Системи кодування ASCII, Windows 1251, Unicode та інші. Кодування символьної інформації
При введенні в комп’ютер символьної інформації символи (літери, цифри, знаки), що вводяться, кодуються певними комбінаціями нулів і одиниць, а при виведенні їх для читання людиною (на монітор або принтер) за кодом символу будується зображення символу.
Кожному символу призначається код — послідовність з фіксованої кількості нулів і одиниць зі взаємно однозначною відповідністю. Використовуючи одну двійкову цифру (один біт) можна закодувати всього 2 символи. Двохбітових комбінацій може бути чотири→00; 01, 10, 11, тобто 2 2 , за допомогою трьох бітів можна одержати вісім різних комбінацій нулів і одиниць (2 3 ). Оптимальна кількість символів, які використовуються при наборі різних текстів, дорівнює приблизно 250 (літери латинські і кирилиця, заголовочні і рядкові, розділові знаки, цифри, математичні знаки, елементи псевдографіки). В двійковій системі така кількість символів може бути закодована послідовністю з 8 біт (2 8 =256), тобто одним байтом. Якщо кожному символу алфавіту поставити у відповідність певне ціле число, то за допомогою двійкового коду можна однозначно кодувати текстову інформацію. Вісім двійкових розрядів достатні для кодування 256 різних символів. Цього вистачить, щоб зобразити різними комбінаціями восьми бітів всі символи англійської, української і російської мов, як рядкові, так і прописні, а також розділові знаки, символи основних арифметичних дій і загальноприйняті спеціальні символи.
Для того, щоб весь світ однаково кодував текстові дані, потрібні єдині таблиці кодування. Для англійської мови, що захопила де-факто нішу міжнародного засобу спілкування Інститут стандартизації США (ANSI — American National Standard Institute) ввів в дію систему кодування ASCII (American Standard Code for Information Interchange — стандартний код інформаційного обміну США). В системі ASCII закріплено дві таблиці кодування — базова і розширена. Базова таблиця закріплює значення кодів від 0 до 127, а розширена відноситься до символів з номерами від 128 до 255. Перші 32 коди базової таблиці, починаючи з нульового, віддано виробникам апаратних засобів (в першу чергу виробникам комп’ютерів і друкуючих пристроїв). В цій області розміщуються так звані управляючі коди, яким не відповідають ніякі символи мов, і, відповідно, ці коди не виводяться ні на екран, ні на пристрої друку, але ними можна управляти тим, як проводиться виведення інших даних. Починаючи з коду 32 і закінчуючи кодом 127 розміщені коди символів англійського алфавіту, розділових знаків, цифр, символів арифметичних дій і деяких допоміжних символів. Базова таблиця кодування ASCII наведена в таблиці 2.
Підтримка виробників устаткування і програм вивела американський код ASCII на рівень міжнародного стандарту, і національним системам кодування довелося «відступити» в другу, розширену частину системи кодування, що визначає значення кодів з 128 по 255. Відсутність єдиного стандарту в цій області привела до множинності одночасно діючих кодувань. Тільки в Росії можна вказати три діючі стандарти кодування і ще два застарілих.
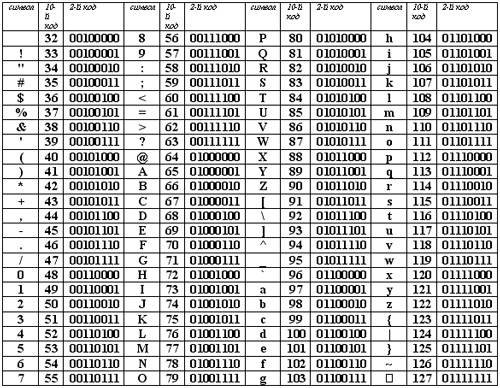
Для кодування символів російської і української мов, відоме як система кодування Windows-1251, було введено «ззовні» — компанією Microsoft, але, враховуючи широке розповсюдження операційних систем і інших продуктів цієї компанії на Україні і в Росії, вона глибоко закріпилася і знайшла широке розповсюдження (таблиця 3). Це кодування використовується на більшості комп’ютерів, що працюють під управлінням операційних систем Windows.
Інше поширене кодування носить назву КОИ-8 (код обміну інформацією, восьмизначний) — її походження відноситься до часів дії Ради Економічної Взаємодопомоги держав Східної Європи. Сьогодні кодування КОИ-8 має значне розповсюдження в комп’ютерних мережах на території Росії і в російському секторі Інтернету.
