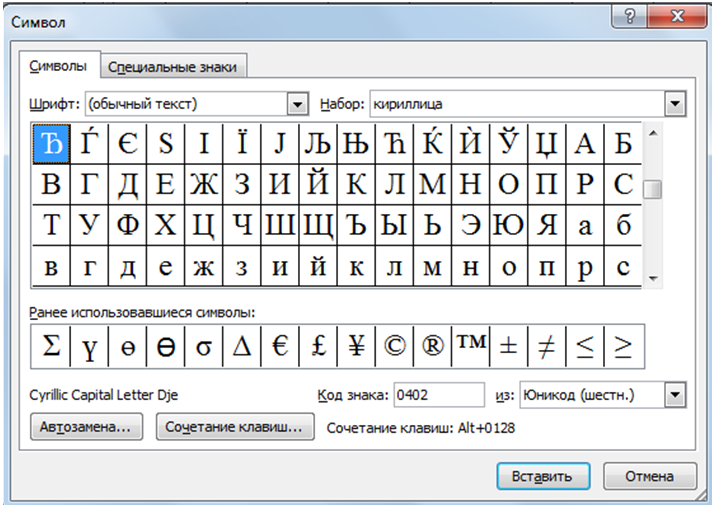
Представление текстовой информации в компьютереИзучив эту тему, вы узнаете и повторите: — как в компьютере представляется текстовая информация; Компьютеры не с самого рождения могли обрабатывать символьную информацию. Лишь с конца 60-х годов они стали использоваться для обработки текстов и в настоящее время большинство пользователей ПК занимаются вводом, редактированием и форматированием текстовой информации. 1. Таблица кодирования ASCII.А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация. Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью. Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 2 в 8 степени равно 256. 8 битов = 1 байт, следовательно: Один символ в компьютерном тексте занимает 1 байт памяти. Как мы выяснили, традиционно для кодирования одного символа используется 8 бит. И, когда люди определились с количеством бит, им осталось договориться о том, каким кодом кодировать тот или иной символ, чтобы не получилось путаницы, т.е. необходимо было выработать стандарт – все коды символов сохранить в специальной таблице кодов. В первые годы развития вычислительной техники таких стандартов не существовало, а сейчас наоборот, их стало очень много, но они противоречивы. Первыми решили эти проблемы в США, в институте стандартизации. Этот институт ввел в действие таблицу кодов ASCII (AmericanStandardCodeforInformationInterchange – стандартный код информационного обмена США). Рассмотрим таблицу кодов ASCII. Пояснение: раздать учащимся распечатанную таблицу кодов ASCII. Таблица ASCII разделена на две части. Первая – стандартная – содержит коды от 0 до 127. Вторая – расширенная – содержит символы с кодами от 128 до 255. Первые 32 кода отданы производителям аппаратных средств и называются они управляющие, т.к. эти коды управляют выводом данных. Им не соответствуют никакие символы. Коды с 32 по 127 соответствуют символам английского алфавита, знакам препинания, цифрам, арифметическим действиям и некоторым вспомогательным символам. Коды расширенной части таблицы ASCII отданы под символы национальных алфавитов, символы псевдографики и научные символы. Стандартная часть таблицы кодов ASCII Если вы внимательно посмотрите на обе части таблицы, то увидите, что все буквы расположены в них по алфавиту, а цифры – по возрастанию. Этот принцип последовательного кодирования позволяет определить код символа, не заглядывая в таблицу. Коды цифр берутся из этой таблицы только при вводе и выводе и если они используются в тексте. Если же они участвуют в вычислениях, то переводятся в двоичную систему счисления. Коды национального (русского) алфавита расширенной частитаблицы ASCII Альтернативные системы кодирования кириллицы.Тексты, созданные в одной кодировке, не будут правильно отображаться в другой.В настоящее время для поддержки букв русского алфавита (кириллицы) существует несколько кодовых таблиц (кодировок), которые используются различными операционными системами, что является существенным недостатком и в ряде случаев при-водит к проблемам, связанным с операциями декодирования числовых значений символов. Для разных типов ЭВМ используются различные кодировки: В настоящее время существует 5 кодовых таблиц для русских букв: Windows (СР(кодовая страница)1251), MS – DOS (СР(кодовая страница)866), KOИ – 8 (Код обмена информацией, 8-битный) (используется в OS UNIX), Mac (Macintosh), ISO (OS UNIX). Одним из первых стандартов кодирования кириллицы на компьютерах был стан-дарт