Таблиця 2. Базова таблиця кодування ASCII
| 32 пропуск | 48 0 | 64 @ | 80 Р | 96 ‘ | 112 p |
| 33 ! | 49 1 | 65 А | 81 Q | 97 а | 113 q |
| 34 « | 50 2 | 66 B | 82 R | 98 b | 114 r |
| 35 # | 51 3 | 67 C | 83 S | 99 c | 115 s |
| 36 $ | 52 4 | 68 D | 84 Т | 100 d | 116 t |
| 37 % | 53 5 | 69 Е | 85 U | 101 e | 117 u |
| 38 & | 54 6 | 70 F | 86 V | 102 f | 118 v |
| 39 ‘ | 55 7 | 71 G | 87 W | 103 g | 119 w |
| 40 ( | 56 8 | 72 Н | 88 X | 104 h | 120 x |
| 41) | 57 9 | 73 I | 89 У | 105 i | 121 у |
| 42 * | 58 : | 74 J | 90 Z | 106 j | 122 z |
| 43 + | 59 ; | 75 K | 91 [ | 107 k | 123 < |
| 44 , | 60 | 78 N | 94 ^ | 110 n | 126 |
| 47 / | 63 ? | 79 О | 95 _ | 111 0 | 127 |
Таблиця 3. Кодування Windows 1251
Кодировки UTF-8 и Windows 1251 — просто о сложном

Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
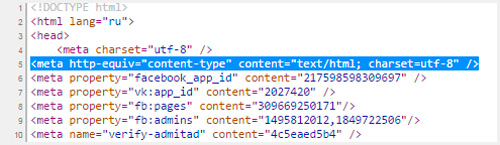
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
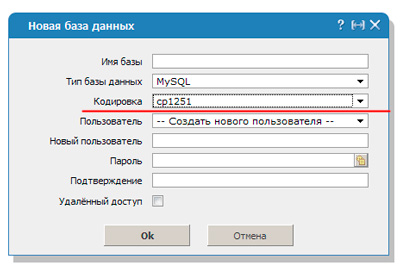
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.
Таблицы кодировок ASCII, CP1251 (windows1251), ISO-8859-5
Таблица ASCII
Таблица ASCII (American standard code for information interchange) является мировым стандартом для кодирования букв английского алфавита, популярных спец символов (! $ # % & и т.д.) и некоторых непечатных символов (например, возврат каретки 0x0D и перенос строки 0х0А).
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.
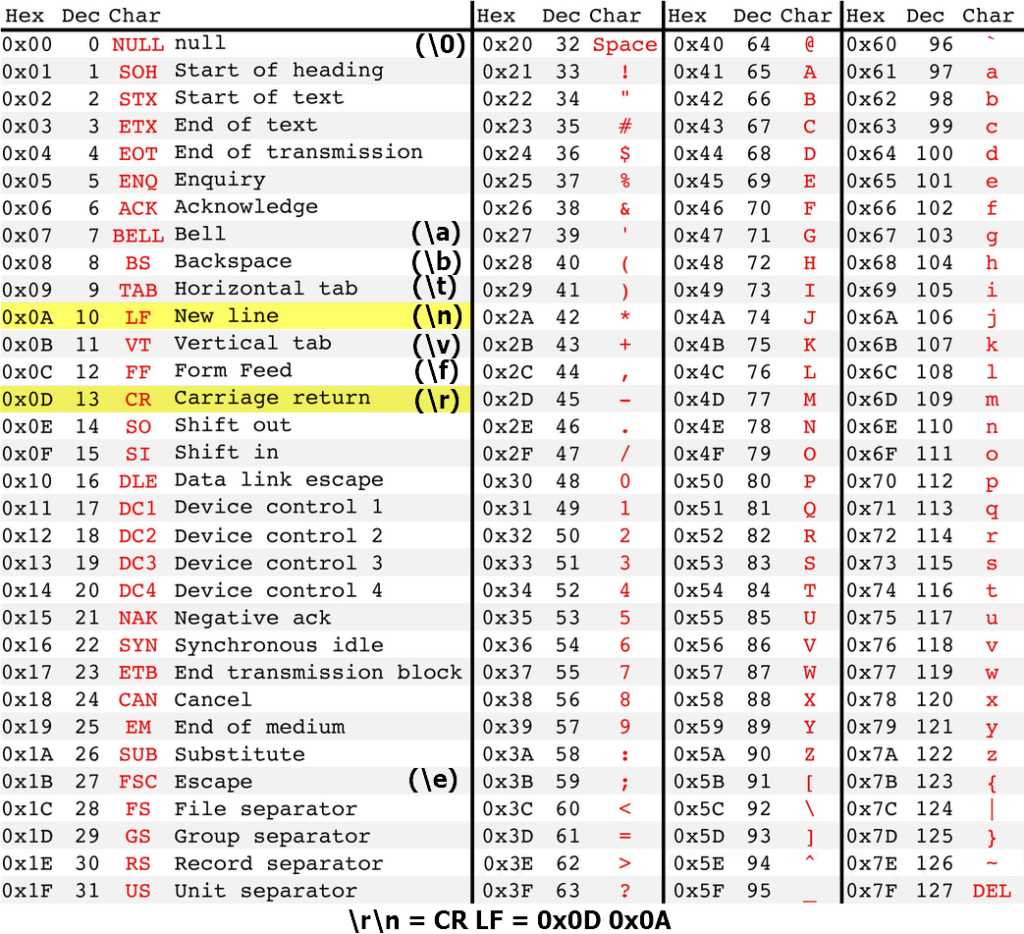
Таблица CP1251 (windows-1251)
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.
Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.

Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.
Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.