КОИ-8. Национальная часть кодовой таблицы стандарта КОИ8-Р В настоящее время применяется и кодовая таблица, размещенная на странице СР866 стандарта кодирования текстовой информации, которая используется в операционной системе MS DOS или сеансе работы MS DOS для кодирования кириллицы. Национальная часть кодовой таблицы СР866 В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица, размещенная на странице СР1251 соответствующего стандарта, которая используется в операционных системах семейства Windows фирмы Microsoft. Национальная часть кодовой таблицы СР1251 Во всех представленных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит). В мире существует примерно 6800 различных языков. Если прочитать текст, напечатанный в Японии на компьютере в России или США, то понять его будет нельзя. Чтобы буквы любой страны можно было читать на любом компьютере, для их кодировки стали использовать 2 байта (16 бит). Основополагающая таблица использования кодового пространства Unicode Использование Unicode значительно упрощает создание многоязычных документов, публикаций и программных приложений. Рассмотрим примеры. 1) Представьте в форме шестнадцатеричного кода слово «ЭВМ» во всех пяти кодировках. Воспользуемся компьютерным калькулятором для перевода чисел из десятичной в шестнадцатеричную систему счисления. Последовательности десятичных кодов слова «ЭВМ» в различных кодировках составляем на основе кодировочных таблиц: Переводим с помощью калькулятора последовательности кодов из десятичной системы в шестнадцатеричную: 2) Определить числовой код символа в кодировке Unicode с помощью тексто-вого редактора MicrosoftWord. 1. В операционной системе Windows запустить текстовый редактор MicrosoftWord. 2. В текстовом редакторе MicrosoftWord ввести команду [Вставка-Символ…]. На экране появится диалоговое окно Символ. Центральную часть диалогового окна занимает фрагмент таблицы символов. 3. Для определения числового кола знака кириллицы с помощью раскрывающегося списка Набор: выбрать пункт кириллица. 4. Для определения шестнадцатеричного числового кода символа в кодировке Unicode с помощью раскрывающегося списка из: выбрать тип кодировки Юникод (шестн.). 5. В таблице символов выбрать символ Э. В текстовом поле кодзнака : появится его шестнадцатеричный числовой код (в данном случае 042D). Решите задачи:№1. Закодируйте с помощью таблицы ASCII слова: А) Excel; Б) Access; В) Windows; Г) ИНФОРМАЦИЯ. №2. Буква «i» в таблице кодов имеет код 105. Не пользуясь таблицей, расшифруйте следующую последовательность кодов: 102, 105, 108, 101. №3. Десятичный код буквы «е» в таблице ASCII равен 101. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову help. №4. Десятичный код буквы «i» в таблице ASCII равен 105. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову link. №5. Декодируйте следующие тексты, заданные десятичным кодом: №6. Во сколько раз увеличится информационный объем страницы текста при его преобразовании из кодировки Windows 1251 (таблица кодировки содержит 256 символов) в кодировку Unicode (таблица кодировки содержит 65536 символов)? №7. Каков информационный объем текста, содержащего слово ПРОГРАММИРОВАНИЕ: №8. Текст занимает ¼ Кбайта. Какое количество символов он содержит? №9. Текст занимает полных 6 страниц. На каждой странице размещается 30 строк по 80 символов. Определить объем оперативной памяти, который займет этот текст. №10. Свободный объем оперативной памяти компьютера 320 Кбайт. Сколько страниц книги поместится в ней, если на странице: №11. Текст занимает 20 секторов на двусторонней дискете объемом 360 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст? Очень срочнооо)))))хДответьте пожалуста на вопросы)))только полным ответом..очень нужно)))) 2) С какой целью ввели кодировку Unicode, которая позволяет закодировать 65 536 различных символов. Очень срочно. задали сделать а я не знаюю)))))подскажите. только полным ответом))))) 1 Почему при кодировании текстовой информации в компьютере в большинстве кодировок используется 256 различных символов, хотя русский алфавит включает только 33 буквы? 2 С какой целью ввели кодировку Unicode, которая позволяет закодировать 65 536 различных символов? 1. Букв 33, но с учётом загланых и строчных уже 66, плюс знаки препинания, пробелы, плюс, минус, равно, тире, скобки, маркеры для списков и т. д. 2. Кодировка Unicod введена с целью поддержки большего колическва символов. Например для китайского языка она просто необходима. 1) Когда компьютеры были большими, они оперировали байтами — 8 бит, 256 комбинаций. Удобно: 1 байт — 1 символ. Первый 128 отводились под буквы английского алфавита, цифры, знаки препинания и пр. Вторые 128 — под служебную информацию. Сейчас во вторых 128 символах размещают, как правило, буквы национальных алфавитов. Поэтому существуют «русифицированные» шрифты. Такой набор из 256 символов называется кодовой таблицей. 2) Чтобы решить многие проблемы с кодировкой ввели кодовую таблицу Unicode, в которой под символ отведено уже 2 байта, и одна таблица содержит в себе все символы почти всех национальных алфавитов в строго определенной комбинации. Таким образом документ в Unicode будет везде читаться одинаково. Решение задач на тему «Кодирование текстовой информации»
Решение задач на тему «Кодирование текстовой информации» 1. Объем памяти, занимаемый текстом. 2. Кодирование (декодирование) текстовой информации. 3. Внутреннее представление текста в компьютере. 1. Объем памяти, занимаемый текстом. В задачах такого типа используются понятия: · единицы измерения информации (бит, байт и др.) Для представления текстовой (символьной) информации в компьютере используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации (28 =256). 8 бит =1 байту, следовательно, двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти. 1. Сколько бит памяти займет слово «Микропроцессор»?([1], c.131, пример 1) Слово состоит из 14 букв. Каждая буква – символ компьютерного алфавита, занимает 1 байт памяти. Слово занимает 14 байт =14*8=112 бит памяти. 2. Текст занимает 0, 25 Кбайт памяти компьютера. Сколько символов содержит этот текст? ([1], c.133, №31) Переведем Кб в байты: 0, 25 Кб * 1024 =256 байт. Так как текст занимает объем 256 байт, а каждый символ – 1 байт, то в тексте 256 символов. Ответ: 256 символов 3. Текст занимает полных 5 страниц. На каждой странице размещается 30 строк по 70 символов в строке. Какой объем оперативной памяти (в байтах) займет этот текст? ([1], c.133, №32) 30*70*5 = 10500 символов в тексте на 5 страницах. Текст займет 10500 байт оперативной памяти. 4. Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения из пушкинского четверостишия: Певец-Давид был ростом мал, Но повалил же Голиафа! (ЕГЭ_2005. демо, уровень А) В тексте 50 символов, включая пробелы и знаки препинания. При кодировании каждого символа одним байтом на символ будет приходиться по 8 бит, Следовательно, переведем в биты 50*8= 400 бит. 5. Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения в кодировке КОИ-8: Сегодня метеорологи предсказывали дождь. (ЕГЭ_2005, уровень А) В таблице КОИ-8 каждый символ закодирован с помощью 8 бит. См. решение задачи №4. Ответ: 320 бит6. Считая, что каждый символ кодируется 16 битами, оцените информационный объем следующего предложения в кодировке Unicode: Каждый символ кодируется 8 битами. 34 символа в предложении. Переведем в биты: 34*16=544 бита. Ответ: 544 бит7. Каждый символ закодирован двухбайтным словом. Оцените информационный объем следующего предложения в этой кодировке: В одном килограмме 100 грамм. 19 символов в предложении. 19*2 =38 байт Ответ: 38 байт8. Текст занимает полных 10 секторов на односторонней дискете объемом 180 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст? ([1], c.133, №34) 40*9 = 360 — секторов на дискете. 180 Кбайт : 360 * 10 =5 Кбайт – поместится на одном секторе. 5*1024= 5120 символов содержит текст. Ответ: 5120 символов 9. Сообщение передано в семибитном коде. Каков его информационный объем в байтах, если известно, что передано 2000 символов. Если код символа содержит 7 бит, а всего 2000 символов, узнаем сколько бит займет все сообщение. 2000 х 7=14000 бит. Переведем результат в байты. 14000 : 8 =1750 байт 10. Сколько секунд потребуется модему, передающему сообщение со скоростью 28800 бит/с, чтобы передать 100 страниц текста в 30 строк по 60 символов каждая, при условии, что каждый символ кодируется одним байтом? (ЕГЭ_2005, уровень В) Найдем объем сообщения. 30*60*8*100 =1440000 бит. Найдем время передачи сообщения модемом. 1440000 : 28800 =50 секунд 11. Сколько секунд потребуется модему, передающему сообщения со скоростью 14400 бит/с, чтобы передать сообщение длиной 225 Кбайт? (ЕГЭ_2005, уровень В) Переведем 225 Кб в биты.225 Кб *1024*8 = 1843200 бит. Найдем время передачи сообщения модемом. 1843200: 14400 =128 секунд. 2. Кодирование (декодирование) текстовой информации. В задачах такого типа используются понятия: Кодирование – отображение дискретного (прерывного, импульсного) сообщения в виде определенных сочетаний символов. Код (от французского слова code – кодекс, свод законов) – правило по которому выполняется кодирование. Кодовая таблица (или кодовая страница) – таблица, устанавливающая соответствие между символами алфавита и двоичными числами. Примеры кодовых таблиц (имеются на CD диске к учебнику Н. Угринович): · КОИ-7, КОИ-8 – кодирование русских букв и символов (семи-, восьми — битное кодирование)
1) #154 неразрывный пробел. Рис.1 Кодировка КОИ8-Р · ASCII –American Standard Code for Information Interchange (американский стандарт кодов для обмена информацией) – это восьмиразрядная кодовая таблица, в ней закодировано 256 символов (127- стандартные коды символов английского языка, спецсимволы, цифры, а коды от 128 до 255 – национальный стандарт, алфавит языка, символы псевдографики, научные символы, коды от 0 до 32 отведены не символам, а функциональным клавишам).
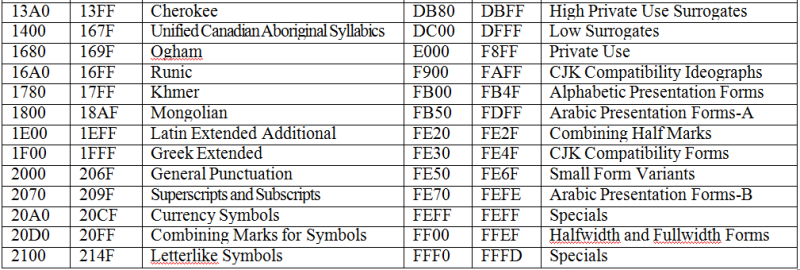
Рис. 2 Международная кодировка ASCII · Unicode – стандарт, согласно которому для представления каждого символа используется 2 байта. (можно кодировать математические символы, русские, английские, греческие, и даже китайские). C его помощью можно закодировать не 256, а 65536 различных символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов · СР1251 — наиболее распространенной в настоящее время является кодировка Microsoft Windows, («CP» означает «Code Page», «кодовая страница»). |